He aquí, fans de Marvel. Los Vengadores están ahí para salvar el Multiverso, y nosotros también, listos para hacer lo que sea necesario para apoyarlos.
En este artículo, utilizaremos Deep Learning y visión artificial para la generación de subtítulos de los personajes de Avengers Endgame. Comenzaremos con lo básico, explicando conceptos y usaremos un modelo pre-entrenado para implementar el proyecto.

Una descripción general:
La generación de leyendas de imágenes es un problema desafiante en la IA que conecta la visión por computadora y la PNL, donde se debe generar una descripción textual para una fotografía determinada. En sentido general para una imagen dada como entrada, nuestro modelo describe la descripción exacta de una imagen. Requiere tanto la comprensión de la imagen del dominio de la visión por computadora que la red neuronal de convolución como un modelo de lenguaje del campo del procesamiento del lenguaje natural.
Es importante asumir y probar múltiples formas de enmarcar un problema de modelado predictivo dado y, de hecho, hay muchas formas de enmarcar el problema de generar leyendas para fotografías. nos ceñimos a uno que explicaremos al final de este artículo, así que espera un tiempo. ¿Puedes sostener Thor Hammer ? NO !! pero podrías aguantar aquí, bromas aparte.
Entonces, básicamente, lo que hace nuestro modelo es cuando pasamos una imagen a nuestra arquitectura combinada CNN y RNN, luego generará la descripción natural de la imagen usando NLP.
Mostramos un modelo generativo basado en una arquitectura neuronal Recurrente profunda que se combina con la traducción automática y que puede usarse para generar oraciones naturales que describen una imagen. El modelo está entrenado para maximizar la probabilidad de la oración de descripción objetivo dadas las imágenes de entrenamiento. Los experimentos en varios conjuntos de datos muestran la precisión del modelo y la fluidez del idioma que aprende únicamente a partir de las descripciones de imágenes.
Ejemplo: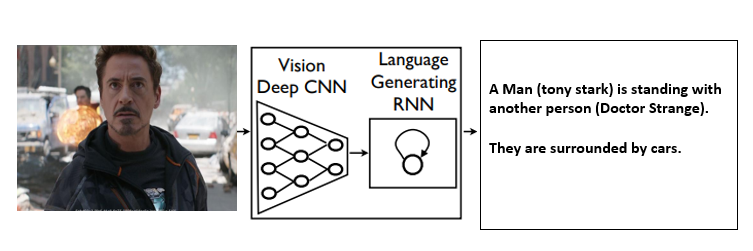
Antes de profundizar, comprendamos la terminología básica que se requiere para comprender este algoritmo.
Son básicamente dos tipos:
Modelo basado en imagen: que extrae las características de la imagen.
Modelo basado en lenguaje: Que traduce las características y objetos dados por nuestro modelo basado en imágenes a una oración natural.
El vector de características condensado se forma a partir de una red neuronal convolucional . En términos generales, este vector de características se denomina incrustación , y el modelo CNN se denomina codificador que codifica el conjunto de palabras dado y genera la secuencia que pasa a una red de decodificadores. En el siguiente paso, utilizaremos estas incrustaciones de la capa CNN como entrada a la red LSTM , un decodificador que decodifica la secuencia de entrada y genera la salida.
Por ejemplo: traducción de idiomas como francés a inglés.
En un modelo de lenguaje de oraciones , LSTM predice la siguiente palabra en una oración. Dada la incrustación inicial de la imagen, el LSTM se entrena para predecir el próximo valor más probable de la secuencia. Es como mostrarle a una persona un montón de imágenes y pedirles que recuerden los detalles de las imágenes y luego mostrarles una nueva imagen que tiene un contenido similar a las imágenes anteriores y pedirles que recuerden el contenido. Este trabajo de «recordar» y «recordar» lo realiza nuestra red LSTM, que es mucho más útil aquí. más adelante, cuando llegue a la parte de Implementación, le mostraré cómo funciona realmente.
En este artículo, utilizaremos una red neuronal de convolución previamente entrenada que se entrena en el conjunto de datos de ImageNet. Las imágenes se transforman a una resolución estándar de 224 X 224 X 3 (nh x hw x nc) que hará que la entrada del modelo sea constante para cualquier imagen dada.
Técnicamente, también insertamos Start y Stop para señalar el final de la leyenda.
Ejemplo:

Si la descripción de la imagen es «Tony Stark está de pie con Doctor Strange» , la secuencia de origen es una lista que contiene [‘ (Inicio) , ‘Tony’, ‘Stark’, ‘es’, ‘de pie’, ‘con’, ‘Doctor ‘, ‘Strange’] y la secuencia objetivo es una lista que contiene [‘Tony’, ‘Stark’, ‘is’, ‘standing’, ‘with’, ‘Doctor’, ‘Strange’, ‘ (End) ‘] . Usando estas secuencias de origen y destino y el vector de características, el decodificador LSTM se entrena como un modelo de lenguaje condicionado en el vector de características.
La imagen de abajo explica mejor –
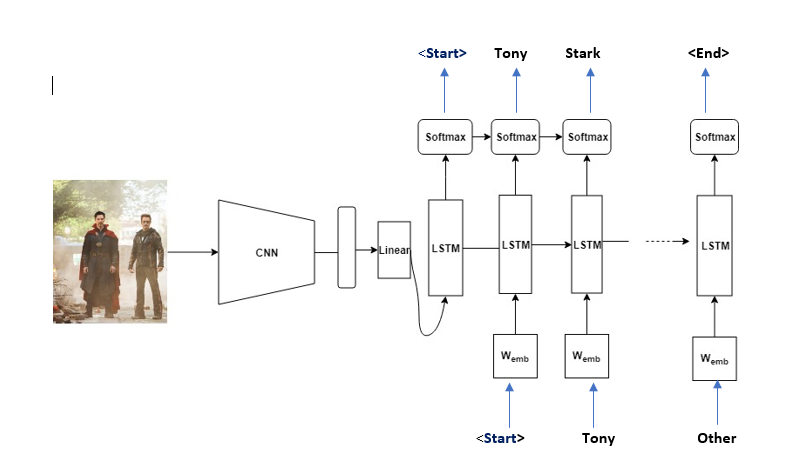
Fase de prueba:
En la fase de prueba, la parte del codificador es casi la misma que la fase de entrenamiento. La única diferencia es que la capa de normas por lotes utiliza la varianza y el promedio en lugar de estadísticas de minilotes. Esto se puede implementar fácilmente usando la función encoder.eval() . Para la parte del decodificador , hay una diferencia vital entre la fase de entrenamiento y la fase de prueba. En la fase de prueba, el decodificador LSTM no puede observar la descripción de la imagen. Para manejar esta situación, el decodificador LSTM retroalimenta la palabra generada previamente a la siguiente entrada. Esto se puede implementar usando un bucle for.
Existen básicamente dos modelos de generación de subtítulos:
modelo 1:
Genere la secuencia completa: el primer enfoque implica generar la descripción textual completa para el objeto dado una imagen.
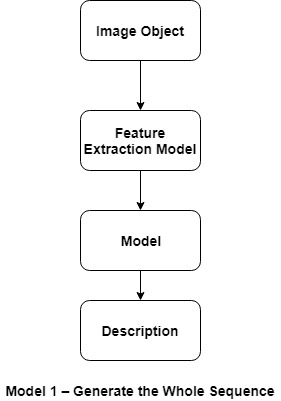
Input: Photograph Output: Complete textual description.
Este es un modelo de predicción de secuencia de uno a muchos que genera la salida completa de una sola vez.
- Este modelo pone una gran carga en el modelo de lenguaje para generar las palabras correctas en el orden correcto.
- Las imágenes pasan por un modelo de extracción de características, como un modelo previamente entrenado en el conjunto de datos de ImageNet.
- Se utiliza una codificación en caliente para la secuencia de salida que permite que el modelo prediga la distribución de probabilidad de cada palabra en la secuencia en todo el vocabulario.
- Todas las secuencias se rellenan con la misma longitud, lo que significa que el modelo se ve obligado a generar varios pasos de tiempo «sin palabras» en la secuencia de salida.
- Probando este método, descubrimos que se requiere un modelo de lenguaje muy grande e incluso entonces es difícil superar el modelo que genera el equivalente NLP de persistencia, ejemplo: generar la misma palabra repetida para toda la longitud de la secuencia como salida.
Modelo 2:
Generar palabra a partir de palabra: este es un tipo diferente de enfoque en el que el LSTM genera una predicción de una palabra dada una imagen y una palabra como entrada.
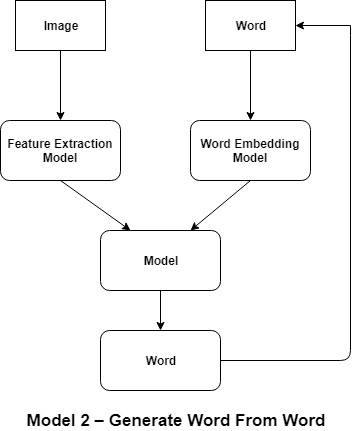
Input 1: Image Input 2: Previously generated word or start of sequence token. Output: Next word in sequence.
Este es un modelo de predicción de secuencia uno a uno que genera la descripción textual mediante llamadas recursivas al modelo.
- La entrada de una palabra es un token que indica el inicio de la secuencia en el caso de la primera vez que se llama al modelo o es la palabra que se generó desde la última vez que se llamó al modelo.
- La imagen pasa a través de un modelo de extracción de características como un modelo que está previamente entrenado en el conjunto de datos de ImageNet y la palabra de entrada está codificada en un número entero que pasa a través de una incrustación de palabras.
- La palabra de salida es una codificada en caliente que permite que el modelo prediga las probabilidades de las palabras en todo el vocabulario.
- El proceso recursivo de generación de palabras continúa repitiéndose hasta que se genera un token de fin de secuencia.
- Al probar este método, descubrimos que el modelo genera algunas secuencias de n-gramas buenas, pero queda atrapado en un bucle que repite las mismas secuencias de palabras para descripciones largas, lo que es una sobrecarga debido a que existe un problema de memoria insuficiente en el modelo. para recordar lo que se ha generado previamente.
Obtengamos una intuición más profunda a través del ejemplo de un título de imagen.
Para desarrollar un modelo de subtítulos de imágenes que desglosamos en tres partes:
1) Extraer características de la imagen para usar en el modelo.
2) Entrenar al modelo sobre aquellas características que extrajimos de la Imagen.
3) Usar el modelo entrenado para generar texto de subtítulos cuando pasamos las características de la imagen de entrada a la red.
Tenemos dos tipos diferentes de técnicas para hacer esto:
1. Red neuronal del grupo de geometría visual (VGG) para la extracción de características de la imagen.
2. Una red neuronal recurrente (RNN) para entrenar y generar texto de subtítulos a través de Model.
Paso #1:
Usando el modelo VGG pre-entrenado, la imagen se lee y se redimensiona a 224*224*3 que tiene tres canales de color, y luego se alimenta a la red neuronal VGG donde las características se extraen como una array Numpy. Dado que la red VGG se usa aquí para hacer una clasificación de imágenes, en lugar de obtener la salida de la última capa, obtenemos la salida de la capa totalmente conectada (FC-2) que contiene los datos de características de una imagen.
Paso n.º 2:
para subtitular la imagen, utilizando Keras, cree una sola celda LSTM (memoria a largo plazo a corto plazo) con 256 neuronas. Para esta celda, tenemos cuatro entradas: Características de la imagen, subtítulos, una máscara y una posición actual. Primero, la entrada del subtítulo y la entrada de posición se concatenan (fusionan) y luego pasan por una capa de incrustación de palabras . Luego, las características de la imagen y las palabras incrustadas son también se fusionó (usando concatenar) con la entrada de máscara. Juntos, todos pasan a través de la celda LSTM y la salida de la celda LSTM luego pasa por la capa Dropout y Batch Normalization para evitar que el modelo se sobreajuste . Finalmente, se aplica la no linealidad de Softmax y se obtiene el resultado esperado.
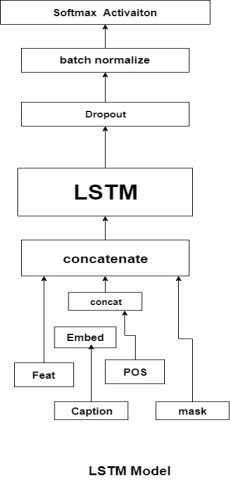
El resultado que obtenemos es un vector que tiene cada entrada que representa la posibilidad de cada palabra en el diccionario. La palabra con la probabilidad más alta sería nuestra «mejor palabra» actual. Junto con el diccionario prediseñado, este vector se usa para «interpretar» la siguiente palabra generada, lo que puede considerarse un tipo de verdad básica para entrenar en el título verdadero. La máscara juega un papel importante en todo esto, «grabando» las palabras anteriores utilizadas en los subtítulos para que el modelo conozca las palabras anteriores a la palabra actual e ingrese al modelo con la posición actual de la oración para que no caiga en un círculo.
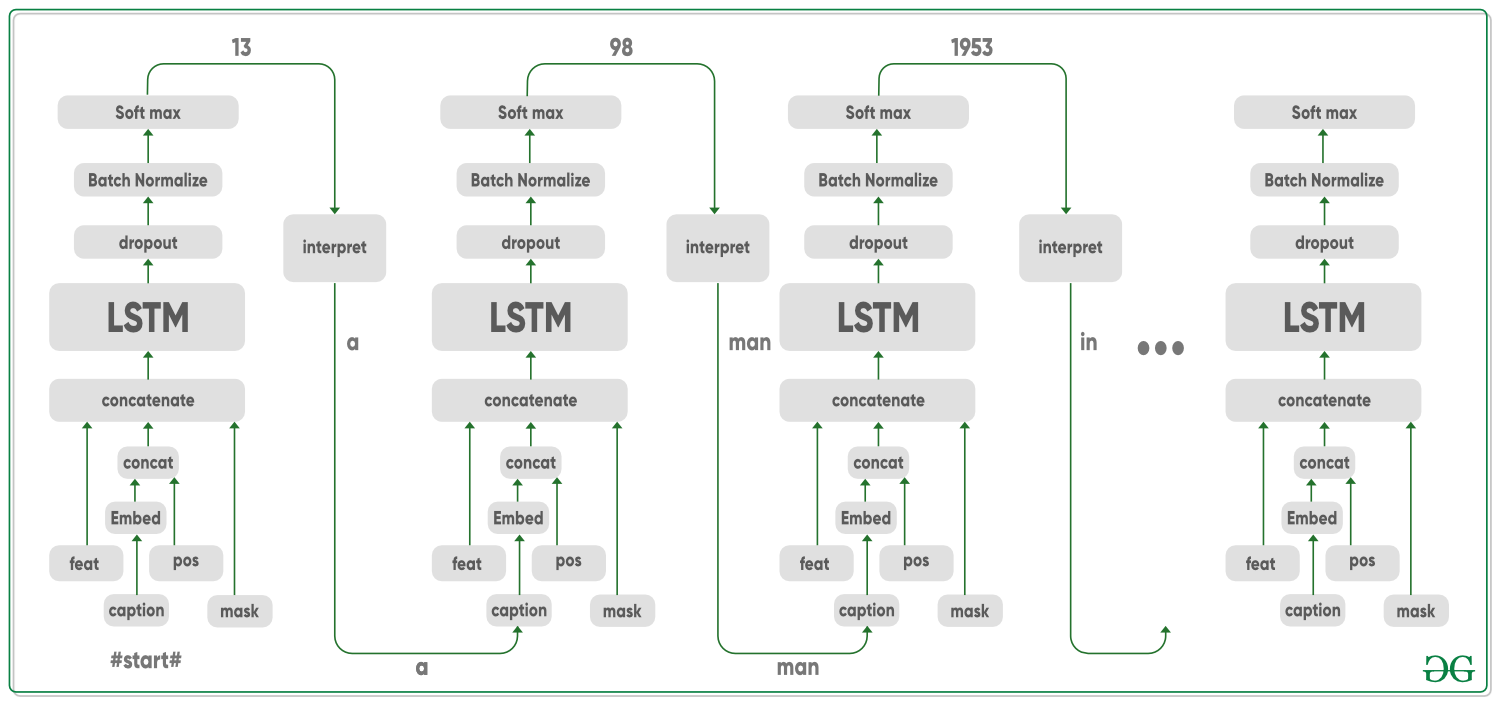
De manera similar al entrenamiento, también necesitamos obtener las características de cada imagen que se va a predecir. Entonces, las imágenes pasan primero por la arquitectura de red VGG-16, para generar las características. Para los subtítulos, usamos el mismo modelo LSTM. La entrada de la primera palabra para este modelo es la etiqueta ‘#start#’ y la siguiente entrada es el resultado de la predicción de la iteración anterior.
Arquitectura modelo:
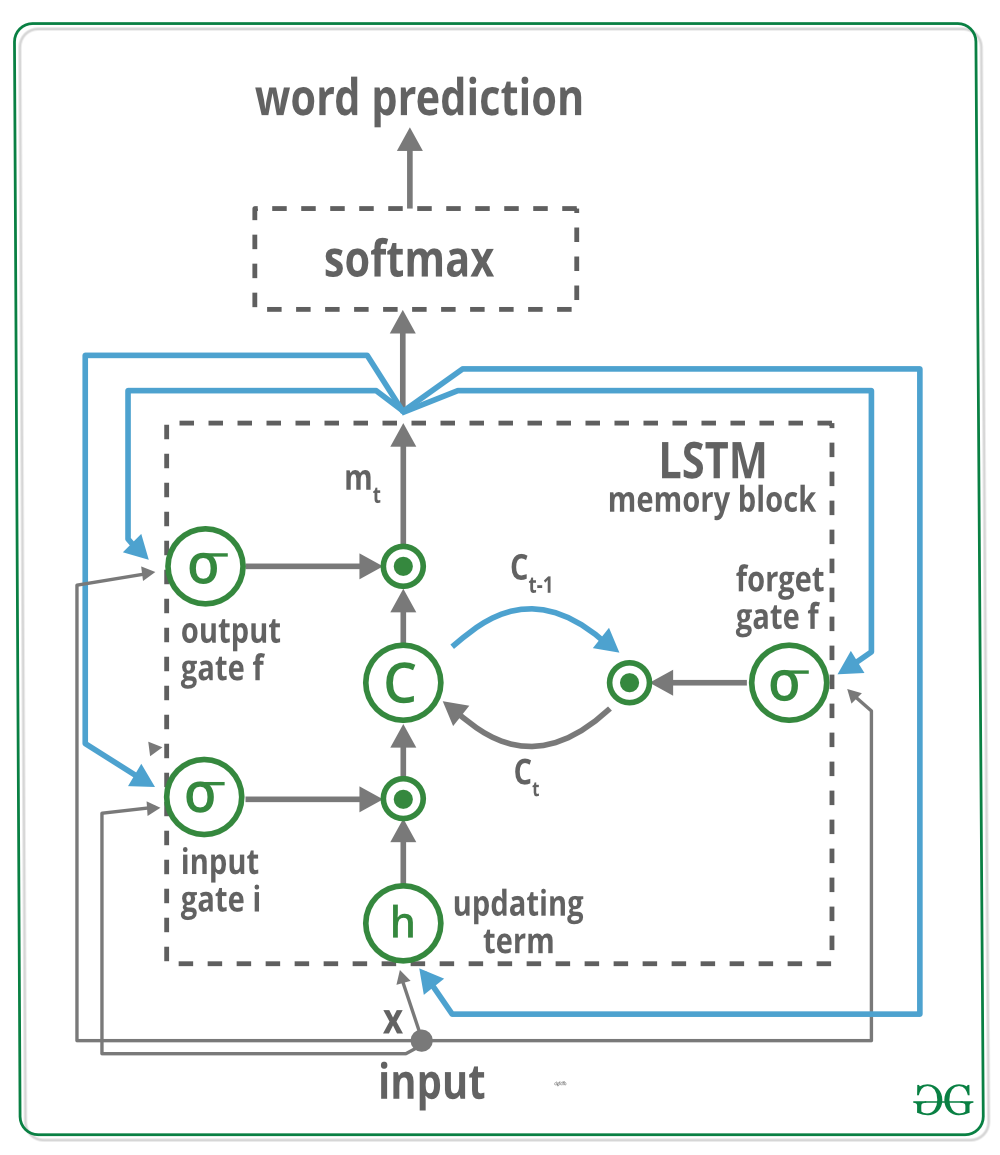
Lo alentamos a que eche un vistazo a este trabajo de investigación para obtener una intuición clara sobre lo que está sucediendo exactamente.
El bloque de memoria contiene una celda ‘C’ que está controlada por tres puertas. En azul mostramos las conexiones recurrentes, la salida ‘m’ en el momento ‘t-1’ se retroalimenta a la memoria en el momento ‘t’ a través de las tres puertas, el valor de la celda se retroalimenta a través de la puerta de olvido y la palabra predicha en el tiempo ‘t-1’ se retroalimenta además de la salida de memoria ‘m’ en el tiempo ‘t’ en la función Softmax para la predicción de palabras. Lea su puerta de entrada ‘i’ y si desea generar el nuevo valor de celda (puerta de salida o).
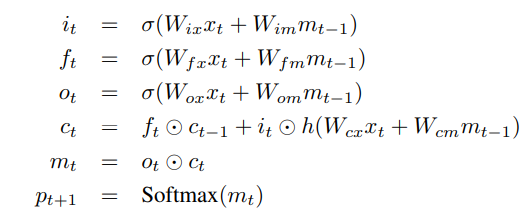
- Arquitectura codificador-decodificador: por lo general, un modelo que genera secuencias utilizará un codificador para codificar la entrada en un formato fijo y un decodificador para decodificarlo, palabra por palabra, en una secuencia.
- Atención: el uso de redes de Atención está muy extendido en el aprendizaje profundo, y por una buena razón. Esta es una forma de que un modelo elija solo aquellas partes de la codificación que cree que son relevantes para la tarea en cuestión. El mismo mecanismo que ve empleado aquí se puede usar en cualquier modelo donde la salida del codificador tenga múltiples puntos en el espacio o el tiempo. Consideramos que algunos píxeles son más importantes que otros en los subtítulos de imágenes. En tareas secuenciales como la traducción automática, considera que algunas palabras son más importantes que otras.
- Transferencia de aprendizaje: es cuando se toma prestado de un modelo existente mediante el uso de partes de él en un nuevo modelo que casi siempre es mejor que entrenar un nuevo modelo desde cero (es decir, sin saber nada) como verá, siempre podemos ajustar este segundo -pasar el conocimiento a la tarea específica en cuestión y el uso de incrustaciones de palabras previamente entrenadas es un ejemplo nulo pero válido. Usaremos un codificador previamente entrenado y luego lo ajustaremos según sea necesario.
- Beam Search: es donde no permitimos que su decodificador sea perezoso y simplemente elija las palabras con la mejor puntuación en cada paso de decodificación y Beam Search es útil para cualquier problema de modelado de lenguaje porque encuentra la secuencia más óptima.
Entendamos a través del código:
requisitos previos-
Anaconda Pytorch MSCOCO Dataset
Para replicar los resultados de este artículo, asegúrese de instalar los requisitos previos. Ahora entrenemos un modelo desde cero, siga los pasos a continuación.
conjunto de datos
git clone https://github.com/pdollar/coco.git cd coco/PythonAPI/ make python setup.py build python setup.py install cd ../../ git clone https://github.com/yunjey/pytorch-tutorial.git cd pytorch-tutorial/tutorials/03-advanced/image_captioning/ pip install -r requirements.txt
Nota: le sugerimos que use Google Colab
Modelo
preentrenado: descarguemos el modelo preentrenado y el archivo de vocabulario desde aquí , luego debemos extraer pretrained_model.zip a ./models/ y vocab.pkl a ./data/ usando el comando descomprimir.
Ahora está listo el modelo que puede predecir los subtítulos usando:
$ python sample.py --image='/example.png'
¡Comencemos el espectáculo!
Importe todas las bibliotecas y asegúrese de que el cuaderno esté en la carpeta raíz del repositorio:
import torch import matplotlib.pyplot as plt import numpy as np import argparse import pickle import os from torchvision import transforms from PIL import Image # this file is located in pytorch tutorial/image # captioning which we pull from git remember from build_vocab import Vocabulary from model import EncoderCNN, DecoderRNN
El modelo codificado no se puede modificar:
# Model path # make sure path must correct ENCODER_PATH = 'content/encoder-5-3000.pkl' DECODER_PATH = 'content/decoder-5-3000.pkl' VOCAB_PATH = 'content/vocab.pkl' # CONSTANTS because of architecture what we are using EMBED_SIZE = 256 HIDDEN_SIZE = 512 NUM_LAYERS = 1
Para cargar_imagen agregue este código de configuración:
# Device configuration snippet device = torch.cuda.device(0) # 0 represent default device # Function to Load and Resize the image def load_image(image_path, transform=None): image = Image.open(image_path) image = image.resize([224, 224], Image.LANCZOS) if transform is not None: image = transform(image).unsqueeze(0) return image
Ahora, codifiquemos una función de PyTorch que use archivos de datos previamente entrenados para predecir el resultado:
def PretrainedResNet(image_path, encoder_path=ENCODER_PATH, decoder_path=DECODER_PATH, vocab_path=VOCAB_PATH, embed_size=EMBED_SIZE, hidden_size=HIDDEN_SIZE, num_layers=NUM_LAYERS): # Image preprocessing transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # Load vocabulary wrapper with open(vocab_path, 'rb') as f: vocab = pickle.load(f) # Build models # eval mode (batchnorm uses moving mean/variance) encoder = EncoderCNN(embed_size).eval() decoder = DecoderRNN(embed_size, hidden_size, len(vocab), num_layers) encoder = encoder.to(device) decoder = decoder.to(device) # Load the trained model parameters encoder.load_state_dict(torch.load(encoder_path)) decoder.load_state_dict(torch.load(decoder_path)) # Prepare an image image = load_image(image_path, transform) image_tensor = image.to(device) # Generate a caption from the image feature = encoder(image_tensor) sampled_ids = decoder.sample(feature) # (1, max_seq_length) -> (max_seq_length) sampled_ids = sampled_ids[0].cpu().numpy() # Convert word_ids to words sampled_caption = [] for word_id in sampled_ids: word = vocab.idx2word[word_id] sampled_caption.append(word) if word == '<end>': break sentence = ' '.join(sampled_caption)[8:-5].title() # Print out the image and the generated caption image = Image.open(image_path) return sentence, image
Comencemos con la producción de subtítulos en algunas escenas de Avenger’s EndGame, y veamos qué tan bien se generaliza, no se olviden de disfrutar.
Para predecir las etiquetas, use el siguiente código:
plt.figure(figsize=(24,24)) predicted_label, image = PretrainedResNet(image_path='IMAGE_PATH') plt.imshow(image) print(predicted_label)
Teníamos a Hulk, ahora tenemos DeepLearning. 😀
Imagen de prueba: Thor- Mark I
Echemos un vistazo a esta imagen 
Ahora ¿Qué opinas de esta imagen? Mantén una leyenda en tu mente sin desplazarte hacia abajo.
plt.figure(figsize=(17,19)) predicted_label, img = PretrainedResNet(image_path='./image/AVENGERENDGAME1.png') plt.imshow(img) print(predicted_label)
Producción:![]()
Thor
Imagen de prueba: Tony- Mark II
Ahora ¿Qué opinas de esta imagen? Mantén una leyenda en tu mente sin desplazarte hacia abajo.
plt.figure(figsize=(22,22)) predicted_label, img = PretrainedResNet(image_path='./image/AVENGERENDGAME2.png') plt.imshow(img) print(predicted_label)
Producción:![]()
(tony and doctor strange)
Imagen de prueba: Hulk- Mark III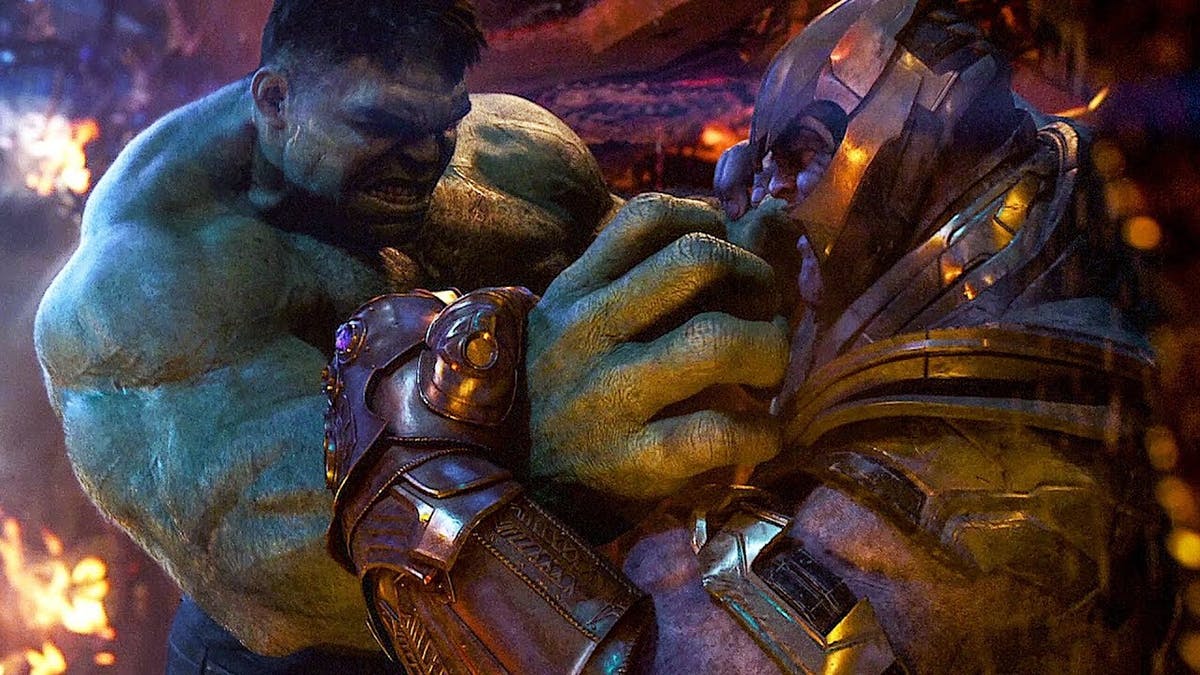
Ahora ¿Qué opinas de esta imagen? Mantén una leyenda en tu mente sin desplazarte hacia abajo.
plt.figure(figsize=(42,49)) predicted_label, img = PretrainedResNet(image_path='./image/AVENGERENDGAME3.png') plt.imshow(img) print(predicted_label)
Producción:![]()
(thanos and Hulk)
Nota: estamos usando el nombre de la imagen aquí, AVENGERENDGAME*.pngdonde * varía de 1,2,3, etc., pero puede poner sus propias imágenes y tener en cuenta que una puede tener un título diferente y otra puede tener una diferente.
Publicación traducida automáticamente
Artículo escrito por ankurtripathi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA