Pandas proporciona un método para dividir una string alrededor de un separador/delimitador pasado. Después de eso, la string se puede almacenar como una lista en una serie o también se puede usar para crear marcos de datos de varias columnas a partir de una sola string separada.
Funciona de manera similar al método split() predeterminado de Python, pero solo se puede aplicar a una string individual. El método Pandas <code >str.split() se puede aplicar a toda una serie. .str debe tener el prefijo cada vez antes de llamar a este método para diferenciarlo de la función predeterminada de Python; de lo contrario, arrojará un error.
Sintaxis: Series.str.split(pat=Ninguno, n=-1, expandir=Falso)
Parámetros:
pat: valor de string, separador o delimitador para separar la string en.
n: número de separaciones máximas para hacer en una sola string, el valor predeterminado es -1, lo que significa todo.
expandir: valor booleano, devuelve un marco de datos con un valor diferente en diferentes columnas si es verdadero. De lo contrario, devuelve una serie con una lista de strings.Tipo de devolución: serie de lista o marco de datos según el parámetro de expansión
Para descargar el CSV utilizado en el código, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación.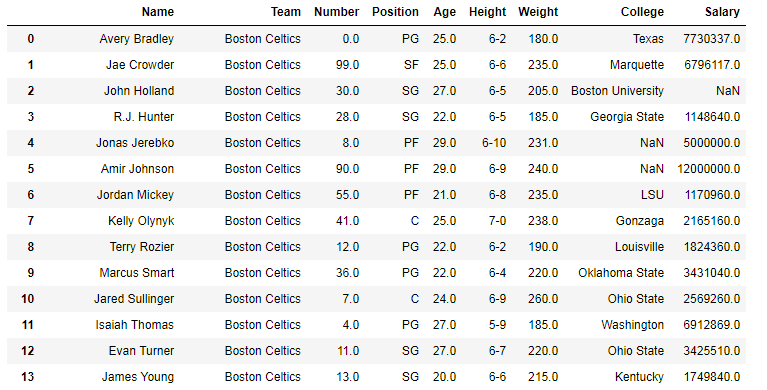
Ejemplo #1: dividir una string en una lista
En estos datos, la función de división se usa para dividir la columna Equipo en cada «t». El parámetro se establece en 1 y, por lo tanto, el número máximo de separaciones en una sola string será 1. El parámetro de expansión es Falso y es por eso que se devuelve una serie con Lista de strings en lugar de un marco de datos.
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# dropping null value columns to avoid errors
data.dropna(inplace = True)
# new data frame with split value columns
data["Team"]= data["Team"].str.split("t", n = 1, expand = True)
# df display
data
Salida:
como se muestra en la imagen de salida, la columna Equipo ahora tiene una lista. La string se separó en la primera aparición de «t» y no en la aparición posterior, ya que el parámetro n se estableció en 1 (separación máx. 1 en una string). 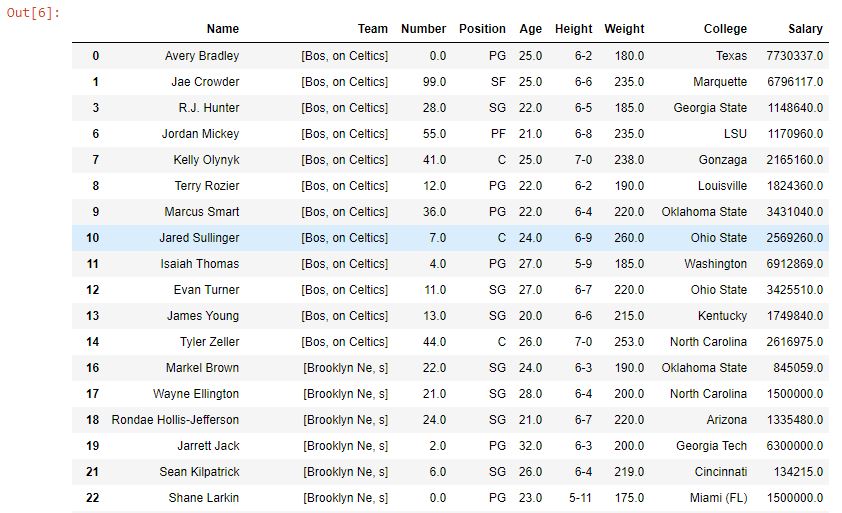
Ejemplo #2: Hacer columnas separadas de una string
En este ejemplo, la columna Nombre está separada por un espacio (» «) y el parámetro de expansión está establecido en Verdadero, lo que significa que devolverá un marco de datos con todas las strings separadas en diferentes columnas. Luego, el marco de datos se usa para crear nuevas columnas y la columna de nombre anterior se elimina con el método .drop().
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# dropping null value columns to avoid errors
data.dropna(inplace = True)
# new data frame with split value columns
new = data["Name"].str.split(" ", n = 1, expand = True)
# making separate first name column from new data frame
data["First Name"]= new[0]
# making separate last name column from new data frame
data["Last Name"]= new[1]
# Dropping old Name columns
data.drop(columns =["Name"], inplace = True)
# df display
data
Salida:
como se muestra en la imagen de salida, la función split() devolvió un nuevo marco de datos y se utilizó para crear dos nuevas columnas (Nombre y Apellido) en el marco de datos.
Nuevo marco 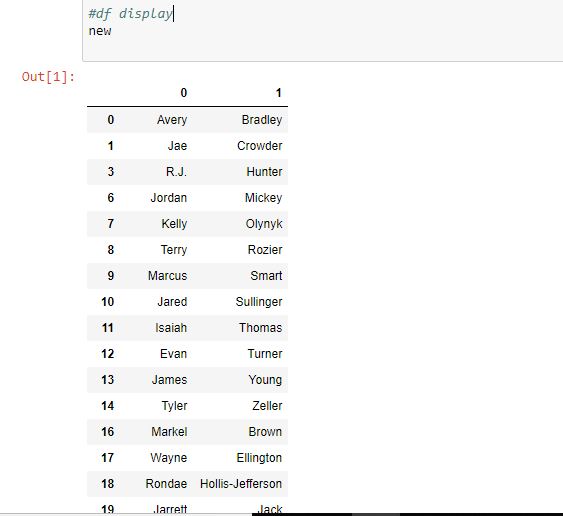
de datos Marco de datos con columnas añadidas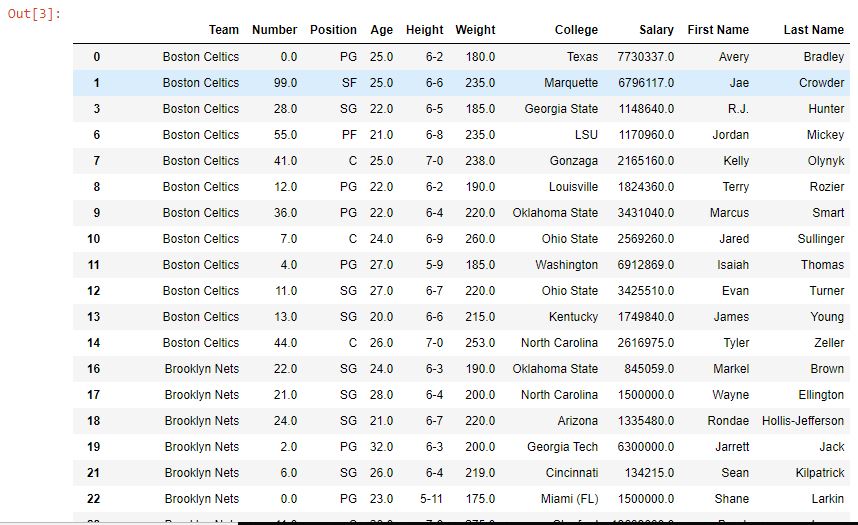
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA