En este artículo, vamos a discutir cómo seleccionar un subconjunto de columnas y filas de un DataFrame. Vamos a utilizar el conjunto de datos nba.csv para realizar todas las operaciones.
Python3
# import required module
import pandas as pd
# assign dataframe
data = pd.read_csv("nba.csv")
# display dataframe
data.head()
Producción:
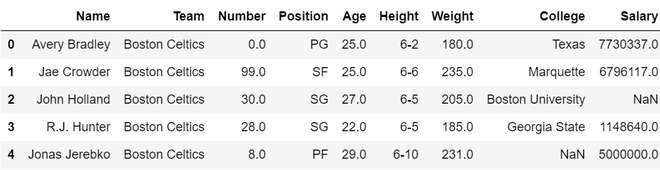
A continuación se muestran varias operaciones mediante las cuales podemos seleccionar un subconjunto para un marco de datos determinado:
- Seleccione una columna específica de un marco de datos
Para seleccionar una sola columna, podemos usar un corchete [ ]:
Python3
# import required module
import pandas as pd
# assign dataframe
data = pd.read_csv("nba.csv")
# get a single columns
ages = data["Age"]
# display the column
ages.head()
Producción:
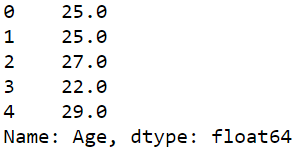
- Seleccione varias columnas de un marco de datos
Podemos pasar una lista de nombres de columnas dentro del corchete [] para obtener varias columnas:
Python3
# import required module
import pandas as pd
# assign dataframe
data = pd.read_csv("nba.csv")
# get a single columns
name_sex = data[["Name","Age"]]
# display the column
name_sex.head()
Producción:
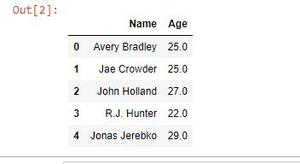
- Seleccione un subconjunto de filas de un marco de datos
Para seleccionar filas de personas mayores de 25 años en el conjunto de datos dado, podemos poner condiciones entre paréntesis para seleccionar filas específicas según la condición.
Python3
# importing pandas library
import pandas as pd
# reading csv file
data = pd.read_csv("nba.csv")
# subset of dataframe
above_25 = data[data["Age"] > 35]
# display subset
print(above_25.head())
Producción:
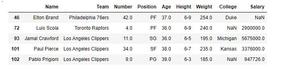
- Seleccione un subconjunto de filas y columnas combinadas
En este caso, se crea un subconjunto de todas las filas y columnas de una sola vez, y seleccionar [] no es suficiente ahora. Se necesitan los operadores loc o iloc . La sección antes de la coma son las filas que elige, y la parte después de la coma son las columnas que desea elegir usando loc o iloc . Aquí seleccionamos solo nombres de personas mayores de 25 años.
Python3
# importing pandas library
import pandas as pd
# reading csv file
data = pd.read_csv("nba.csv")
# subset of dataframe
adults = data.loc[data["Age"] > 25, "Name"]
# display susbset
print(adults.head())
Producción:

Publicación traducida automáticamente
Artículo escrito por KapilChhipa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA