Requisito previo: Implementar Web Scraping en Python con BeautifulSoup
En este artículo, vamos a ver cómo extraemos todos los párrafos del documento HTML o URL dado usando python.
Módulo necesario:
- bs4: Beautiful Soup (bs4) es una biblioteca de Python para extraer datos de archivos HTML y XML. Este módulo no viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install bs4
- requests: Requests le permite enviar requests HTTP/1.1 con mucha facilidad. Este módulo tampoco viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip install requests
Acercarse:
- Módulo de importación
- Cree un documento HTML y especifique la etiqueta ‘<p>’ en el código
- Pase el documento HTML a la función Beautifulsoup()
- Use la etiqueta ‘P’ para extraer párrafos del objeto Beautifulsoup
- Obtenga texto del documento HTML con get_text().
Código:
Python3
# import module
from bs4 import BeautifulSoup
# Html doc
html_doc = """
<html>
<head>
<title>Geeks</title>
</head>
<body>
<h2>paragraphs</h2>
<p>Welcome geeks.</p>
<p>Hello geeks.</p>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# traverse paragraphs from soup
for data in soup.find_all("p"):
print(data.get_text())
Producción:
Welcome geeks. Hello geeks.
Ahora vamos a extraer párrafos de la URL dada.
Código:
Python3
# import module
import requests
import pandas as pd
from bs4 import BeautifulSoup
# link for extract html data
def getdata(url):
r = requests.get(url)
return r.text
htmldata = getdata("https://www.geeksforgeeks.org/")
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for data in soup.find_all("p"):
print(data.get_text())
Producción:
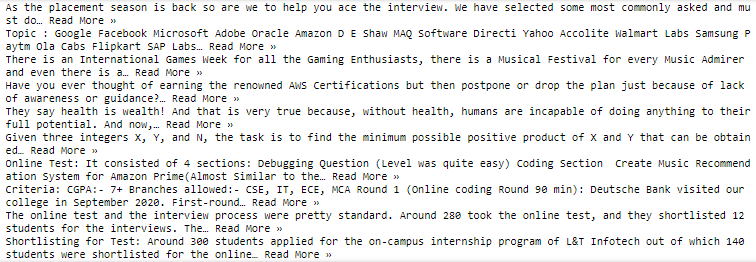
Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA