Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
El método Pandas rename()se utiliza para cambiar el nombre de cualquier índice, columna o fila. El cambio de nombre de la columna también se puede hacer mediante dataframe.columns = [#list]. Pero en el caso anterior, no hay mucha libertad. Incluso si se debe cambiar una columna, se debe pasar la lista completa de columnas. Además, el método anterior no se aplica a las etiquetas de índice.
Sintaxis: DataFrame.rename(asignador=Ninguno, índice=Ninguno, columnas=Ninguno, eje=Ninguno, copia=Verdadero, en lugar=Falso, nivel=Ninguno)
Parámetros:
asignador, índice y columnas: valor de diccionario, la clave se refiere al nombre anterior y el valor se refiere al nombre nuevo. Solo se puede usar uno de estos parámetros a la vez.
eje: int o valor de string, 0/’fila’ para Filas y 1/’columnas’ para Columnas.
copy: copia los datos subyacentes si es True.
inplace: realiza cambios en el marco de datos original si es verdadero.
nivel: se utiliza para especificar el nivel en caso de que el marco de datos tenga un índice de nivel múltiple.Tipo de retorno: marco de datos con nuevos nombres
Para descargar el CSV utilizado en el código, haga clic aquí.
Ejemplo #1: Cambio de etiqueta de índice
En este ejemplo, la columna de nombre se establece como columna de índice y su nombre se cambia más tarde usando el método rename().
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name" )
# changing index cols with rename()
data.rename(index = {"Avery Bradley": "NEW NAME",
"Jae Crowder":"NEW NAME 2"},
inplace = True)
# display
data
Salida:
como se muestra en la imagen de salida, el nombre de las etiquetas de índice en la primera y segunda posición se cambió a NUEVO NOMBRE Y NUEVO NOMBRE 2.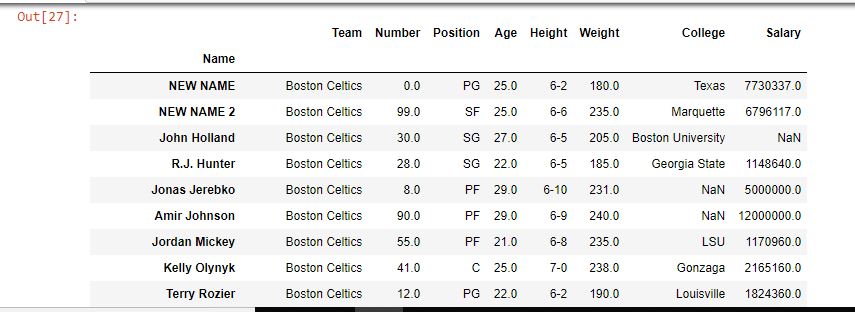
Ejemplo n.º 2: cambio de varios nombres de columna
En este ejemplo, los nombres de varias columnas se cambian pasando un diccionario. Posteriormente, el resultado se compara con el marco de datos devuelto mediante el método .columns. Los valores nulos se descartan antes de comparar, ya que NaN==NaN devolverá falso.
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name" )
# changing cols with rename()
new_data = data.rename(columns = {"Team": "Team Name",
"College":"Education",
"Salary": "Income"})
# changing columns using .columns()
data.columns = ['Team Name', 'Number', 'Position', 'Age',
'Height', 'Weight', 'Education', 'Income']
# dropna used to ignore na values
print(new_data.dropna()== data.dropna())
Salida:
como se muestra en la imagen de salida, los resultados usando ambas formas fueron los mismos ya que todos los valores son verdaderos.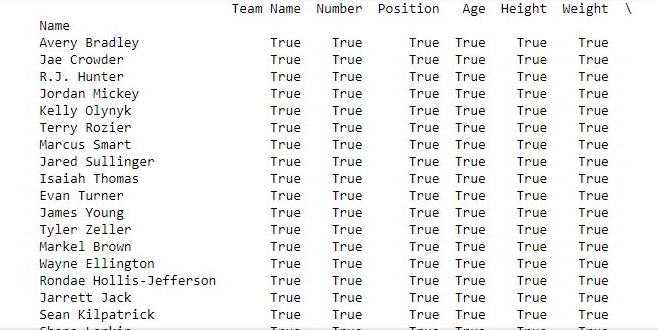
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA