Pandas es una de las bibliotecas de Python más populares que se utiliza principalmente para la manipulación y el análisis de datos. Cuando estamos trabajando con grandes datos, muchas veces necesitamos realizar Análisis Exploratorios de Datos . Necesitamos obtener la descripción detallada de las diferentes columnas disponibles y su relación, verificación nula, tipos de datos, valores faltantes, etc. Entonces, la creación de perfiles de Pandas es el módulo de Python que hace el EDA y brinda una descripción detallada solo con unas pocas líneas de código.
Instalación:
pip install pandas-profiling
Ejemplo:
#import the packages
import pandas as pd
import pandas_profiling
# read the file
df = pd.read_csv('Geeks.csv')
# run the profile report
profile = df.profile_report(title='Pandas Profiling Report')
# save the report as html file
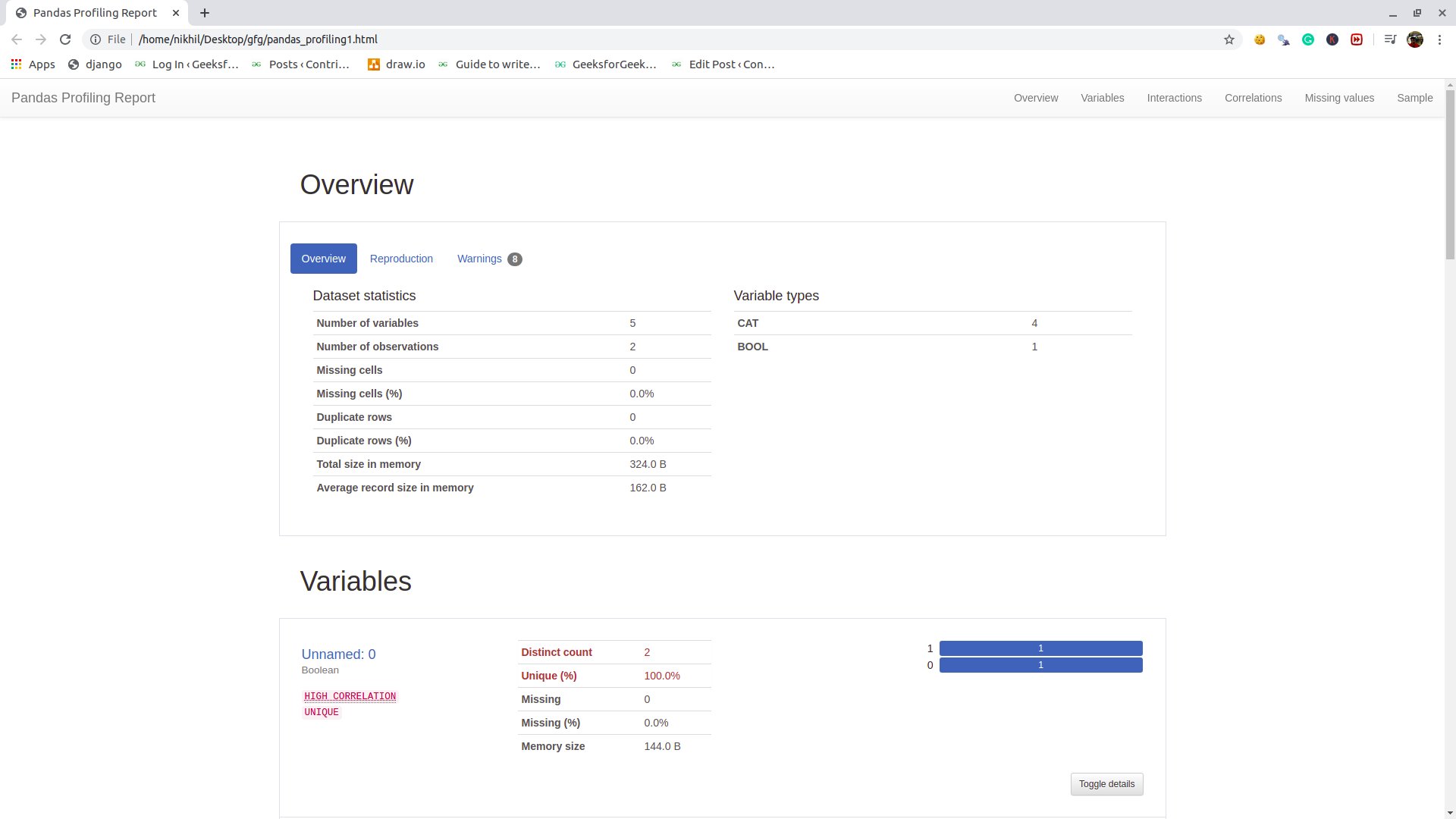
profile.to_file(output_file="pandas_profiling1.html")
# save the report as json file
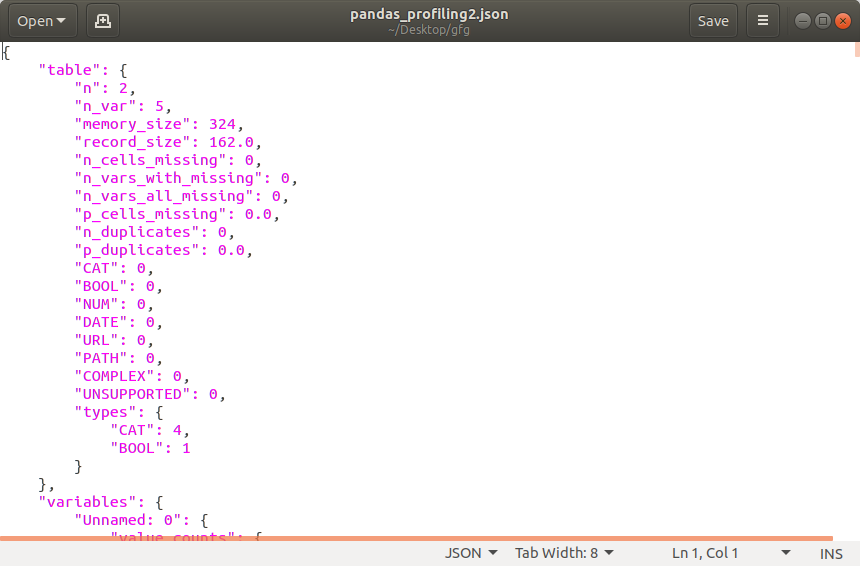
profile.to_file(output_file="pandas_profiling2.json")
Producción:
Archivo HTML:
Archivo JSON:
Publicación traducida automáticamente
Artículo escrito por itsanjanikumari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA