Aquí discutiremos cómo podemos, mejoramos el rendimiento al usar HashMap en Java , la importancia del contrato hashCode() y por qué es tan importante tener un código hash eficiente, y qué sucede cuando usamos un ineficiente código hash. Pasemos directamente a implementar lo mismo sobre el mismo tamaño de conjunto de claves en nuestro HashMap. Es como sigue:
Implementación: aquí no se introduce tal concepto, por lo que se aplica un enfoque ingenuo sobre nuestro HashMap.
Ejemplo 1:
Java
// Java Program to Illustrate In-efficient Technique
// While using HashMap
// Importing Map and HashMap utility classes
// from java.util package
import java.util.HashMap;
import java.util.Map;
// Main class
class HashMapEx2 {
// main driver method
public static void main(String[] args)
{
// Creating a Map object
// Declaring object of user-defined class and string
// type
Map<Student, String> studentMap = new HashMap<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
studentMap.put(new Student("saty" + i),
"satyy" + i);
}
studentMap.forEach(
(k, v) -> System.out.println(k + " : " + v));
long endTime = System.currentTimeMillis();
long timeElapsed = endTime - startTime;
System.out.println(
"\n Execution time in milliseconds for In-Efficient hashcode : "
+ timeElapsed + " milliseconds.");
}
}
/*Student class.*/
class Student {
String name;
public Student(String name)
{
super();
this.name = name;
}
@Override public String toString()
{
return "Student [name=" + name + "]";
}
/* Very in-efficient hashcode override */
@Override public int hashCode()
{
return 12; /* Very inefficient hashcode, returns 12
for every key, that means all the keys
will end up in the same bucket */
}
@Override public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student)obj;
if (name == null) {
if (other.name != null)
return false;
}
else if (!name.equals(other.name))
return false;
return true;
}
}
Salida: contiene líneas gigantescas como salida para ilustrar los milisegundos tomados, por lo tanto, la última instantánea del rollo de salida se adjunta a continuación para calcular el tiempo necesario para todas las operaciones. Es como sigue:
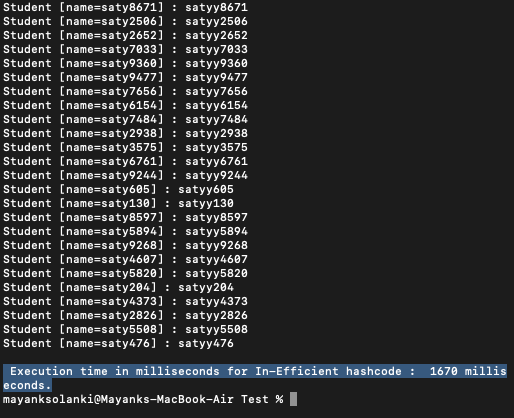
Explicación de salida: en el programa anterior, usamos Student como clave HashMap y la anulación de hashCode() en la clase Student se escribe de manera muy ineficiente, lo que devuelve el mismo código hash para cada objeto Student.
¿Por qué un código hash eficiente es tan importante?
Cuando ejecuta el programa anterior, lo que realmente sucede detrás de escena es que cuando se crea HashMap, almacena todas las 10000 claves de objetos de estudiantes en el mismo depósito. Como resultado, todas las claves se almacenan en un solo cubo, lo que resulta en un gran impacto en el rendimiento, y puede ver que el tiempo necesario para la ejecución del primer programa es de aproximadamente 1700 milisegundos.
Ahora, en el programa a continuación, nuestra anulación de código hash en la clase Student es eficiente y devuelve un código hash único para cada objeto Student. Como resultado, cada clave hashmap se almacena en un cubo separado, lo que mejora el rendimiento ‘n’ veces para almacenar las claves, y puede ver que el tiempo necesario para la ejecución del segundo programa es de solo unos 300 milisegundos.
Ejemplo 2:
Java
// Java Program to Illustrate In-efficient Technique
// While using HashMap
// Importing Map and HashMap utility classes
// from java.util package
import java.util.HashMap;
import java.util.Map;
// Main class
class HashMapEx3 {
// main driver method
public static void main(String[] args)
{
Map<Student, String> studentMap = new HashMap<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
studentMap.put(new Student("saty" + i),
"satyy" + i);
}
studentMap.forEach(
(k, v) -> System.out.println(k + " : " + v));
long endTime = System.currentTimeMillis();
long timeElapsed = endTime - startTime;
System.out.println(
"\n Execution time in milliseconds for Efficient hashCode: "
+ timeElapsed + " milliseconds");
}
}
/*Student class.*/
class Student {
String name;
public Student(String name)
{
super();
this.name = name;
}
@Override public String toString()
{
return "Student [name=" + name + "]";
}
/* Efficient hashcode override */
@Override public int hashCode()
{
return name.hashCode()
* 12; /* Efficient hashcode, returns unique
hashcode for every key, that
means the keys will be distributed into
unique buckets */
}
@Override public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student)obj;
if (name == null) {
if (other.name != null)
return false;
}
else if (!name.equals(other.name))
return false;
return true;
}
}
Salida: contiene líneas enormes como salida para ilustrar los milisegundos tomados, por lo tanto, la última instantánea del rollo de salida se adjunta a continuación para calcular el tiempo necesario para todas las operaciones. Es como sigue:
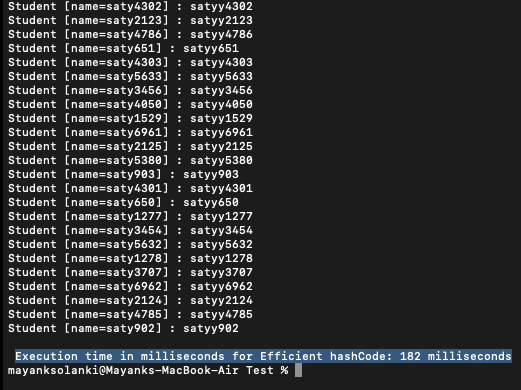
Podemos descubrir un cambio significativo en el que el ejemplo 1 toma cerca de 1700 milisegundos y aquí, como se muestra en la salida, toma cerca de 180 segundos solamente. Por lo tanto, el multiplicador de 10X se justifica cuando comparamos los ejemplos anteriores.
Publicación traducida automáticamente
Artículo escrito por mrsatyamjoshi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA