Data Wrangling es el proceso de recopilación, recopilación y transformación de datos sin procesar en otro formato para una mejor comprensión, toma de decisiones, acceso y análisis en menos tiempo. Data Wrangling también se conoce como Data Munging.

Importancia de la disputa de datos
La disputa de datos es un paso muy importante. El siguiente ejemplo explicará su importancia como:
El sitio web de venta de libros quiere mostrar los libros más vendidos de diferentes dominios, según las preferencias del usuario. Por ejemplo, un nuevo usuario busca libros motivacionales, luego quiere mostrar aquellos libros motivacionales que se venden más o que tienen una calificación alta, etc.
Pero en su sitio web, hay muchos datos sin procesar de diferentes usuarios. Aquí se utiliza el concepto de Data Munging o Data Wrangling. Como sabemos, los datos no son disputados por el sistema. Este proceso es realizado por científicos de datos. Entonces, el científico de datos discutirá los datos de tal manera que clasificará los libros motivacionales que se venden más o tienen calificaciones altas o el usuario compra este libro con este paquete de libros, etc. Sobre la base de eso, el nuevo usuario hacer elección. Esto explicará la importancia de la disputa de datos.
Gestión de datos en Python
La disputa de datos es un tema crucial para la ciencia de datos y el análisis de datos. Pandas Framework of Python se utiliza para Data Wrangling. Pandas es una biblioteca de código abierto desarrollada específicamente para análisis de datos y ciencia de datos. El proceso como clasificación o filtración de datos, agrupación de datos, etc.
La disputa de datos en python se ocupa de las siguientes funcionalidades:
- Exploración de datos: en este proceso, los datos se estudian, analizan y comprenden mediante la visualización de representaciones de datos.
- Manejo de valores faltantes: la mayoría de los conjuntos de datos que tienen una gran cantidad de datos contienen valores faltantes de NaN, es necesario solucionarlos reemplazándolos con la media, la moda, el valor más frecuente de la columna o simplemente eliminando la fila que tiene un valor NaN .
- Remodelación de datos: en este proceso, los datos se manipulan de acuerdo con los requisitos, donde se pueden agregar nuevos datos o se pueden modificar los datos preexistentes.
- Filtrado de datos: algunas veces, los conjuntos de datos se componen de filas o columnas no deseadas que deben eliminarse o filtrarse.
- Otro: después de tratar el conjunto de datos sin procesar con las funcionalidades anteriores, obtenemos un conjunto de datos eficiente según nuestros requisitos y luego se puede usar para un propósito requerido, como análisis de datos, aprendizaje automático, visualización de datos, entrenamiento de modelos, etc.
A continuación se muestra un ejemplo que implementa las funcionalidades anteriores en un conjunto de datos sin procesar:
- Exploración de datos , aquí asignamos los datos, y luego visualizamos los datos en un formato tabular.
Python3
# Import pandas package
import pandas as pd
# Assign data
data = {'Name': ['Jai', 'Princi', 'Gaurav',
'Anuj', 'Ravi', 'Natasha', 'Riya'],
'Age': [17, 17, 18, 17, 18, 17, 17],
'Gender': ['M', 'F', 'M', 'M', 'M', 'F', 'F'],
'Marks': [90, 76, 'NaN', 74, 65, 'NaN', 71]}
# Convert into DataFrame
df = pd.DataFrame(data)
# Display data
df
Producción:
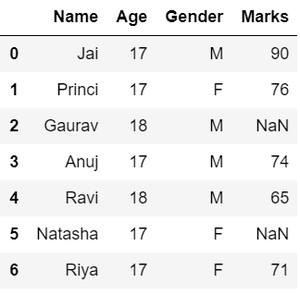
- En cuanto a los valores faltantes , como podemos ver en la salida anterior, hay valores de NaN presentes en la columna MARCAS que se van a solucionar reemplazándolos con la media de la columna.
Python3
# Compute average c = avg = 0 for ele in df['Marks']: if str(ele).isnumeric(): c += 1 avg += ele avg /= c # Replace missing values df = df.replace(to_replace="NaN", value=avg) # Display data df
Producción:
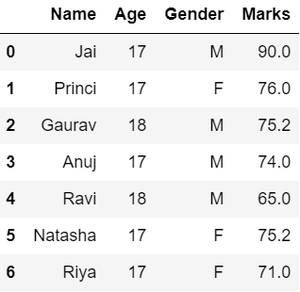
- Remodelación de datos , en la columna GÉNERO , podemos remodelar los datos clasificándolos en diferentes números.
Python3
# Categorize gender
df['Gender'] = df['Gender'].map({'M': 0,
'F': 1, }).astype(float)
# Display data
df
Producción:
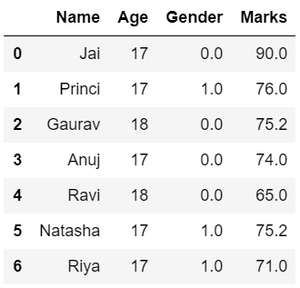
- Filtrando datos , supongamos que hay un requisito para los detalles relacionados con el nombre, el sexo y las calificaciones de los estudiantes con la puntuación más alta. Aquí necesitamos eliminar algunos datos no deseados.
Python3
# Filter top scoring students df = df[df['Marks'] >= 75] # Remove age row df = df.drop(['Age'], axis=1) # Display data df
Producción:
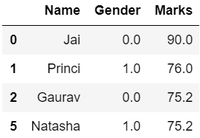
Por lo tanto, finalmente hemos obtenido un conjunto de datos eficiente que se puede utilizar para varios propósitos.
Ahora que conocemos los conceptos básicos de la disputa de datos. A continuación, analizaremos varias operaciones con las que podemos realizar la disputa de datos:
Gestión de datos mediante la operación de combinación
La operación de combinación se utiliza para combinar datos sin procesar y en el formato deseado.
Sintaxis:
pd.merge( data_frame1,data_frame2, on="field ")
Aquí el campo es el nombre de la columna que es similar en ambos marcos de datos.
Por ejemplo: suponga que un maestro tiene dos tipos de datos, el primer tipo de datos consiste en detalles de los estudiantes y el segundo tipo de datos consiste en el estado de tarifas pendientes que se toma de la oficina de cuentas. Entonces, The Teacher usará la operación de fusión aquí para fusionar los datos y darle significado. Para que el maestro lo analice fácilmente y también reduce el tiempo y el esfuerzo del maestro de la fusión manual.
PRIMER TIPO DE DATOS:
Python3
# import module
import pandas as pd
# creating DataFrame for Student Details
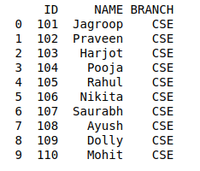
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105, 106,
107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# printing details
print(details)
Producción:
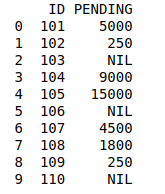
SEGUNDO TIPO DE DATOS
Python3
# Import module
import pandas as pd
# Creating Dataframe for Fees_Status
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Printing fees_status
print(fees_status)
Producción:
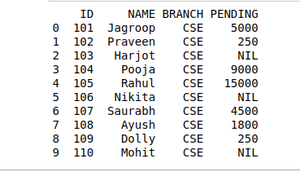
DISPUTA DE DATOS UTILIZANDO LA OPERACIÓN DE FUSIÓN:
Python3
# Import module
import pandas as pd
# Creating Dataframe
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# Creating Dataframe
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Merging Dataframe
print(pd.merge(details, fees_status, on='ID'))
Producción:
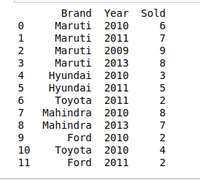
Arreglar datos usando el método de agrupación
El método de agrupación en el análisis de datos se utiliza para proporcionar resultados en términos de varios grupos extraídos de Big Data. Este método de pandas se usa para agrupar el inicio de los datos del gran conjunto de datos.
Ejemplo: hay una empresa de venta de automóviles y esta empresa tiene diferentes marcas de varias empresas de fabricación de automóviles como Maruti, Toyota, Mahindra, Ford, etc. y tiene datos donde se venden diferentes automóviles en diferentes años. Por lo tanto, la empresa desea disputar solo los datos en los que se vendieron automóviles durante el año 2010. Para este problema, usamos otra técnica de disputa que es el método groupby() .
DATOS DE VENTA DE COCHES:
Python3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe of car_selling_data
df = pd.DataFrame(car_selling_data)
# printing Dataframe
print(df)
Producción:
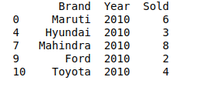
DATOS DEL AÑO 2010:
Python3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe for Provided Data
df = pd.DataFrame(car_selling_data)
# Group the data when year = 2010
grouped = df.groupby('Year')
print(grouped.get_group(2010))
Producción:
Arreglar datos eliminando la duplicación
El método Pandas duplicates() nos ayuda a eliminar valores duplicados de Big Data. Una parte importante de Data Wrangling es eliminar los valores duplicados del gran conjunto de datos.
Sintaxis:
DataFrame.duplicated(subset=None, keep='first')
Aquí el subconjunto es el valor de la columna donde queremos eliminar el valor duplicado.
De acuerdo , tenemos 3 opciones:
- si mantener = ‘primero’ , el primer valor se marca como el resto original, todos los valores, si ocurren, se eliminarán porque se considerarán duplicados.
- si keep=’last’ , el último valor se marca como el resto original, todos los mismos valores anteriores se eliminarán, ya que se consideran valores duplicados.
- si keep =’false’, todos los valores que ocurren más de una vez se eliminarán como un valor duplicado.
Por ejemplo, una universidad organizará el evento. Para participar, los estudiantes deben completar sus datos en el formulario en línea para que se comuniquen con ellos. Es posible que un estudiante complete el formulario varias veces. Puede causar dificultades para el organizador del evento si un solo estudiante completa varias entradas. Los datos que obtendrán los organizadores se pueden modificar fácilmente eliminando los valores duplicados.
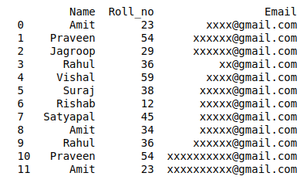
DETALLES DATOS DE LOS ALUMNOS QUE QUIEREN PARTICIPAR EN EL EVENTO:
Python3
# Import module
import pandas as pd
# Initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# Creating Dataframe of Data
df = pd.DataFrame(student_data)
# Printing Dataframe
print(df)
Producción:
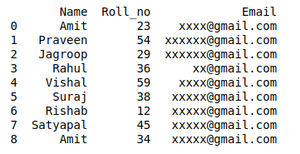
DATOS DISPUESTOS AL ELIMINAR ENTRADAS DUPLICADAS:
Python3
# import module
import pandas as pd
# initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# creating dataframe
df = pd.DataFrame(student_data)
# Here df.duplicated() list duplicate Entries in ROllno.
# So that ~(NOT) is placed in order to get non duplicate values.
non_duplicate = df[~df.duplicated('Roll_no')]
# printing non-duplicate values
print(non_duplicate)
Producción:
Publicación traducida automáticamente
Artículo escrito por jagroopofficial y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA