El análisis de JSON Dataset usando pandas es mucho más conveniente. Pandas le permite convertir una lista de listas en un marco de datos y especificar los nombres de las columnas por separado.
Un analizador JSON que transforma un texto JSON en otra representación debe aceptar todos los textos que se ajusten a la gramática JSON. Puede aceptar formularios o extensiones que no sean JSON. Una implementación puede establecer lo siguiente:
- límites en el tamaño de los textos que acepta,
- límites en la profundidad máxima de anidamiento,
- límites en el rango y la precisión de los números,
- establecer límites en la longitud y el contenido de caracteres de las strings.
Trabajar con grandes conjuntos de datos JSON puede deteriorarse, especialmente cuando son demasiado grandes para caber en la memoria. En casos como este, una combinación de herramientas de línea de comandos y Python puede ser una forma eficiente de explorar y analizar los datos.
Importación de archivos JSON:
La manipulación del JSON se realiza mediante la biblioteca de análisis de datos de Python, llamada pandas.
import pandas as pd
Ahora puede leer el JSON y guardarlo como una estructura de datos de pandas, usando el comando read_json.
pandas.read_json (path_or_buf=Ninguno, orient = Ninguno, typ=’frame’, dtype=True, convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False, precision_float=False, date_unit=Ninguno, encoding=Ninguno, líneas = Falso, tamaño de fragmento = Ninguno, compresión = ‘inferir’)
import pandas as pd # Creating Dataframe df = pd.DataFrame([['a', 'b'], ['c', 'd']], index =['row 1', 'row 2'], columns =['col 1', 'col 2']) # Indication of expected JSON string format print(df.to_json(orient ='split')) print(df.to_json(orient ='index'))
{"columns":["col 1", "col 2"],
"index":["row 1", "row 2"],
"data":[["a", "b"], ["c", "d"]]}
{"row 1":{"col 1":"a", "col 2":"b"},
"row 2":{"col 1":"c", "col 2":"d"}}
Convierta el objeto en una string JSON usando dataframe.to_json :
DataFrame.to_json (path_or_buf=Ninguno, orient=Ninguno, date_format=Ninguno, double_precision=10, force_ascii=True, date_unit=’ms’, default_handler=Ninguno, lines=False,pression=’infer’, index=True)
Lea el archivo JSON directamente desde el conjunto de datos:
import pandas as pd
data = pd.read_json('http://api.population.io/1.0/population/India/today-and-tomorrow/?format = json')
print(data)
total_population
0 {'date': '2019-03-18', 'population': 1369169250}
1 {'date': '2019-03-19', 'population': 1369211502}
Análisis JSON anidado con Pandas:
Los archivos JSON anidados pueden llevar mucho tiempo y ser un proceso difícil de aplanar y cargar en Pandas.
Estamos usando «‘ raw_nyc_phil.json » anidado para crear un marco de datos de pandas aplanados a partir de una array anidada y luego desempaquetar una array profundamente anidada.
Código n.º 1:
descomprimamos la columna de trabajo en un marco de datos independiente. También agarraremos las columnas planas.
import json
import pandas as pd
from pandas.io.json import json_normalize
with open('https://github.com/a9k00r/python-test/blob/master/raw_nyc_phil.json') as f:
d = json.load(f)
# lets put the data into a pandas df
# clicking on raw_nyc_phil.json under "Input Files"
# tells us parent node is 'programs'
nycphil = json_normalize(d['programs'])
nycphil.head(3)
Producción:
Código n.º 2:
descomprimamos la columna de trabajo en un marco de datos independiente usando json_normaliz .
works_data = json_normalize(data = d['programs'], record_path ='works', meta =['id', 'orchestra', 'programID', 'season']) works_data.head(3)
Producción: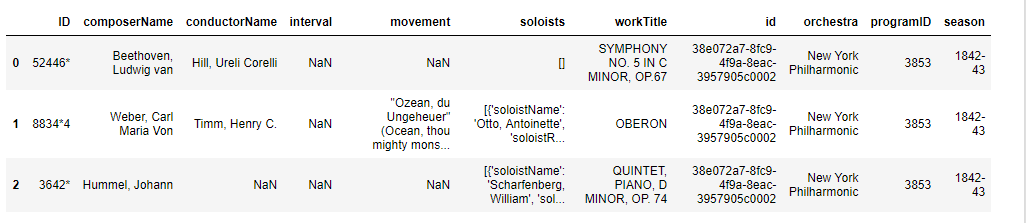
Código #3:
Aplanemos los datos de ‘solistas’ aquí pasando una lista. Dado que los solistas se anidan en el trabajo.
soloist_data = json_normalize(data = d['programs'], record_path =['works', 'soloists'], meta =['id']) soloist_data.head(3)
Producción:
Publicación traducida automáticamente
Artículo escrito por ankurtripathi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA