Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas str.wrap()es un método importante cuando se trata de datos de texto extenso (párrafos o mensajes). Esto se usa para distribuir datos de texto largo en nuevas líneas o manejar espacios de tabulación cuando excede el ancho pasado. Dado que este es un método de string, .str debe tener el prefijo cada vez antes de llamar a este método.
Sintaxis: Series.str.wrap(ancho, **kwargs)
Parámetros:
ancho: valor entero, define el ancho máximo de línea**kwargs [Parámetros opcionales]
expand_tabs: valor booleano, expande los caracteres de tabulación a espacios si es verdadero
replace_whitespace: valor booleano, si es verdadero, cada carácter de espacio en blanco se reemplaza por un solo espacio en blanco.
drop_whitespace: valor booleano, si es verdadero, elimina los espacios en blanco, si los hay, al comienzo de las nuevas líneas.
break_long_words: valor booleano, si es verdadero, rompe las palabras que son más largas que el ancho pasado.
break_on_hyphens: valor booleano, si es verdadero, rompe la string en guiones donde la longitud de la string es menor que el ancho.Tipo de valor devuelto: Serie con líneas divididas/caracteres añadidos(‘\n’)
Para descargar el conjunto de datos utilizado en el código, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación.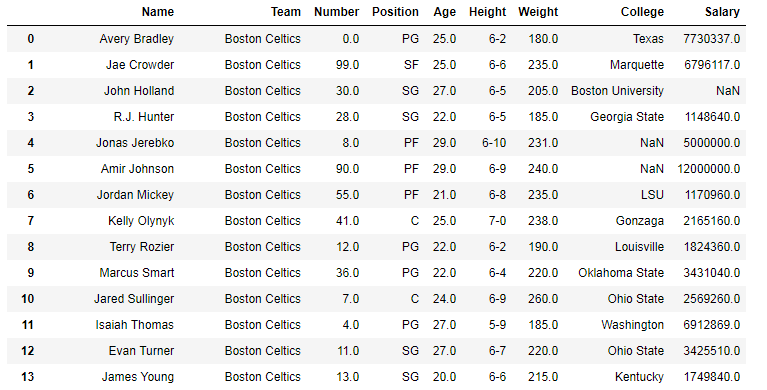
Ejemplo:
en este ejemplo, la columna Equipo se ajusta con un ancho de línea de 5 caracteres. Por lo tanto \n se colocará después de cada 5 caracteres. Se imprime un elemento aleatorio de la columna del equipo nuevo y la columna del equipo anterior para ver el funcionamiento. Antes de aplicar cualquier operación, los elementos nulos se eliminan mediante .dropna()el método.
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# dropping null value columns to avoid errors
data.dropna(inplace = True)
# display
data["New Team"]= data["Team"].str.wrap(5)
# data frame display
data
# printing same index separately
print(data["Team"][120])
print("------------")
print(data["New Team"][120])
Salida:
como se muestra en las imágenes de salida, la columna Nuevo tiene ‘\n’ después de cada 5 caracteres. Después de imprimir el mismo índice de las columnas del equipo antiguo y nuevo, se puede ver que sin agregar el carácter de nueva línea en la declaración de impresión, python lee automáticamente ‘\n’ en la string y lo coloca en la nueva línea.
Marco de datos con la columna Nuevo equipo-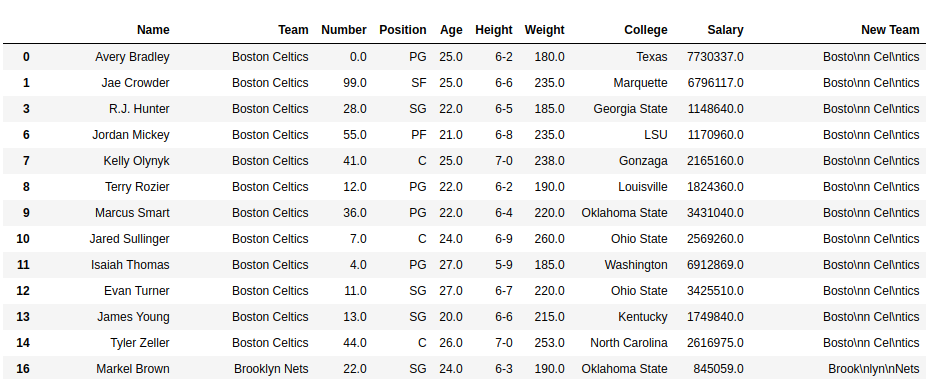
Producción:
Los Angeles Lakers ------------ Los A ngele s Lak ers
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA