DataFrame La estructura de datos es el corazón de la biblioteca de Pandas. Los marcos de datos son básicamente objetos de serie de dos dimensiones. Tienen filas y columnas con filas que representan el índice y columnas que representan el contenido. Ahora, veamos cómo seleccionar todas las columnas, excepto una columna dada en Pandas Dataframe.
Primero, vamos a crear un marco de datos:
Python3
# import pandas library
import pandas as pd
# create a Dataframe
data = pd.DataFrame({
'course_name': ['Data Structures', 'Python',
'Machine Learning'],
'student_name': ['A', 'B',
'C'],
'student_city': ['Chennai', 'Pune',
'Delhi'],
'student_gender': ['M', 'F',
'M'] })
# show the Dataframe
data
Producción:
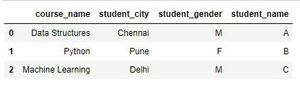
Marco de datos
Método 1: Usar Dataframe.loc[ ] .
Este marco de datos GeeksForGeeks es solo una array de dos dimensiones con índice numérico. Por lo tanto, para exceptuar solo una columna, podríamos usar los métodos de columnas para obtener todas las columnas y usar un operador not para excluir las columnas que no son necesarias. Este método funciona solo cuando el marco de datos no tiene múltiples índices (no tenía más de un índice).
Ejemplo: seleccione todas las columnas, excepto una columna ‘student_gender’ en Pandas Dataframe.
Python3
# import pandas library
import pandas as pd
# create a Dataframe
data = pd.DataFrame({
'course_name': ['Data Structures', 'Python',
'Machine Learning'],
'student_name': ['A', 'B',
'C'],
'student_city': ['Chennai', 'Pune',
'Delhi'],
'student_gender': ['M', 'F',
'M'] })
df = data.loc[ : , data.columns != 'student_gender']
# show the dataframe
df
Producción:
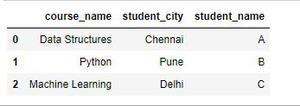
columna de estudiante_género filtrada
Método 2: Usar el método drop() .
Dataframe admite el método drop() para eliminar una columna en particular. Acepta dos argumentos, nombre de columna/fila y eje
Ejemplo: Seleccione todas las columnas, excepto una columna ‘student_city’ en Pandas Dataframe.
Python3
# import pandas library
import pandas as pd
# create a Dataframe
data = pd.DataFrame({
'course_name': ['Data Structures', 'Python',
'Machine Learning'],
'student_name': ['A', 'B',
'C'],
'student_city': ['Chennai', 'Pune',
'Delhi'],
'student_gender': ['M', 'F',
'M'] })
# drop method
df = data.drop('student_city',
axis = 1)
# show the dataframe
df
Producción:
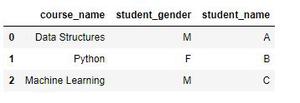
columna student_city eliminada
Método 3: Usar el método Series.difference() y el operador [ ] juntos.
El método Series.difference() devuelve un nuevo índice con elementos del índice que no están en otro.
Ejemplo: seleccione todas las columnas, excepto una columna ‘student_name’ en Pandas Dataframe.
Python3
# import pandas library
import pandas as pd
# create a Dataframe
data = pd.DataFrame({
'course_name': ['Data Structures', 'Python',
'Machine Learning'],
'student_name': ['A', 'B',
'C'],
'student_city': ['Chennai', 'Pune',
'Delhi'],
'student_gender': ['M', 'F',
'M'] })
df = data[data.columns.difference(['student_name'])]
# show the dataframe
df
Producción:
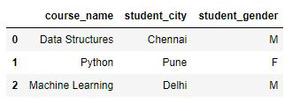
columna de nombre de estudiante filtrada
Publicación traducida automáticamente
Artículo escrito por vijayalakshmivenkataraman y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA