Veamos ¿Cómo contar valores distintos de una columna de marco de datos de Pandas?
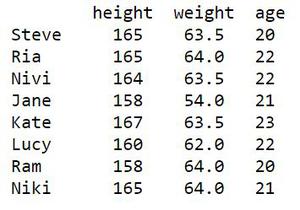
Considere una estructura tabular como se indica a continuación, que debe crearse como Dataframe. Las columnas son altura, peso y edad . Los registros de 8 estudiantes forman las filas.
| altura | peso | años | |
| Steve | 165 | 63.5 | 20 |
| Ría | 165 | 64 | 22 |
| Nivi | 164 | 63.5 | 22 |
| jane | 158 | 54 | 21 |
| Kate | 167 | 63.5 | 23 |
| lucia | 160 | 62 | 22 |
| RAM | 158 | 64 | 20 |
| niki | 165 | 64 | 21 |
El primer paso es crear el marco de datos para la tabulación anterior. Mire el fragmento de código a continuación.
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# show the Dataframe
df
Producción:
Método 1: Uso del bucle for.
El marco de datos se ha creado y se puede codificar usando for loop y contar el número de valores únicos en una columna específica. Por ejemplo, en la tabla anterior, si se desea contar el número de valores únicos en la altura de la columna . La idea es usar una variable cnt para almacenar el conteo y una lista visitada que tenga los valores visitados previamente. Luego, el ciclo for que itera a través de la columna ‘altura’ y para cada valor, verifica si el mismo valor ya ha sido visitado en la lista visitada. Si el valor no se visitó anteriormente, el conteo se incrementa en 1.
A continuación se muestra la implementación:
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# variable to hold the count
cnt = 0
# list to hold visited values
visited = []
# loop for counting the unique
# values in height
for i in range(0, len(df['height'])):
if df['height'][i] not in visited:
visited.append(df['height'][i])
cnt += 1
print("No.of.unique values :",
cnt)
print("unique values :",
visited)
Producción :
No.of.unique values : 5 unique values : [165, 164, 158, 167, 160]
Pero este método no es tan eficiente cuando el Dataframe crece en tamaño y contiene miles de filas y columnas. Para dar una eficiencia hay tres métodos disponibles que se enumeran a continuación:
- pandas.unique()
- Marco de datos.nunique()
- Serie.value_counts()
Método 2: Usar unique().
El método único toma una array o serie 1-D como entrada y devuelve una lista de elementos únicos en ella. El valor devuelto es una array NumPy y el contenido de la misma se basa en la entrada pasada. Si se proporcionan índices como entrada, el valor devuelto también serán los índices del valor único.
Sintaxis: pandas.unique(Series)
Ejemplo:
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# counting unique values
n = len(pd.unique(df['height']))
print("No.of.unique values :",
n)
Producción:
No.of.unique values : 5
Método 3: Usar Dataframe.nunique() .
Este método devuelve el recuento de valores únicos en el eje especificado. La sintaxis es:
Sintaxis: Dataframe.nunique (eje=0/1, dropna=Verdadero/Falso)
Ejemplo:
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# check the values of
# each row for each column
n = df.nunique(axis=0)
print("No.of.unique values in each column :\n",
n)
Producción:
No.of.unique values in each column : height 5 weight 4 age 4 dtype: int64
Para obtener el número de valores únicos en una columna específica:
Sintaxis: Dataframe.col_name.nunique()
Ejemplo:
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# count no. of unique
# values in height column
n = df.height.nunique()
print("No.of.unique values in height column :",
n)
Producción:
No.of.unique values in height column : 5
Método 3: Usar Series.value_counts() .
Este método devuelve el recuento de todos los valores únicos en la columna especificada.
Sintaxis: Series.value_counts(normalize=False, sort=True, ascendente=False, bins=Ninguno, dropna=True)
Ejemplo:
Python3
# import library
import pandas as pd
# create a Dataframe
df = pd.DataFrame({
'height' : [165, 165, 164,
158, 167, 160,
158, 165],
'weight' : [63.5, 64, 63.5,
54, 63.5, 62,
64, 64],
'age' : [20, 22, 22,
21, 23, 22,
20, 21]},
index = ['Steve', 'Ria', 'Nivi',
'Jane', 'Kate', 'Lucy',
'Ram', 'Niki'])
# getting the list of unique values
li = list(df.height.value_counts())
# print the unique value counts
print("No.of.unique values :",
len(li))
Producción:
No.of.unique values : 5
Publicación traducida automáticamente
Artículo escrito por erakshaya485 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA