La serie Pandas es un ndarray unidimensional con etiquetas de eje. No es necesario que las etiquetas sean únicas, pero deben ser de tipo hashable. El objeto admite la indexación basada en enteros y etiquetas y proporciona una gran cantidad de métodos para realizar operaciones relacionadas con el índice.
La función Pandas Series.describe()genera estadísticas descriptivas que resumen la tendencia central, la dispersión y la forma de la distribución de un conjunto de datos para el objeto de serie dado. Todos los cálculos se realizan excluyendo los valores de NaN.
Sintaxis: Series.describe(percentiles=Ninguno, incluir=Ninguno, excluir=Ninguno)
Parámetro:
percentiles: los percentiles que se incluirán en la salida.
include : una lista blanca de tipos de datos para incluir en el resultado. Ignorado para Serie.
excluir: una lista negra de tipos de datos para omitir del resultado. Ignorado para la serieRendimientos : Estadísticas resumidas de la Serie
Ejemplo #1: Use Series.describe()la función para encontrar las estadísticas de resumen del objeto de la serie dada.
# importing pandas as pd import pandas as pd # Creating the Series sr = pd.Series([80, 25, 3, 25, 24, 6]) # Create the Index index_ = ['Coca Cola', 'Sprite', 'Coke', 'Fanta', 'Dew', 'ThumbsUp'] # set the index sr.index = index_ # Print the series print(sr)
Producción :
Ahora usaremos Series.describe()la función para encontrar las estadísticas de resumen de los datos subyacentes en el objeto de serie dado.
# find summary statistics of the underlying # data in the given series object. result = sr.describe() # Print the result print(result)
Salida: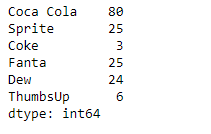
como podemos ver en la salida, la Series.describe()función ha devuelto con éxito las estadísticas de resumen del objeto de serie dado.
Ejemplo #2: use Series.describe()la función para encontrar las estadísticas de resumen de los datos subyacentes en el objeto de serie dado. El objeto de serie dado contiene algunos valores faltantes.
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([100, None, None, 18, 65, None, 32, 10, 5, 24, None])
# Create the Index
index_ = pd.date_range('2010-10-09', periods = 11, freq ='M')
# set the index
sr.index = index_
# Print the series
print(sr)
Producción :
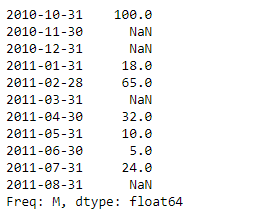
Ahora usaremos Series.describe()la función para encontrar las estadísticas de resumen de los datos subyacentes en el objeto de serie dado.
# find summary statistics of the underlying # data in the given series object. result = sr.describe() # Print the result print(result)
Producción :
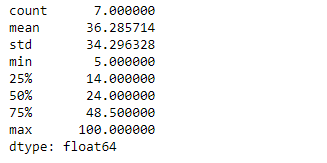
Como podemos ver en el resultado, la Series.describe()función ha devuelto con éxito las estadísticas de resumen del objeto de serie dado. NaNvalores se ha ignorado al calcular estos valores estadísticos.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA