Una de las capacidades más utilizadas de las técnicas de aprendizaje automático supervisado es la clasificación de contenido, empleada en muchos contextos, como decir si una reseña de un restaurante determinada es positiva o negativa o inferir si hay un gato o un perro en una imagen. Esta tarea se puede dividir en tres dominios, clasificación binaria, clasificación multiclase y clasificación multietiqueta. En este artículo, explicaremos esos tipos de clasificación y por qué son diferentes entre sí y mostraremos un escenario de la vida real donde se puede emplear la clasificación multietiqueta.
Las diferencias entre los tipos de clasificaciones
- Clasificación binaria:
Se utiliza cuando solo hay dos clases distintas y los datos que queremos clasificar pertenecen exclusivamente a una de esas clases, por ejemplo, para clasificar si una publicación sobre un determinado producto es positiva o negativa; - Clasificación multiclase: Se utiliza cuando hay tres o más clases y los datos que queremos clasificar pertenecen exclusivamente a una de esas clases, por ejemplo, para clasificar si un semáforo en una imagen es rojo, amarillo o verde;
- Clasificación multietiqueta:
Se utiliza cuando hay dos o más clases y los datos que queremos clasificar pueden pertenecer a ninguna de las clases oa todas a la vez, por ejemplo, para clasificar qué señales de tráfico contiene una imagen.
Escenario de clasificación multietiqueta del mundo real
El problema que abordaremos en este tutorial es extraer el aspecto de las reseñas de restaurantes de Twitter. En este contexto, el autor del texto puede mencionar ninguno o todos los aspectos de una lista preestablecida, en nuestro caso esta lista está formada por cinco aspectos: servicio, comida, anécdotas, precio y ambiente. Para entrenar el modelo vamos a utilizar un conjunto de datos propuesto originalmente para una competencia en 2014 en el Taller Internacional de Evaluación Semántica, se conoce como SemEval-2014 y contiene datos sobre los aspectos en el texto y sus respectivas polaridades, para este tutorial solo estamos utilizando los datos sobre los aspectos, se puede encontrar más información sobre la competencia original y sus datos en su .
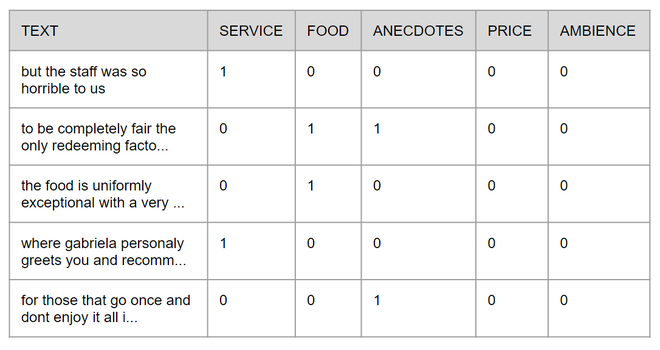
En aras de la simplicidad de este tutorial, el archivo XML original se convirtió en un archivo CSV que estará disponible en GitHub con el código completo . Cada fila está formada por el texto y los aspectos contenidos en él, la presencia o ausencia de esos aspectos se representa con 1 y 0 respectivamente, la siguiente imagen muestra cómo se ve la tabla.
Lo primero que debemos hacer es importar las bibliotecas requeridas, todas ellas se encuentran en el fragmento de código a continuación, si está familiarizado con el aprendizaje automático, probablemente reconocerá algunas de ellas.
Código: Importación de bibliotecas
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from skmultilearn.adapt import MLkNN from sklearn.metrics import hamming_loss, accuracy_score
Después de eso, tenemos que importar los textos y dividirlos adecuadamente para entrenar el modelo, sin embargo, el texto sin procesar en sí mismo no tiene mucho sentido para los algoritmos de aprendizaje automático, por esta razón, tenemos que representarlos de manera diferente, hay muchos diferentes formas para representar texto, aquí usaremos una técnica simple pero muy poderosa llamada TF-IDF que significa Frecuencia de término – Frecuencia de documento inversa, en pocas palabras, se usa para representar la importancia de cada palabra dentro de un corpus de texto, Puede encontrar más detalles sobre TF-IDF en este . En el siguiente código, asignaremos el conjunto de textos a X y los aspectos contenidos en cada texto a y, para convertir los datos de texto de fila a TF-IDF, crearemos una instancia de la clase TfidfVectorizer, usando la función fitpara proporcionarle el conjunto completo de textos para que luego podamos usar esta clase para convertir los conjuntos divididos y, finalmente, dividiremos los datos entre entrenar y probar usando el 70% de los datos para entrenar y manteniendo el resto para probar el modelo final y convertir cada uno de esos conjuntos usando la función transform de la instancia de TfidfVectorizer que hemos creado anteriormente.
Código:
aspects_df = pd.read_csv('semeval2014.csv')
X = aspects_df["text"]
y = np.asarray(aspects_df[aspects_df.columns[1:]])
# initializing TfidfVectorizer
vetorizar = TfidfVectorizer(max_features=3000, max_df=0.85)
# fitting the tf-idf on the given data
vetorizar.fit(X)
# splitting the data to training and testing data set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
# transforming the data
X_train_tfidf = vetorizar.transform(X_train)
X_test_tfidf = vetorizar.transform(X_test)
¡Ahora todo está configurado para que podamos instanciar el modelo y entrenarlo! Se pueden usar varios enfoques para realizar una clasificación multietiqueta, el empleado aquí será MLKnn, que es una adaptación del famoso algoritmo Knn, al igual que su predecesor MLKnn infiere las clases del objetivo en función de la distancia entre este y los datos de la base de entrenamiento pero asumiendo que puede pertenecer a ninguna o a todas las clases.
Código:
# using Multi-label kNN classifier mlknn_classifier = MLkNN() mlknn_classifier.fit(X_train_tfidf, y_train)
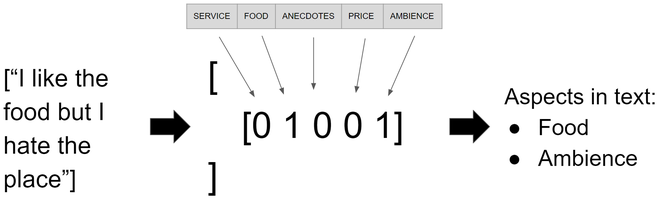
Una vez que el modelo esté entrenado, podemos realizar una pequeña prueba y ver cómo funciona con cualquier oración. Usaré la oración » Me gusta la comida pero odio el lugar», pero siéntete libre de usar las oraciones que quieras. Como hicimos con los datos de entrenamiento y prueba, necesitamos convertir el vector de nuevas oraciones a TF-IDF y luego usar la función de predicción de la instancia del modelo que nos proporcionará una array dispersa que se puede convertir en una array con el función toarray que devuelve una array de arrays donde cada elemento de cada array infiere la presencia de un aspecto como se muestra en la imagen 2.
Código:
new_sentences = ["I like the food but I hate the place"] new_sentence_tfidf = vetorizar.transform(new_sentences) predicted_sentences = mlknn_classifier.predict(new_sentence_tfidf) print(predicted_sentences.toarray())
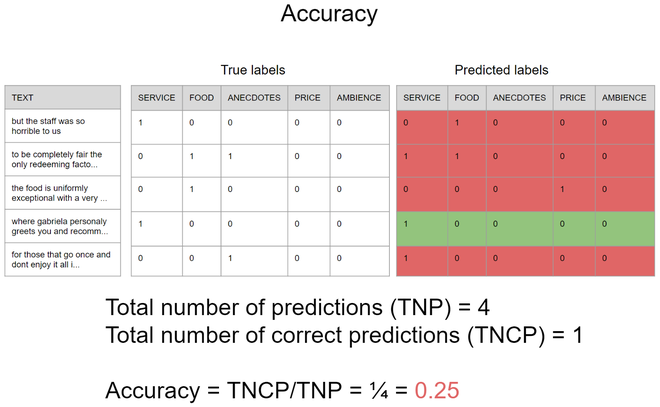
Ahora, tenemos que hacer una de las partes más importantes de la tubería de aprendizaje automático, la prueba. En esta parte, hay algunas diferencias significativas con los problemas multiclase, por ejemplo, no podemos usar la precisión de la misma manera porque una sola predicción infiere muchas clases al mismo tiempo, como en el escenario hipotético que se muestra en la imagen 3, tenga en cuenta que cuando se utiliza la precisión, solo las predicciones que son exactamente iguales a las etiquetas verdaderas se consideran predicciones correctas, por lo que la precisión es de 0,25, lo que significa que si intenta predecir los aspectos de 100 oraciones en solo 25 de ellas, la presencia y ausencia de todas los aspectos serían predichos correctamente al mismo tiempo.
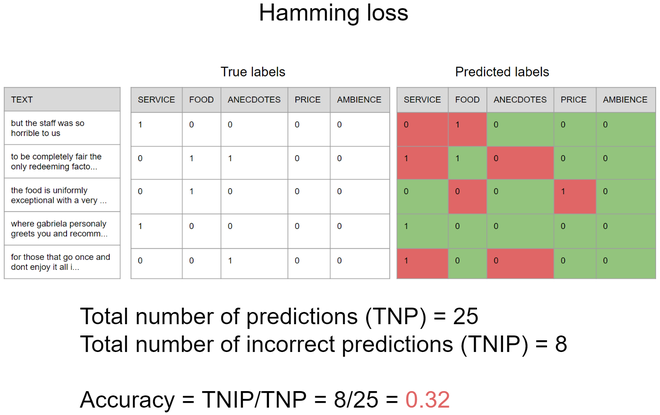
Por otro lado, hay una métrica más apropiada que se puede utilizar para medir qué tan bien el modelo predice la presencia de cada aspecto de forma independiente, esta métrica se llama pérdida de hamming y es igual al número de predicciones incorrectas dividido por el número total de predicciones donde la salida del modelo puede contener una o más predicciones, la siguiente imagen que usa el mismo escenario del último ejemplo ilustra cómo funciona, es importante tener en cuenta que la precisión en la pérdida de hamming es poco probable cuanto menor es el resultado mejor es el modelo. Por lo tanto, la pérdida de Hamming, en este caso, es 0,32, lo que significa que si intenta predecir los aspectos de 100 oraciones, el modelo predecirá incorrectamente alrededor del 32 % de los aspectos independientes.
Aunque la segunda métrica parece ser más adecuada para problemas como este, es importante tener en cuenta que todos los problemas de aprendizaje automático son diferentes entre sí, por lo que cada uno de ellos puede combinar un conjunto diferente de métricas para comprender mejor el rendimiento del modelo, como siempre. , No hay bala de plata. Para usarlos, vamos a usar el módulo de métricas de sklearn, que toma la predicción realizada por el modelo usando los datos de prueba y la compara con las etiquetas verdaderas.
Código:
predicted = mlknn_classifier.predict(X_test_tfidf) print(accuracy_score(y_test, predicted)) print(hamming_loss(y_test, predicted))
¡Así que ahora si todo está bien con una precisión cercana a 0,47 y una pérdida de hamming cercana a 0,16 !
Publicación traducida automáticamente
Artículo escrito por lucasfrota y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA