Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.resample()se utiliza principalmente para datos de series temporales.
Una serie de tiempo es una serie de puntos de datos indexados (o listados o graficados) en orden de tiempo. Más comúnmente, una serie de tiempo es una secuencia tomada en puntos sucesivos igualmente espaciados en el tiempo. Es un método de conveniencia para conversión de frecuencia y remuestreo de series de tiempo. El objeto debe tener un índice similar a la fecha y hora (DatetimeIndex, PeriodIndex o TimedeltaIndex) o pasar valores similares a la fecha y hora a la palabra clave on o level.
Sintaxis: DataFrame.resample(regla, cómo=Ninguno, eje=0, fill_method=Ninguno, cerrado=Ninguno, etiqueta=Ninguno, convención=’inicio’, tipo=Ninguno, loffset=Ninguno, límite=Ninguno, base=0, on=Ninguno, nivel=Ninguno)
Parámetros:
regla: la string de desplazamiento u objeto que representa el
eje de conversión de destino: int, opcional, predeterminado 0
cerrado: {‘derecha’, ‘izquierda’}
etiqueta: {‘derecha’, ‘izquierda’}
convención: solo para PeriodIndex, controla si para usar el inicio o el final de la regla
loffset: ajuste la base de las etiquetas de tiempo remuestreado
: para frecuencias que subdividen uniformemente 1 día, el «origen» de los intervalos agregados. Por ejemplo, para una frecuencia de ‘5 min’, la base puede variar de 0 a 4. El valor predeterminado es 0.
on: para un DataFrame, columna que se utilizará en lugar de índice para el remuestreo. La columna debe ser similar a una fecha y hora.
nivel :Para un índice múltiple, nivel (nombre o número) que se usará para el remuestreo. El nivel debe ser similar a una fecha y hora.
El remuestreo genera una distribución de muestreo única sobre la base de los datos reales. Podemos aplicar varias frecuencias para volver a muestrear nuestros datos de series temporales. Esta es una técnica muy importante en el campo de la analítica.
Las frecuencias de series de tiempo más comúnmente utilizadas son –
W : frecuencia semanal
M : frecuencia de fin de mes
SM : frecuencia de fin de mes (15 y fin de mes)
Q : frecuencia de fin de trimestre
Hay muchos otros tipos de frecuencias de series temporales disponibles. Veamos cómo aplicar esta frecuencia de serie temporal en los datos y volver a muestrearlo.
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Estos son datos de precios de acciones de Apple por una duración de 1 año desde (13-11-17) hasta (13-11-18)
Ejemplo #1: Remuestreo de los datos en frecuencia mensual
# importing pandas as pd
import pandas as pd
# By default the "date" column was in string format,
# we need to convert it into date-time format
# parse_dates =["date"], converts the "date"
# column to date-time format. We know that
# resampling works with time-series data only
# so convert "date" column to index
# index_col ="date", makes "date" column, the index of the data frame
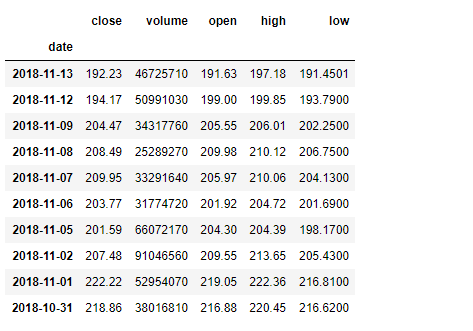
df = pd.read_csv("apple.csv", parse_dates =["date"], index_col ="date")
# Printing the first 10 rows of dataframe
df[:10]
# Resampling the time series data based on months
# we apply it on stock close price
# 'M' indicates month
monthly_resampled_data = df.close.resample('M').mean()
# the above command will find the mean closing price
# of each month for a duration of 12 months.
monthly_resampled_data
Salida: 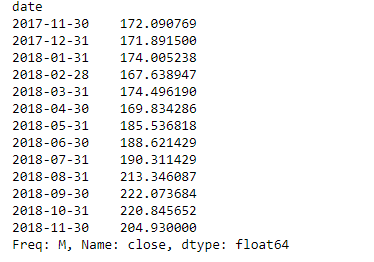
Ejemplo n.º 2: remuestreo de los datos en frecuencia semanal
# importing pandas as pd
import pandas as pd
# We know that resampling works with time-series data
# only so convert "date" column to index
# index_col ="date", makes "date" column.
df = pd.read_csv("apple.csv", parse_dates =["date"], index_col ="date")
# Resampling the time series data based on weekly frequency
# we apply it on stock open price 'W' indicates week
weekly_resampled_data = df.open.resample('W').mean()
# find the mean opening price of each week
# for each week over a period of 1 year.
weekly_resampled_data
Salida: 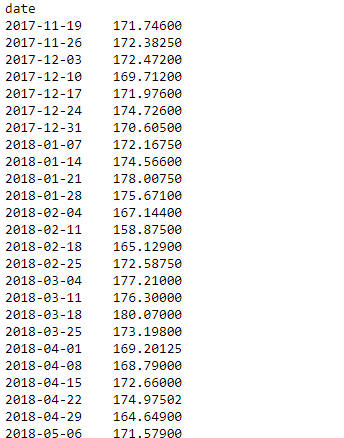
Ejemplo n.º 3: remuestreo de los datos en frecuencia trimestral
# importing pandas as pd
import pandas as pd
# We know that resampling works with time-series
# data only so convert our "date" column to index
# index_col ="date", makes "date" column
df = pd.read_csv("apple.csv", parse_dates =["date"], index_col ="date")
# Resampling the time series data
# based on Quarterly frequency
# 'Q' indicates quarter
Quarterly_resampled_data = df.open.resample('Q').mean()
# mean opening price of each quarter
# over a period of 1 year.
Quarterly_resampled_data
Producción :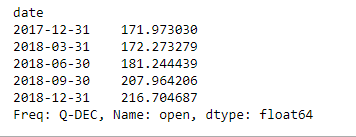
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA