Nan (no es un número) es un valor de coma flotante que no se puede convertir en otro tipo de datos que se espera que flote. En el análisis de datos, Nan es el valor innecesario que debe eliminarse para analizar correctamente el conjunto de datos. En este artículo, discutiremos cómo eliminar/soltar columnas que tienen valores Nan en el marco de datos de pandas. Tenemos una función conocida como Pandas.DataFrame.dropna() para eliminar columnas que tienen valores Nan.
Sintaxis: DataFrame.dropna(axis=0, how=’any’, thresh=Ninguno, subconjunto=Ninguno, inplace=False)
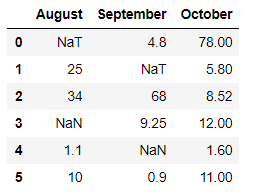
Ejemplo 1: Descartar todas las columnas con valores NaN/NaT.
Python3
# Importing libraries
import pandas as pd
import numpy as np
# Creating a dictionary
dit = {'August': [pd.NaT, 25, 34, np.nan, 1.1, 10],
'September': [4.8, pd.NaT, 68, 9.25, np.nan, 0.9],
'October': [78, 5.8, 8.52, 12, 1.6, 11], }
# Converting it to data frame
df = pd.DataFrame(data=dit)
# DataFrame
df
Producción:
Python3
# Dropping the columns having NaN/NaT values df = df.dropna(axis=1) df
Producción:
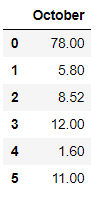
En el ejemplo anterior, descartamos las columnas ‘agosto’ y ‘septiembre’ ya que contienen valores Nan y NaT.
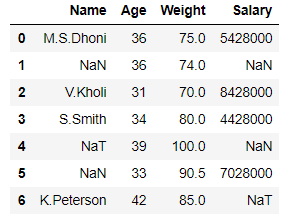
Ejemplo 2: descartar todas las columnas con cualquier valor NaN/NaT y luego restablecer los índices usando la función df.reset_index() .
Python3
# Importing libraries import pandas as pd import numpy as np # Initializing the nested list with Data set player_list = [['M.S.Dhoni', 36, 75, 5428000], [np.nan, 36, 74, np.nan], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], [pd.NaT, 39, 100, np.nan], [np.nan, 33, 90.5, 7028000], ['K.Peterson', 42, 85, pd.NaT]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary']) df
Producción:
Python3
# Dropping the columns having NaN/NaT values df = df.dropna(axis=1) # Resetting the indices using df.reset_index() df = df.reset_index(drop=True) df
Producción:
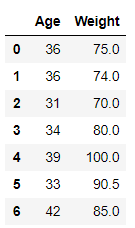
En el ejemplo anterior, eliminamos las columnas ‘Nombre’ y ‘Salario’ y luego reiniciamos los índices.
Ejemplo 3:
Python3
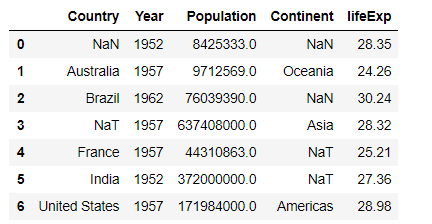
# Importing libraries import pandas as pd import numpy as np # creating and initializing a nested list age_list = [[np.nan, 1952, 8425333, np.nan, 28.35], ['Australia', 1957, 9712569, 'Oceania', 24.26], ['Brazil', 1962, 76039390, np.nan, 30.24], [pd.NaT, 1957, 637408000, 'Asia', 28.32], ['France', 1957, 44310863, pd.NaT, 25.21], ['India', 1952, 3.72e+08, pd.NaT, 27.36], ['United States', 1957, 171984000, 'Americas', 28.98]] # creating a pandas dataframe df = pd.DataFrame(age_list, columns=[ 'Country', 'Year', 'Population', 'Continent', 'lifeExp']) df
Producción:
Python3
# Dropping the columns having NaN/NaT values df = df.dropna(axis=1) # Resetting the indices using df.reset_index() df = df.reset_index(drop=True) df
Producción:
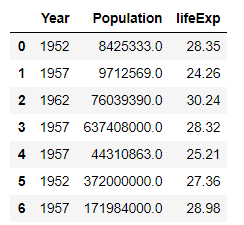
En el ejemplo anterior, quitamos las columnas ‘País’ y ‘Continente’ ya que contienen valores Nan y NaT.
Ejemplo 4: Descartar todas las columnas con cualquier valor NaN/NaT bajo un índice de etiqueta determinado usando el atributo ‘ subconjunto ‘.
Python3
# Importing libraries
import pandas as pd
import numpy as np
# Creating a dictionary
dit = {'August': [10, np.nan, 34, 4.85, 71.2, 1.1],
'September': [np.nan, 54, 68, 9.25, pd.NaT, 0.9],
'October': [np.nan, 5.8, 8.52, np.nan, 1.6, 11],
'November': [pd.NaT, 5.8, 50, 8.9, 77, pd.NaT] }
# Converting it to data frame
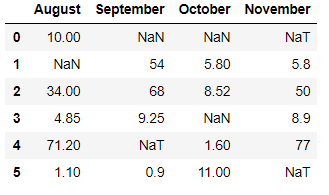
df = pd.DataFrame(data=dit)
# data frame
df
Producción:
Python3
# Dropping the columns having NaN/NaT values # under certain label index using 'subset' attribute df = df.dropna(subset=[3], axis=1) # Resetting the indices using df.reset_index() df = df.reset_index(drop=True) df
Producción:
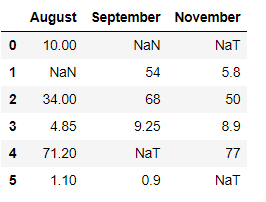
En el ejemplo anterior, eliminamos la columna que tiene el índice 3, es decir, ‘Octubre’ usando el atributo de subconjunto.
Publicación traducida automáticamente
Artículo escrito por vanshgaur14866 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA