Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función pandas dataframe.sort_index() ordena los objetos por etiquetas a lo largo del eje dado.
Básicamente, el algoritmo de clasificación se aplica en las etiquetas de los ejes en lugar de los datos reales en el marco de datos y, en función de eso, los datos se reorganizan. Tenemos la libertad de elegir qué algoritmo de clasificación nos gustaría aplicar. Hay tres posibles algoritmos de clasificación que podemos usar ‘quicksort’, ‘mergesort’ y ‘heapsort’.
Sintaxis: DataFrame.sort_index(axis=0, level=None, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’, sort_remaining=True, by=None)
Parámetros:
eje: índice, columnas a nivel de ordenación directa
: si no es Ninguno, ordene los valores en los niveles de índice especificados
ascendente: ordene ascendente frente a descendente
en el lugar: si es verdadero, realice la operación en el lugar
tipo: {‘quicksort’, ‘mergesort’, ‘heapsort’} , predeterminado ‘ordenación rápida’. Elección del algoritmo de clasificación. Consulte también ndarray.np.sort para obtener más información. mergesort es el único algoritmo estable. Para DataFrames, esta opción solo se aplica cuando se ordena en una sola columna o etiqueta.
posición_na :[{‘first’, ‘last’}, default ‘last’] First pone NaNs al principio, last pone NaNs al final. No implementado para MultiIndex.
sort_remaining: si es verdadero y la ordenación por nivel e índice es multinivel, ordene también por otros niveles (en orden) después de ordenar por el nivel especificado
Return: sorted_obj: DataFrame
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
. Ejemplo n.º 1: utilice la función sort_index() para ordenar el marco de datos en función de las etiquetas de índice.
Python3
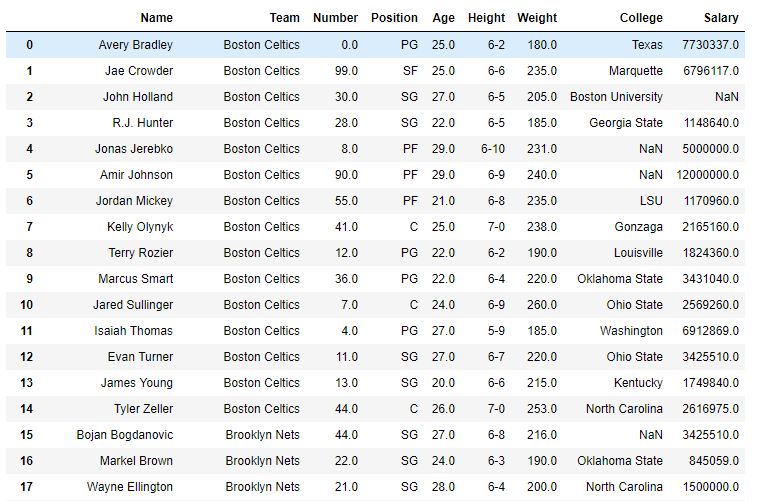
# importing pandas as pdimportpandas as pd# Creating the dataframedf=pd.read_csv("nba.csv")# Print the dataframedf
Como podemos ver en la salida, las etiquetas de índice ya están ordenadas, es decir (0, 1, 2, ….). Así que vamos a extraer una muestra aleatoria y luego clasificarla con fines de demostración.
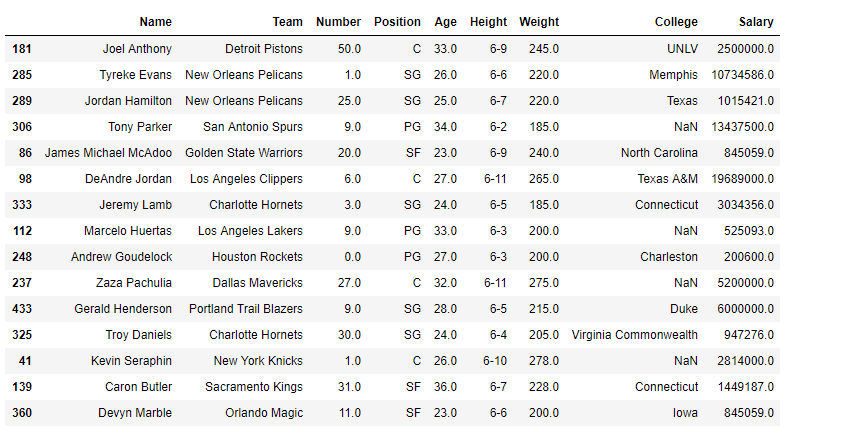
Extraigamos una muestra aleatoria de 15 elementos del marco de datos usando la función dataframe.sample().
Python3
# extract the sample dataframe from "df"# and store it in "sample_df"sample_df=df.sample(15)# Print the sample data framesample_df
Nota: cada vez que ejecutamos la función dataframe.sample(), dará un resultado diferente. Usemos la función dataframe.sort_index() para ordenar el marco de datos según las etiquetas de índice
Python3
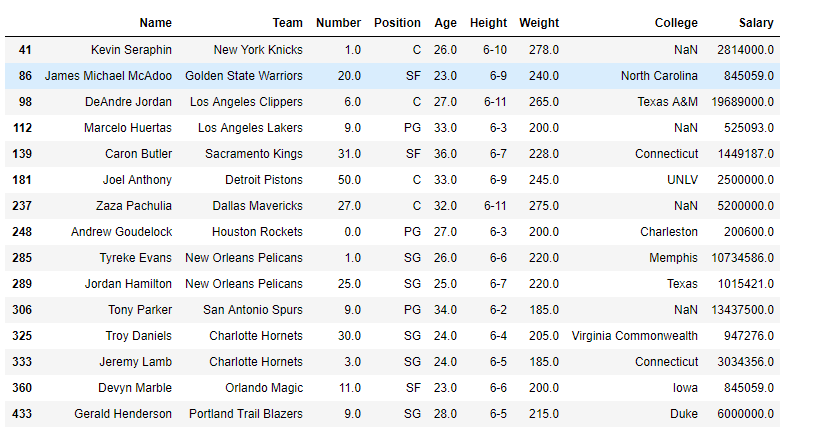
# sort by index labelssample_df.sort_index(axis=0)Producción :
Como podemos ver en la salida, las etiquetas de índice están ordenadas.
Ejemplo n.º 2: utilice la función sort_index() para ordenar el marco de datos en función de las etiquetas de las columnas.
Python3
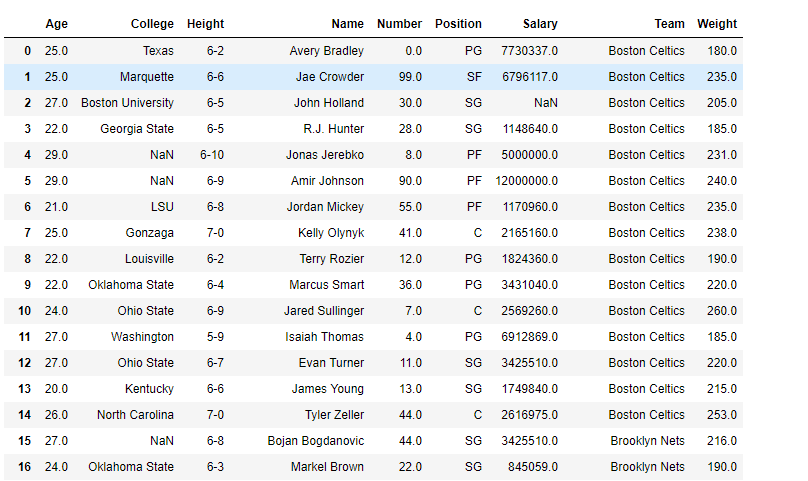
# importing pandas as pdimportpandas as pd# Creating the dataframedf=pd.read_csv("nba.csv")# sorting based on column labelsdf.sort_index(axis=1)Producción :
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA