¿Qué es ScrapingHub?
Scrapy es un marco de código abierto para el rastreo web. Este marco está escrito en python y originalmente hecho para web scraping. El raspado web también se puede utilizar para extraer datos mediante API. ScrapingHub proporciona el servicio completo para rastrear los datos de las páginas web, incluso para páginas web complejas.
¿Por qué ScrapingHub?
Digamos un sitio web que proporciona un campo de entrada y, a cambio, obtiene una respuesta basada en la consulta de búsqueda. El motivo es obtener todos los datos ingresando la entrada y obteniendo la respuesta. Ahora, este campo de entrada puede tener números desde la string «0000» hasta la string «9999», por lo que, en resumen, debe proporcionar 10000 entradas para que se puedan obtener todos los resultados del sitio web. Ahora, para cada solicitud, digamos para «0000», tomará de 4 a 5 minutos y en respuesta obtendrá más de 1000 campos de datos. Puede variar porque al final, el sitio web devolverá todos los datos cuyos números terminan en «0000» y el sitio web tarda en consultarlo y devolverlo. Entonces, si hacemos algunas matemáticas, entonces, 10000 * 5 = 50000 minutos, lo que significa 35 días aprox.
Entonces, para empezar, uno puede usar el módulo mechanize de Python 2.7 y consultarlo, pero al final, se necesitan 35 días para completar esto ejecutando la PC/computadora portátil sin parar. La otra solución es que se pueden usar subprocesos múltiples y procesamiento múltiple para evitar tal escenario, pero guardar datos de manera organizada y superar esta complejidad llevará mucho tiempo. Pero usar Scrapy ahorrará una gran cantidad de tiempo. Aún así, necesitamos ejecutar este script durante al menos 1-3 días porque estamos hablando de extraer millones de datos. Entonces, para superar este problema, la mejor opción disponible es tomar la ayuda de ScrapingHub .
ScrapingHub proporciona funciones para implementar la araña Scrapy en la nube y ejecutarla. A cambio, ejecutará nuestra araña durante 24 horas (usuario gratuito) o 7 días (de pago), lo que vale la pena hacerlo. Es por eso que uno puede usar ScrapingHub para ahorrar tiempo y costos al hacerlo.
Como hacer esto :
Paso 1: Creando Spider en la máquina local
En el artículo anterior , creamos una araña simple para rastrear la página web y obtener todas las URL presentes en ese sitio web. Del mismo modo, simplemente agregue una característica adicional, que evitará raspar la URL duplicada manteniendo el conjunto en el script y verificando antes de agregarlo.
# importing scrapy module
import scrapy
class ExtractUrls(scrapy.Spider):
# Name of the spider
crawled = set()
# Set to avoiding duplicate url
name = "extract"
def start_requests(self):
# Starting url mentioned
urls = ['https://www.geeksforgeeks.org', ]
for url in urls:
yield scrapy.Request(url = url,
callback = self.parse)
def parse(self, response):
title = response.css('title::text').extract_first()
links = response.css('a::attr(href)').extract()
for link in links:
yield
{
'title': title,
'links': link
}
if ('geeksforgeeks' in link and
link not in self.crawled):
self.crawled.update(link)
yield scrapy.Request(url = link,
callback = self.parse)
scrapy crawl extract -o links.json
Después de ejecutar esta araña, debería poder rasparse con éxito y guardarla dentro de links.json. Pero necesitamos ahorrar tiempo y queremos ejecutarla durante al menos 24 horas. Así que implementaremos esta araña en ScrapingHub.
Paso 2: Crear una cuenta en ScrapingHub
Vaya a la página de inicio de sesión de ScrapingHub e inicie sesión con Google o Github. Se redirigirá al panel de control.

Ahora haga clic en Crear proyecto y mencione el nombre del proyecto. Haga clic en el botón Scrapy, porque nuestra araña está construida con el marco Scrapy.
Después de hacer clic, será redirigido al panel del proyecto y verá dos opciones para la implementación.
1. Implementación con CLI
2. Implementación con Github
Hágalo con CLIm porque es mucho más preferido. Así que volvamos a nuestro proyecto local para configurar algunos ajustes.
Paso 3: Configuración
pip install shub
shub login
shub deploy ID
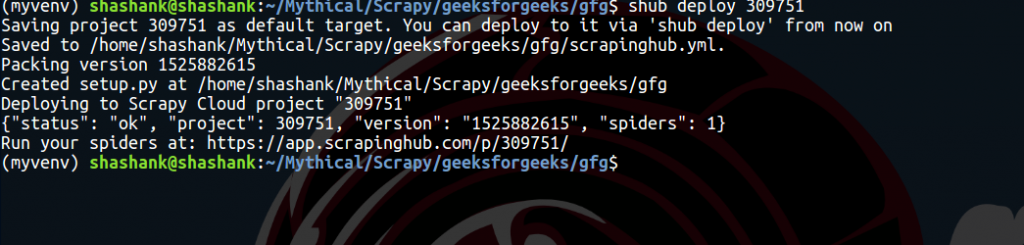
En la sección del tablero de Arañas, el usuario puede ver la araña lista. Simplemente haga clic en el nombre de la araña y en el botón Ejecutar. Los usuarios gratuitos obtendrán 1 unidad gratis, lo que indica que el usuario puede ejecutar una araña durante un máximo de 24 horas. Después de eso, se detendrá automáticamente. El usuario puede comprar las unidades para extender el período de tiempo.
Al hacer clic en los elementos de la sección Trabajo en ejecución, se redirigirá a otra página que mostrará todos los elementos que se rasparon en ese momento. La sección de trabajo mostrará un gráfico; mostrando estadísticas sobre la araña. Este gráfico es una visualización perfecta después de ejecutar la araña durante 5-6 horas.

Para obtener los datos en la máquina local, vaya a la sección Elementos y allí, en la parte superior derecha, haga clic en el botón Exportar. Mostrará varios formatos como: CSV, JSON, líneas JSON, XML. Vale la pena señalar que esta función es realmente útil y realmente ahorra mucho tiempo.

Usando ScrapingHub, uno puede raspar millones de datos en solo unos días, simplemente implementando la araña y descargándola en el formato preferido.
Nota: raspar cualquier página web no es una actividad legal. No realice ninguna operación de raspado sin permiso.
Publicación traducida automáticamente
Artículo escrito por shashank-sharma y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA