Diseño del sistema Dropbox … Es posible que haya utilizado este servicio de alojamiento de archivos varias veces para cargar y compartir archivos o imágenes, pero ¿qué sucede si alguien le pide que diseñe este sistema gigantesco en solo 45 minutos?

Sí, esto es lo que se espera que haga en la ronda de entrevistas de diseño de su sistema. No estamos bromeando, pero debe contar su enfoque sobre el diseño de un sistema como Dropbox (en 45 minutos o menos) que tiene cientos de ingenieros de software trabajando en él durante una década. Dropbox de diseño del sistema (o diseño de Google Drive o cualquier otro servicio de carga y uso compartido de archivos) es una cuestión bastante común en la ronda de diseño del sistema.
En este blog, discutiremos cómo diseñar un sitio web como Dropbox o Google Drive, pero antes de continuar, queremos que lea el artículo » ¿Cómo descifrar el diseño del sistema en las entrevistas?» “. Le dará una idea de cómo es esta ronda, qué se espera que haga en esta ronda y qué errores debe evitar frente al entrevistador.
Ahora pasemos a la pregunta directa «¿Cómo diseñarías Dropbox?»
¿Cómo diseñarías Dropbox?
No salte a los detalles técnicos inmediatamente cuando le hagan esta pregunta en sus entrevistas. No corra en una dirección, solo creará confusión entre usted y el entrevistador. La mayoría de los candidatos cometen errores aquí e inmediatamente comienzan a enumerar un montón de herramientas, marcos o bases de datos. Recuerde que su entrevistador quiere ideas de alto nivel sobre cómo resolverá el problema. No importa qué herramientas utilizará, sino cómo define el problema, cómo diseña la solución y cómo analiza el problema paso a paso.
En este blog, en lugar de hablar mucho sobre el tipo de servicios web, supondremos que hay un cliente de sincronización instalado en su computadora o sistema y que ese cliente siempre está buscando en carpetas de sincronización particulares en las que siempre está monitoreando los cambios en el archivos y lo sube. Además, no hablaremos de cómo construimos el almacenamiento en la nube. Usaremos algunos servicios de almacenamiento en la nube como Amazon S3 o cualquier otro servicio de almacenamiento que mantenga el archivo en la nube.
1. Discuta sobre las características principales
Antes de saltar a la solución, siempre aclare todas las suposiciones que está haciendo al comienzo de la entrevista. Haga preguntas para identificar el alcance del sistema. Esto despejará la duda inicial y conocerá cuáles son los detalles específicos que el entrevistador quiere considerar en este servicio. Así que comience con las características principales de Dropbox para discutirlas con los entrevistadores. Si los entrevistadores quieren agregar algunas características más (como la integración de API), se lo harán saber.
- El usuario debe poder cargar/descargar, actualizar y eliminar los archivos
- Versionado de archivos (Historial de actualizaciones)
- Sincronización de archivos y carpetas
2. Tráfico
- Más de 12 millones de usuarios únicos
- 100 millones de requests por día con muchas lecturas y escrituras.
3. Discutir el enunciado del problema
Mucha gente asume que diseñar un Dropbox es que todo lo que necesitan hacer es usar algunos servicios en la nube, cargar el archivo y descargarlo cuando lo deseen, pero no es así como funciona. El problema central es “ ¿Dónde y cómo guardar los archivos? “.
Supongamos que quieres compartir un archivo que puede ser de cualquier tamaño (pequeño o grande) y lo subes a la nube. Todo está bien hasta aquí, pero más adelante, si tiene que realizar una actualización en su archivo, no es una buena idea editar el archivo y cargar el archivo completo una y otra vez en la nube. La razón es…
- Más uso del ancho de banda y del espacio en la nube: para proporcionar un historial de los archivos, debe mantener varias versiones de los archivos. Esto requiere más ancho de banda y más espacio en la nube. Incluso para los pequeños cambios en su archivo, tendrá que hacer una copia de seguridad y transferir todo el archivo a la nube una y otra vez, lo que no es una buena idea.
- Utilización de latencia o simultaneidad: tampoco puede optimizar el tiempo. Llevará más tiempo cargar un solo archivo como un todo, incluso si realiza pequeños cambios en su archivo. Tampoco es posible hacer uso de la simultaneidad para cargar/descargar los archivos usando subprocesos múltiples o procesos múltiples.
Discutir la solución (solución de alto nivel)

Podemos dividir los archivos en varios fragmentos para superar el problema que discutimos anteriormente. No es necesario cargar/descargar todo el archivo único después de realizar cambios en el archivo. Solo necesita guardar el fragmento que se actualiza (esto requerirá menos memoria y tiempo). Será más fácil mantener las diferentes versiones de los archivos en varios fragmentos.
Hemos considerado un archivo que se divide en varios fragmentos. Si hay varios archivos, necesitamos saber qué fragmentos pertenecen a qué archivo. Para mantener esta información, crearemos un archivo más llamado archivo de metadatos . Este archivo contiene los índices de los fragmentos (nombres de fragmentos e información de pedidos). Debe mencionar el hash de los fragmentos (o alguna referencia) en este archivo de metadatos y debe sincronizar este archivo en la nube. Podemos descargar el archivo de metadatos de la nube cuando queramos y podemos recrear el archivo usando varios fragmentos.
Ahora hablemos de los diversos componentes para la solución completa de diseño del sistema del servicio de Dropbox.
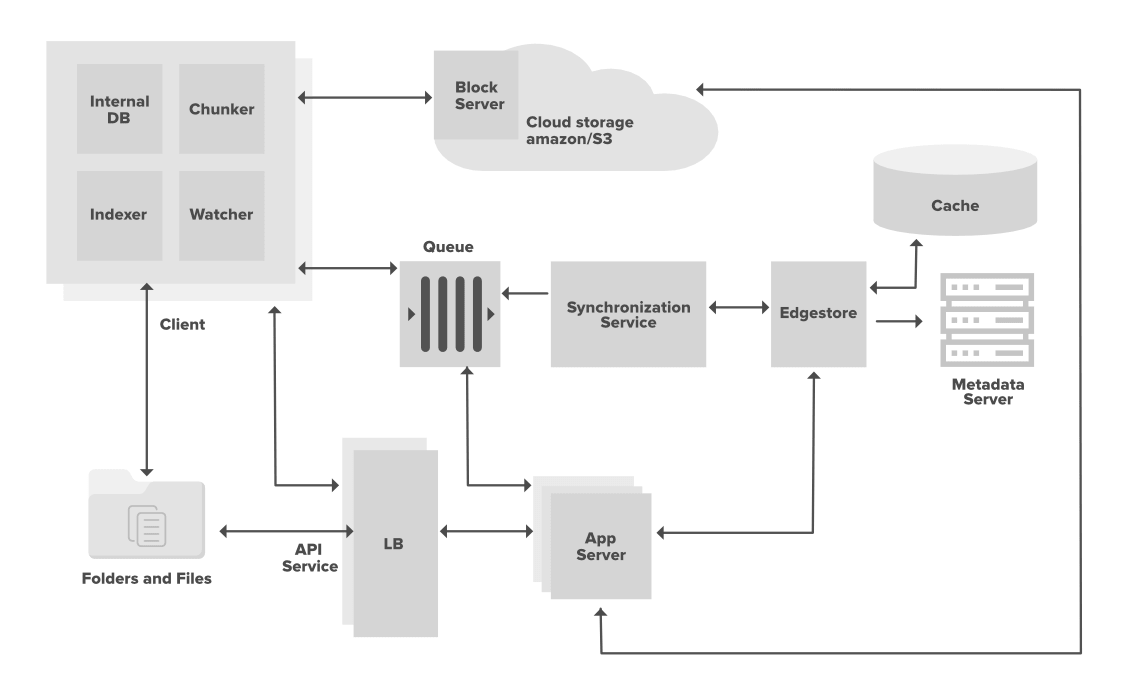
Supongamos que tenemos un cliente instalado en nuestra computadora (una aplicación instalada en su computadora) y este cliente tiene 4 componentes básicos. Estos componentes básicos son Watcher, Chunker, Indexer y Internal DB. Hemos considerado un solo cliente, pero puede haber múltiples clientes que pertenezcan al mismo usuario con los mismos componentes básicos.
- El cliente es responsable de cargar/descargar los archivos, identificar los cambios de archivos en la carpeta de sincronización y manejar los conflictos debido a actualizaciones simultáneas o fuera de línea.
- El cliente está monitoreando activamente las carpetas para todas las actualizaciones o cambios que ocurren en los archivos.
- Para manejar las actualizaciones de metadatos de archivos (por ejemplo, nombre de archivo, tamaño, fecha de modificación, etc.), este cliente interactúa con los servicios de mensajería y el servicio de sincronización.
- También interactúa con el almacenamiento remoto en la nube (Amazon S3 o cualquier otro servicio en la nube) para almacenar los archivos reales y proporcionar sincronización de carpetas.
Discutir los componentes del cliente
- Watcher es responsable de monitorear la carpeta de sincronización para todas las actividades realizadas por el usuario, como crear, actualizar o eliminar archivos/carpetas. Notifica al indexador y al fragmentador si se realiza alguna acción en los archivos o carpetas.
- Chunker divide los archivos en varias piezas pequeñas llamadas fragmentos y los carga en el almacenamiento en la nube con una identificación única o hash de estos fragmentos. Para recrear los archivos, estos fragmentos se pueden unir. Para cualquier cambio en los archivos, el algoritmo de fragmentación detecta el fragmento específico que se modifica y solo guarda esa parte o fragmentos específicos en el almacenamiento en la nube. Reduce el uso de ancho de banda, el tiempo de sincronización y el espacio de almacenamiento en la nube.
- Indexer es responsable de actualizar la base de datos interna cuando recibe la notificación del observador (para cualquier acción realizada en carpetas/archivos). Recibe la URL de los fragmentos del chunker junto con el hash y actualiza el archivo con fragmentos modificados. Indexer se comunica con el servicio de sincronización mediante el servicio de Message Queue Server, una vez que los fragmentos se envían correctamente al almacenamiento en la nube.
- La base de datos interna almacena toda la información de archivos y fragmentos, sus versiones y su ubicación en el sistema de archivos.
Discutir los otros componentes
1. Base de datos de metadatos
La base de datos de metadatos mantiene los índices de los diversos fragmentos. La información contiene nombres de archivos/fragmentos, sus diferentes versiones junto con la información de los usuarios y el espacio de trabajo. Puede usar RDBMS o NoSQL, pero asegúrese de cumplir con la propiedad de consistencia de datos porque varios clientes trabajarán en el mismo archivo. Con RDBMS no hay problema con la consistencia, pero con NoSQL obtendrá una consistencia eventual. Si decide usar NoSQL, entonces necesita hacer diferentes configuraciones para diferentes bases de datos (por ejemplo, el factor de replicación de Cassandra proporciona el nivel de consistencia).
Las bases de datos relacionales son difíciles de escalar, por lo que si está utilizando la base de datos MySQL, debe usar una técnica de fragmentación de la base de datos (o una técnica maestro-esclavo) para escalar la aplicación. En la fragmentación de bases de datos, debe agregar varias bases de datos MySQL, pero será difícil administrar estas bases de datos para cualquier actualización o para cualquier información nueva que se agregará a las bases de datos. Para superar este problema, necesitamos construir un contenedor perimetral alrededor de las bases de datos fragmentadas. Este contenedor perimetral proporciona el ORM y el cliente puede usar fácilmente el ORM de este contenedor perimetral para interactuar con la base de datos (en lugar de interactuar directamente con las bases de datos).

2. Servicio de cola de mensajes
La cola del servicio de mensajería será responsable de la comunicación asíncrona entre los clientes y el servicio de sincronización.

A continuación se muestran los requisitos principales del servicio Message Queue Server.
- Capacidad para manejar muchas requests de lectura y escritura.
- Almacene muchos mensajes en una cola altamente disponible y confiable.
- Alto rendimiento y alta escalabilidad.
- Proporciona equilibrio de carga y elasticidad para varias instancias del servicio de sincronización.
Habrá dos tipos de colas de mensajería en el servicio.
- Cola de requests: Esta será una cola de requests global compartida entre todos los clientes. Cada vez que un cliente recibe alguna actualización o cambio en los archivos/carpetas, envía la solicitud a través de la cola de requests. Esta solicitud la recibe el servicio de sincronización para actualizar la base de datos de metadatos.
- Cola de respuesta: habrá una cola de respuesta individual correspondiente a los clientes individuales. El servicio de sincronización transmite la actualización a través de esta cola de respuesta y esta cola de respuesta entregará los mensajes actualizados a cada cliente y luego estos clientes actualizarán sus respectivos archivos en consecuencia. El mensaje nunca se perderá incluso si el cliente se desconecta de Internet (el beneficio de usar el servicio de cola de mensajes).
Estamos creando una cantidad n de colas de respuesta para una cantidad n de clientes porque el mensaje se eliminará de la cola una vez que lo reciba el cliente y debemos compartir el mensaje actualizado con los diversos clientes suscritos.
3. Servicio de sincronización
El cliente se comunica con los servicios de sincronización para recibir la última actualización del almacenamiento en la nube o para enviar las últimas requests/actualizaciones al almacenamiento en la nube.
El servicio de sincronización recibe la solicitud de la cola de requests de los servicios de mensajería y actualiza la base de datos de metadatos con los últimos cambios. Además, el servicio de sincronización transmite la última actualización a los otros clientes (si hay varios clientes) a través de la cola de respuesta para que el indexador del otro cliente pueda recuperar los fragmentos del almacenamiento en la nube y recrear los archivos con la última actualización. También actualiza la base de datos local con la información almacenada en la base de datos de metadatos. Si un cliente no está conectado a Internet o sin conexión durante algún tiempo, sondea el sistema en busca de nuevas actualizaciones tan pronto como se conecta.
4. Almacenamiento en la nube
Puede usar cualquier servicio de almacenamiento en la nube como Amazon S3 para almacenar los fragmentos de los archivos cargados por el usuario. El cliente se comunica con el almacenamiento en la nube para cualquier acción realizada en los archivos/carpetas utilizando la API proporcionada por el proveedor de la nube.
Muchos candidatos tienen más miedo de esta ronda que de la ronda de codificación porque no tienen la idea de qué temas y compensaciones deben cubrir dentro de este período de tiempo limitado. En primer lugar, recuerde que la ronda de diseño del sistema es extremadamente abierta y no existe una respuesta estándar. Incluso para la misma pregunta ( Diseño del sistema Dropbox ), tendrá una discusión diferente con diferentes entrevistadores.
Curso de diseño de sistemas GeeksforGeeks
¿Quiere conseguir un trabajo de desarrollador/ingeniero de software en una empresa de tecnología líder? o ¿Quiere hacer una transición sin problemas de SDE I a SDE II o perfiles de desarrollador sénior? En caso afirmativo, ¡entonces debe sumergirse profundamente en el mundo del diseño de sistemas! Un dominio decente sobre los conceptos de diseño de sistemas es muy esencial, especialmente para los profesionales que trabajan, para obtener una ventaja muy necesaria sobre los demás durante las entrevistas técnicas.

Y es por eso que GeeksforGeeks le brinda un Diseño de sistemas en vivo centrado en una entrevista en profundidad que lo ayudará a prepararse para las preguntas relacionadas con Diseños de sistemas para Google, Amazon, Adobe, Uber y otras empresas basadas en productos.
Publicación traducida automáticamente
Artículo escrito por anuupadhyay y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA