Twitter … Puede que seas bueno consultando estas redes sociales todo el tiempo, pero ¿qué pasa si alguien te pide que diseñes este gigantesco sistema en solo 45 minutos? ( ¿Es una broma… jajaja? ).
Sí, esto es lo que se espera que haga en la ronda de entrevistas de diseño de su sistema. No estamos bromeando y necesita contar su enfoque sobre el diseño de un sistema como Twitter (en 45 minutos o menos) que tiene cientos de ingenieros de software trabajando en él durante una década. Diseñar Twitter (o Facebook feed o Facebook search…) es una pregunta bastante común que los entrevistadores hacen a los candidatos. Muchos candidatos tienen más miedo de esta ronda que de la ronda de codificación porque no tienen la idea de qué temas y compensaciones deben cubrir dentro de este período de tiempo limitado. En primer lugar, recuerde que la ronda de diseño del sistema es extremadamente abierta y no existe una respuesta estándar. Incluso para la misma pregunta, tendrá una discusión diferente con diferentes entrevistadores.

En este blog, discutiremos cómo diseñar un sitio web como Twitter, pero antes de continuar, queremos que lea el artículo «¿Cómo descifrar el diseño del sistema en las entrevistas?» . Le dará una idea de cómo es esta ronda, qué se espera que haga en esta ronda y qué errores debe evitar frente al entrevistador.
Ahora pasemos a la pregunta directa “ ¿Cómo diseñaría Twitter? ”
¿Cómo diseñarías Twitter?
No salte a los detalles técnicos inmediatamente cuando le hagan esta pregunta en sus entrevistas. No corra en una sola dirección, solo creará confusión entre usted y el entrevistador. La mayoría de los candidatos cometen errores aquí e inmediatamente comienzan a enumerar un montón de herramientas o marcos como MongoDB, Bootstrap, MapReduce, etc. Recuerde que su entrevistador quiere ideas de alto nivel sobre cómo resolverá el problema. No importa qué herramientas utilizará, sino cómo define el problema, cómo diseña la solución y cómo analiza el problema paso a paso.
Puedes ponerte en una situación en la que estás trabajando en proyectos de la vida real. En primer lugar, defina el problema y aclare el enunciado del problema. En esta pregunta, comprimiremos Twitter a su MVP (producto mínimo viable). Nadie espera que usted diseñe todo el servicio. Por lo tanto, solo diseñaremos las funciones principales de Twitter en lugar de todo.
1. Discuta sobre las características principales
Entonces, primero divida todo el sistema en varios componentes centrales y hable sobre algunas características principales. Si su entrevistador desea incluir otras características, las mencionará allí. Por ahora, vamos a considerar las siguientes características en Twitter…
- El usuario debería poder twittear en solo unos segundos.
- El usuario debería poder ver la(s) línea(s) de tiempo del Tweet
- Cronología: Esto se puede dividir en tres partes…
- Línea de tiempo del usuario: el usuario ve sus propios tweets y tweets retweet del usuario. Tweets que el usuario ve cuando visita su perfil.
- Línea de tiempo de inicio: Esto mostrará los tweets de las personas que siguen los usuarios. (Tuitea cuando aterrizas en twitter.com)
- Línea de tiempo de búsqueda: cuando el usuario busca algunas palabras clave o #etiquetas y ve los tweets relacionados con esas palabras clave en particular.
- El usuario debe poder seguir a otro usuario.
- Los usuarios deberían poder twittear a millones de seguidores en unos pocos segundos (5 segundos)
2. Solución ingenua (consultas de base de datos síncronas)
Para diseñar un gran sistema como Twitter primero hablaremos de la solución Naive. Eso nos ayudará a avanzar hacia una arquitectura de alto nivel. Puedes diseñar una solución para las dos cosas:
- Modelado de datos: puede usar una base de datos relacional como MySQL y puede considerar dos tablas , tabla de usuario (id, nombre de usuario) y una tabla de tweet [id, contenido, usuario (clave principal de la tabla de usuario)] . La información del usuario se almacenará en la tabla de usuarios y cada vez que un usuario twittee un mensaje, se almacenará en la tabla de tweets. Aquí también son necesarias dos relaciones. Una es que los usuarios pueden seguirse entre sí, la otra es que cada fuente tiene un propietario de usuario. Entonces habrá una relación de uno a muchos entre el usuario y la tabla de tweets.
- Servir feeds: debe obtener todos los feeds de todas las personas que sigue un usuario y mostrarlos en orden cronológico.
3. Limitación de la arquitectura (señalar el cuello de botella)
Tendrá que hacer una declaración de selección grande en la tabla de tweets para obtener todos los tweets de un usuario específico a quien esté siguiendo, y eso también está en orden cronológico. Hacer esto cada vez creará un problema porque la tabla de tweets tendrá un gran contenido con muchos tweets. Necesitamos optimizar esta solución para resolver este problema y para eso, pasaremos a la solución de alto nivel para este problema. Antes de eso, entendamos primero las características de Twitter.
4. Características de Twitter (Tráfico)
Twitter tiene 300 millones de usuarios activos diarios. En promedio, cada segundo se tuitean alrededor de 6.000 tuits en Twitter. Cada segundo 6, 00, 000 consultas realizadas para obtener los plazos. Cada usuario tiene en promedio 200 seguidores y algunos usuarios como algunas celebridades tienen millones de seguidores. Esta característica de twitter aclara los siguientes puntos…
- Twitter tiene mucha lectura en comparación con la escritura, por lo que debemos preocuparnos mucho más por la disponibilidad y la escala de la aplicación para la gran cantidad de lectura en Twitter.
- Podemos considerar la consistencia eventual para este tipo de sistema. Está completamente bien si un usuario ve el tweet de su seguidor un poco retrasado.
- El espacio no es un problema ya que los tweets están limitados a 140 caracteres.
Solución de alto nivel
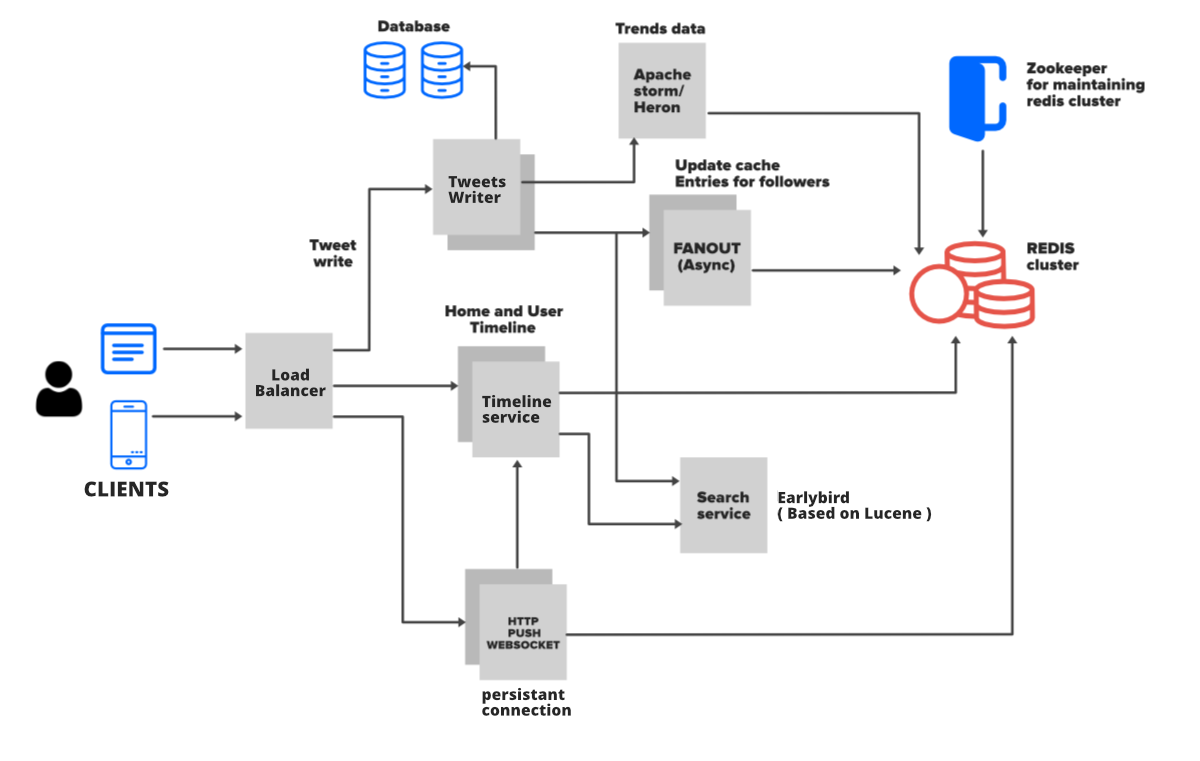
Como hemos discutido, Twitter tiene muchas lecturas, por lo que necesitamos un sistema que nos permita leer la información más rápido y que también pueda escalar horizontalmente. Redis es perfectamente adecuado para este requisito, pero no podemos depender únicamente de Redis porque también necesitamos almacenar una copia de los tweets y la información relacionada de otros usuarios en la base de datos. Así que aquí tendremos la arquitectura básica de Twitter que consta de tres tablas… Tabla de usuarios, Tabla de tuits y Tabla de seguidores .
- Siempre que un usuario cree un perfil en Twitter, la entrada se almacenará en la tabla Usuario.
- Los tuits enviados por un usuario se almacenarán en la tabla de tuits junto con el User_id. Además, la tabla Usuario tendrá relaciones de 1 a muchas con la tabla Tweet.
- Cuando un usuario sigue a otro usuario, se almacena en la tabla de seguidores y también lo almacena en caché Redis. La tabla Usuario tendrá relaciones de 1 a muchas con la tabla Seguidor.
1. Arquitectura de línea de tiempo del usuario
- Para obtener la línea de tiempo del usuario, simplemente vaya a la tabla de usuarios, obtenga el ID de usuario, haga coincidir este ID de usuario en la tabla de tweets y luego obtenga todos los tweets. Esto también incluirá retweets, guardar retweets como tweets con referencias de tweet originales. Una vez hecho esto, ordene el tweet por fecha y hora y luego muestre la información en la línea de tiempo del usuario.
- Como hemos discutido, Twitter tiene muchas lecturas, por lo que el enfoque anterior no funcionará siempre. Aquí necesitamos usar otra capa, es decir, la capa de almacenamiento en caché, y guardaremos los datos para las consultas de la línea de tiempo del usuario en Redis. Además, siga guardando los tweets en Redis, de modo que cuando alguien visite la línea de tiempo de un usuario, pueda obtener todos los tweets realizados por ese usuario. Obtener los datos de Redis es mucho más rápido, por lo que no sirve de mucho obtenerlos siempre de DB.
2. Arquitectura de la línea de tiempo del hogar
- Una línea de tiempo de inicio de usuario contiene todos los últimos tweets de la persona y las páginas que sigue el usuario. Bueno, aquí puede simplemente buscar a los usuarios a los que sigue un usuario, para cada seguidor buscar todos los tweets más recientes, luego combinar todos los tweets, ordenar todos estos tweets por fecha y hora y mostrarlos en la línea de tiempo de inicio. Esta solución tiene algunos inconvenientes . La página de inicio de Twitter se carga mucho más rápido y estas consultas son más pesadas en la base de datos, por lo que esta gran operación de búsqueda llevará mucho más tiempo una vez que la tabla de tweets crezca a millones. Hablemos ahora de la solución para este inconveniente…
Enfoque Fanout: Fanout simplemente significa distribuir los datos desde un solo punto. Veamos cómo usarlo. Cada vez que un usuario (Followee) hace un tweet, haga mucho preprocesamientoy distribuir los datos en diferentes líneas de tiempo de inicio de usuarios (seguidores). En este proceso, no tendrás que realizar ninguna consulta a la base de datos. Solo necesita ir al caché por user_id y acceder a los datos de la línea de tiempo de inicio en Redis. Entonces este proceso será mucho más rápido y fácil porque es una memoria en la que obtenemos la lista de tweets. Aquí está el flujo completo de este enfoque…- El usuario X es seguido por tres personas y este usuario tiene un caché llamado línea de tiempo del usuario. X tuiteó algo.
- A través de Load Balancer, el tweet fluirá hacia los servidores back-end.
- El Node del servidor guardará el tweet en DB/caché
- El Node del servidor obtendrá todos los usuarios que siguen al Usuario X desde el caché.
- El Node del servidor inyectará este tweet en las líneas de tiempo en memoria de sus seguidores (fanout)
- Todos los seguidores del Usuario X verán el tweet del Usuario X en su línea de tiempo. Se actualizará cada vez que un usuario visite su línea de tiempo.
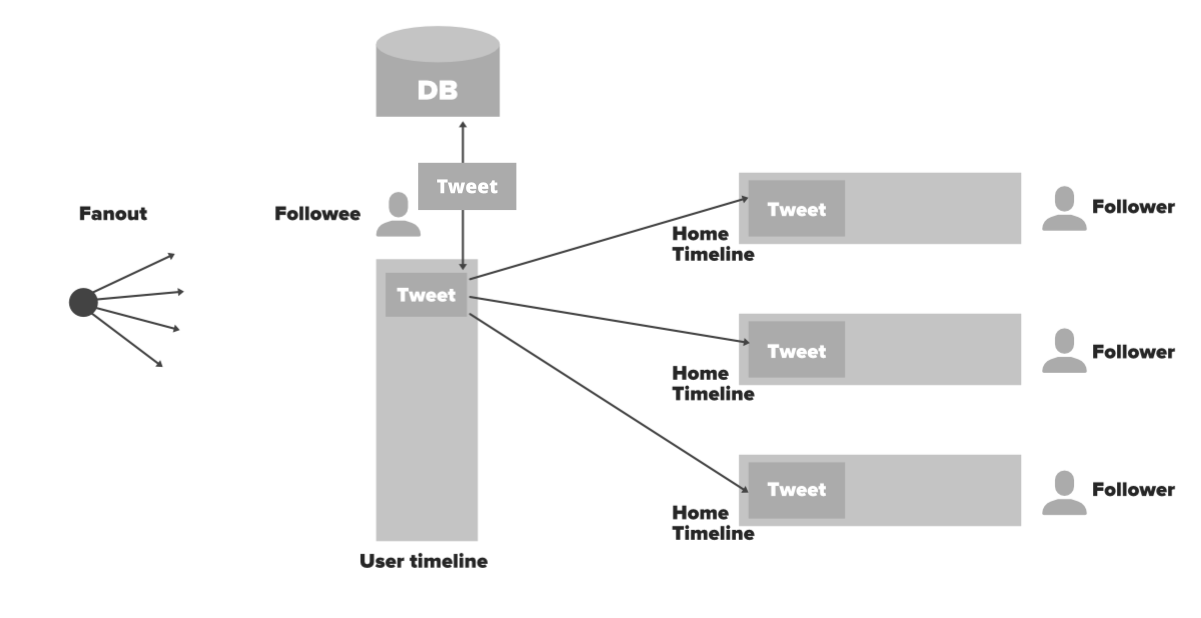
¿Qué pasará si una celebridad tiene millones de seguidores? ¿Es el método anterior eficiente en este escenario?
Debilidad (caso límite): el entrevistador puede hacer la pregunta anterior. Si hay una celebridad que tiene millones de seguidores, Twitter puede tardar entre 3 y 44 minutos en enviar un tweet de Eminem (una celebridad) a sus millones de seguidores. Tendrá que actualizar los millones de líneas de tiempo de inicio de seguidores que no son escalables. Aquí está la solución…
Solución [Enfoque mixto (en memoria + llamadas sincrónicas)]:
- Calcule previamente la línea de tiempo de la casa del Usuario A (seguidor de Eminem) con todos excepto el(los) tweet(s) de Eminem
- Para cada usuario, se mantiene la lista de celebridades en el caché, así como a las que sigue ese usuario. Cuando llegue la solicitud (tweet de la celebridad), puede obtener la celebridad de la lista, obtener el tweet de la línea de tiempo del usuario de la celebridad y luego mezclar el tweet de la celebridad en tiempo de ejecución con otros tweets del Usuario A.
- Entonces, cuando el Usuario A accede a su línea de tiempo de inicio, su fuente de tweet se fusiona con el tweet de Eminem en el momento de la carga. Entonces, el tweet de la celebridad se insertará en tiempo de ejecución.
Otra optimización: para usuarios inactivos, no calcule la línea de tiempo. Personas que no inician sesión en el sistema durante bastante tiempo (digamos más de 20 días).
3. Buscando
Twitter maneja la búsqueda de sus tweets y #tags utilizando Earlybird, que es un índice inverso en tiempo real basado en Lucene. Early Bird realiza una operación de indexación de texto completo invertida . Significa que cada vez que se publica un tweet, se trata como un documento. El tweet se dividirá en etiquetas, palabras y #tags, y luego estas palabras se indexarán. Esta indexación se realiza en una tabla grande o tabla distribuida. En esta tabla, cada palabra tiene una referencia a todos los tweets que contienen esa palabra en particular. Dado que el índice es una coincidencia de string exacta, desordenada, puede ser extremadamente rápido. Supongamos que si un usuario busca ‘ elección ‘, si revisa la tabla, encontrará la palabra ‘ elección ‘‘, luego descubrirá todas las referencias a todos los tweets en el sistema, luego da todos los resultados que contienen la palabra ‘ elección ‘.
Twitter maneja miles de tweets por segundo, por lo que no puede tener un solo gran sistema o tabla para manejar todos los datos, por lo que debe manejarse a través de un enfoque distribuido. Twitter utiliza la estrategia de dispersión y recopilación donde configura los múltiples servidores o centros de datos que permiten la indexación. Cuando Twitter recibe una consulta (digamos #geeksforgeeks), envía la consulta a todos los servidores o centros de datos y consulta cada fragmento de Early Bird . Todos los madrugadores que coincidan con la consulta devuelven el resultado. Los resultados se devuelven, ordenan, fusionan y vuelven a clasificar. La clasificación se realiza en función del número de retuits, respuestas y popularidad de los tuits.
Hasta ahora hemos hablado de todas las características y componentes principales de Twitter. Hay algunos otros componentes detallados de los que puede hablar. Por ejemplo, puede hablar sobre tendencias/temas de tendencia (usando Apache Storm y el marco de Heron), puede hablar sobre notificaciones y cómo incorporar publicidad .
Curso de diseño de sistemas GeeksforGeeks
¿Quiere conseguir un trabajo de desarrollador/ingeniero de software en una empresa de tecnología líder? o ¿Quiere hacer una transición sin problemas de SDE I a SDE II o perfiles de desarrollador sénior? En caso afirmativo, ¡entonces debe sumergirse profundamente en el mundo del diseño de sistemas! Un dominio decente sobre los conceptos de diseño de sistemas es muy esencial, especialmente para los profesionales que trabajan, para obtener una ventaja muy necesaria sobre los demás durante las entrevistas técnicas.

Y es por eso que GeeksforGeeks le brinda un Diseño de sistemas en vivo centrado en una entrevista en profundidad que lo ayudará a prepararse para las preguntas relacionadas con Diseños de sistemas para Google, Amazon, Adobe, Uber y otras empresas basadas en productos.
Publicación traducida automáticamente
Artículo escrito por anuupadhyay y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA