En Excel, tiene un montón de métodos para observar los tipos específicos de valores, pero el método óptimo elegido es lo que crea la diferencia. Entonces, ¿qué mentalidad necesitamos para usar métodos de búsqueda específicos en una situación? Eso es lo que vamos a ver aquí. Pero, primero, echemos un vistazo a un ejemplo de la vida real por qué es necesario elegir el enfoque más óptimo para las búsquedas.
Ejemplo:
Suponga que trabaja en una empresa, donde muchas hojas de ingresos (o recibos) y hojas de actualización de empleados regulares llegan regularmente, pero la disponibilidad de computadoras en esa región es casi NULA. Entonces, usará sus sentidos para calcular estas hojas. Ahora, tiene muchos enfoques, ya sea para leer el total de ingresos en cada hoja columna por columna, o fila por fila, o calcular números pequeños primero, y luego sumar o restar (según una hoja) números grandes de ellos, use calculadoras para computar las hojas, y las vías se irán haciendo más amplias, y más en número. Ahora, si intenta calcular las hojas de empleados regulares, que contienen el desempeño regular de los empleados junto con el salario diario que recibieron, y si alguien dejó la empresa o no. Aquí también son posibles muchos enfoques, ya que contienen nombres, números, porcentajes, etc.
Entonces, también en Excel, debe elegir la forma más adecuada de buscar los valores en Excel. Pero primero, echemos un vistazo a las formas que tenemos para buscar valores en Excel.
- BUSCARV
- BUSCARH
- ÍNDICE DE COINCIDENCIA
- COINCIDIR BUSCARV
- PARTIDO DE COMPENSACIÓN
Ahora, veámoslos brevemente:
1.BUSCARV
Vlookup, como sugiere el nombre, busca los datos de forma vertical, es decir, buscará los datos en la(s) columna(s). Aquí, la V mayúscula significa la búsqueda vertical de datos. Este método es el método clásico para realizar búsquedas. Su único propósito es devolver el valor tomando la referencia de la primera columna de la tabla. Su uso es bastante simple, y la sintaxis para usar este método será:
VLOOKUP (the value to be searched, range of table onto which values will be searched,
Numerical value of column from which data will be retrieved,
LOOKUP RANGE=TRUE/FALSE(OPTIONAL))
Ahora, comprenderemos mejor la sintaxis cuando veamos esto aplicado en un conjunto de datos. Entonces, un conjunto de datos de ejemplo aquí será el nombre del empleado, junto con sus ingresos generados por día, junto con su salario diario.
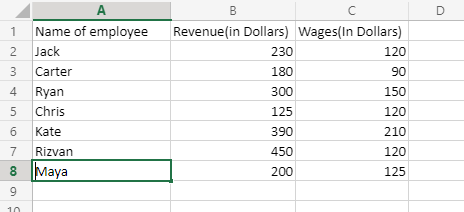
Ahora, desea averiguar cuánto ganó Kate hoy, por lo que usaremos la fórmula BUSCARV para obtener el valor. Entonces, la fórmula será:
=Vlookup(Kate;A2:C:8;2;FALSE)
Ahora, entenderemos por qué pasamos estos valores en los argumentos paso a paso:
- Pasamos a Kate como nuestro primer argumento, ya que se iban a obtener los ingresos de Kate, y BUSCARV siempre toma la referencia de la primera columna del conjunto de datos.
- El rango de valores que se recorrerá para obtener el valor es de A2 a C8, es decir, en resumen, estamos recorriendo todo el conjunto de datos, ya que dimos la coordenada de la celda inicial del conjunto de datos (excluyendo el nombre de la columna) y el último valor del conjunto de datos, es decir C8.
- La columna que almacenaba los ingresos de los empleados era la segunda columna, por lo que se pasó 2 en el tercer argumento.
- Ahora, este rango de búsqueda se ha establecido como falso, ya que no queremos que los valores se busquen de forma aproximada, queremos un valor preciso, por lo que el último argumento se establece como FALSO. En los casos en que desea que la salida sea casi exacta, establecemos este argumento como VERDADERO.
El punto importante a tener en cuenta sobre VLOOKUP es que solo sabe cómo buscar datos de izquierda a derecha.
La principal desventaja de BUSCARV es que no es compatible con el mundo dinámico, ya que nuestros conjuntos de datos cambiarán día a día. Entonces, para mejorar BUSCARV, usamos BUSCARV con otras funciones.
2.BUSCARH:
Así como V en BUSCARV significa búsqueda vertical en datos, H en BUSCARH significa búsqueda horizontal en datos. Su objetivo principal es devolver el valor deseado mirando de forma horizontal, es decir, en filas tomando como referencia el valor numérico de la primera fila. Su sintaxis es bastante familiar para la sintaxis de BUSCARV.
=HLOOKUP (the value to be searched,range of table onto which values will be searched,
index of row onto which value will be searched,
LOOKUP RANGE=TRUE/FALSE(OPTIONAL))
Ahora, considerando un conjunto de datos, en el que hacemos un seguimiento de cuántas copias de películas de acción se vendieron en días consecutivos, el conjunto de datos será:
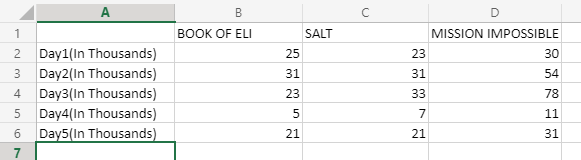
Ahora, su tarea es encontrar cuántas copias de «SALT» se vendieron el día 2. Entonces, aquí puede ver que la búsqueda de datos cambió de vertical a horizontal. Ahora, la fórmula será:
=HLOOKUP(SALT;B1:D6;2;FALSE)
Esto obtendrá el siguiente resultado:
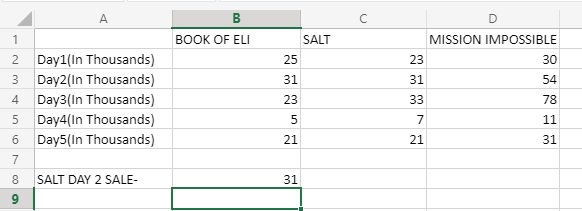
Ahora bien, ¿cómo funcionaba esta fórmula? Veámoslo mirando qué argumentos se pasan en la función HLOOKUP:
- El primer argumento fue el nombre de la película (o atributo) cuyo valor debe obtenerse.
- El segundo argumento toma el rango de tablas en las que se buscará el valor.
- El tercer argumento contendrá el número de filas, en qué valor se buscará, y en este caso, queremos la venta del día 2, y eso está en la fila 2 (teniendo en cuenta que comenzamos con B1 como nuestra fila inicial, por lo que esta fila será contarse como fila 2), por lo que 2 se pasa aquí.
- El cuarto argumento funciona igual que el cuarto argumento de BUSCARV, es decir, para ser exactos, pasamos FALSO, y también puede pasar el valor booleano de FALSO, es decir, 0 aquí.
BUSCARH no se usa con mucha frecuencia, ya que sus requisitos dicen que debe colocar el valor de búsqueda en la fila superior de la base de datos. Por lo tanto, al igual que BUSCARV, BUSCARH solo no es compatible con la configuración actual, por lo que usamos BUSCARH con diferentes métodos.
3. COINCIDENCIA DE ÍNDICE:
La coincidencia de índice utiliza dos propiedades principales, es decir, «ÍNDICE» y «COINCIDIR». Estos dos, cuando se combinan, pueden hacer que los criterios de búsqueda (búsqueda) sean más flexibles, es decir, no más restricciones, puede usar este método para búsquedas verticales, este método para búsquedas horizontales, etc. INDEX MATCH elimina esto y hace que el proceso de búsqueda mas flexible.
Ahora, para comprender este método, veremos dos ejemplos, cada uno perteneciente a INDEX y MATCH.
Función ÍNDICE: la función ÍNDICE es bastante básica y su función es devolver el valor en esa celda, cuyo valor se especifica en los argumentos de la función. Entonces, echemos un vistazo a su sintaxis:
INDEX(Range of table you want to search the value;
numerical value of row on which value is to be searched;
numerical value of column on which value is to be searched)
Ahora, veamos solo el conjunto de datos anterior y tratemos de entender cómo funciona INDEX. Suponga que desea saber cuánto ganó “Book of eli” el DÍA 3. Ahora, sabe que las entradas del día 3 se realizan en la tercera fila, y las entradas del libro de eli se realizan en la segunda columna, por lo que la fórmula se verá así:
=INDEX(A2:D6;3;2)
Ahora, la salida se verá así:
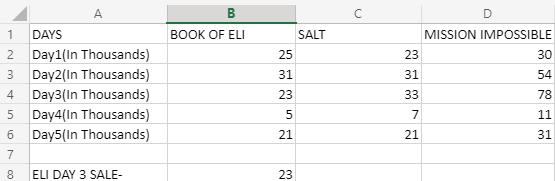
Ahora bien, ¿cómo funcionaba esta fórmula? Echemos un vistazo a lo que pasamos en los argumentos de la función ÍNDICE:
- A2:D6: Esto le dirá a INDEX dónde buscar en el conjunto de datos.
- 3: el número de fila en el que se buscará el valor (teniendo en cuenta que comenzamos con A2, por lo que en ese contexto, el número de fila se convierte en 3)
- 2: el número de columna en el que se buscará el valor.
Si está familiarizado con el concepto básico de la geometría de coordenadas, debería haber notado que nos devolvió el valor almacenado en la posición (3,2).
Ahora, pasando a la función de coincidencia,
Función MATCH: La función MATCH nos dirá cuál es la posición de un elemento, que se pasará como primer argumento de esta función, y es independiente de buscar de manera horizontal o vertical. Esta función es muy poderosa para encontrar valores en conjuntos de datos muy grandes. Ahora echemos un vistazo a un ejemplo de la función MATCH.
Considerando un conjunto de datos, donde hay nombres de estudiantes, y un estudiante ha dejado la escuela, y el nombre del estudiante es «RAJ MEHRA». Entonces, queremos saber dónde se encuentra en este conjunto de datos. El conjunto de datos utilizado será:
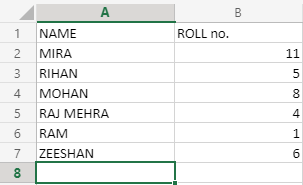
Ahora, aplicaremos nuestra función de coincidencia en el nombre de la columna «NOMBRE», y la fórmula se verá así:
MATCH("RAJ MEHRA";A2:A7;0)
Esto generará 4 como nuestra respuesta, ya que «RAJ MEHRA» está en la cuarta fila. Ahora bien, ¿cómo funcionaba esta fórmula? Veamos sus argumentos:
- ” RAJ MEHRA “: este argumento acepta una string, que se buscará en el rango de búsqueda dado.
- A2:A7: El rango en el que se buscará el valor.
- 0: este argumento es el mismo que vimos en BUSCARV O BUSCARH, y aquí establecemos este argumento como 0 o FALSO, lo que significa que queremos un comportamiento de coincidencia exacto con la string que pasamos. Este argumento, cuando se pasa como 1 o VERDADERO, será una aproximación para hacer coincidir con la string pasada.
Ahora, como entendimos INDEX, MATCH individualmente, ahora veremos a INDEX, MATCH en acción mutuamente, es decir, cómo funcionan juntos.
Teniendo en cuenta la versión ampliada del conjunto de datos que creamos en el ejemplo anterior, ahora agregaremos el área en la que estudian los estudiantes, es decir, en qué departamentos de estudio se encuentran. Entonces, el conjunto de datos será:
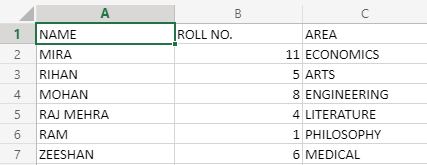
Ahora, la cuestión es que suponga que no sabe en qué fila están almacenados los datos de Mohan, pero desea obtener el área de estudio de MOHAN, por lo que aquí la función COINCIDIR ayudará a la FUNCIÓN ÍNDICE a ubicar el número de fila en el que se encuentra el valor. almacenado, tomando el nombre del estudiante en su primer argumento. La función de coincidencia se pasará como segundo argumento en la función ÍNDICE, ya que no conocemos el número de fila. Entonces, la fórmula de esto se verá así:
=INDEX(B2:C7;MATCH("MOHAN";A2:A7;0);3)
Esta fórmula utiliza tanto índice como coincidencia, lo que hace que esta fórmula sea muy eficiente.
La única desventaja que tiene es que no es compatible con conjuntos de datos muy grandes.
4.COINCIDENCIA DE BUSCARV:
Como sugiere el nombre, este dúo mejorará la capacidad de búsqueda (búsqueda) del método BUSCARV. Lo que estaba haciendo VLOOKUP es que estaba buscando solo de manera vertical, es decir, solo hacia abajo en el rango de columnas. Pero, como todos sabemos, esto no cumplirá con los requisitos de búsqueda en el mundo real. Ahora, utilizando este método, podemos buscar en forma 2D, es decir, en una array, en lugar de ir de arriba hacia abajo y seguir un método 1D. Como hemos entendido tanto BUSCARV como COINCIDIR por separado, entendamos este método directamente a partir de un ejemplo:
Ahora, considerando el mismo conjunto de datos creado en el ejemplo anterior, queremos saber el NÚMERO DE ROLLO. de Rihan. Entonces, usaremos el método BUSCARV para hacer esto. La fórmula para esto será:
=VLOOKUP("RIHAN";A1:C7;MATCH(B1,A1:C1))
Esto devolverá 5 como nuestra respuesta. Pero, como puede ver, usamos BUSCARV y descubrimos el valor que está contenido en la celda de otra columna. Entonces, aquí puedes ver la expansión de BUSCARV. Ahora bien, ¿cómo funcionó esta fórmula? Veámoslo argumento por argumento.
- “RIHAN”: Esta será la referencia, que BUSCARV tomará para buscar su valor.
- “A1:C7”: los rangos en los que se buscará el valor.
- “COINCIDIR (B1, A1: C1)”: esta parte hace que vlookup sea más flexible. Aquí, si observamos qué función de coincidencia devolverá, devolverá 2, ya que los números de rollo están contenidos en la segunda columna. Ahora, el rango de array en el que se buscará la columna, será A1 a C1, es decir, el nombre de la columna contenida fila.
Ahora, tan pronto como BUSCARV llegue a la celda donde se encuentra «RIHAN», la función de coincidencia dirigirá el control a la segunda columna, y aquí puede ver que BUSCARV cambia de búsqueda 1D a búsqueda 2D.
5. PARTIDO DE COMPENSACIÓN:
Para entender este concepto, necesitamos entender qué es la compensación.
Método OFFSET: Este método se utiliza principalmente en la búsqueda dinámica o, digamos, para alcanzar o apuntar a una celda específica, comenzando desde cualquier celda. es decir, para tomar referencia de esta celda. Y para llegar a alguna otra celda. El único requisito para que funcione la compensación es que su conjunto de datos debe ser una array 2d, no solo una celda o un conjunto de datos lineal. Ahora, echemos un vistazo a su sintaxis:
OFFSET(Starting cell;row offset;column offset;height for rows;height for columns)
Ahora, echemos un vistazo a cómo funcionan sus parámetros a través de un ejemplo. Para esto, debe tener una buena imagen de cómo se recorren las filas y las columnas en una array. Puede utilizar un conjunto de datos vacío como referencia.
Suponga que está parado en la celda B2 y quiere llegar a la celda E6, así que aquí puede ver que nuestra celda inicial es B2. Nuestro desplazamiento de fila, es decir, a cuántas filas está nuestra celda objetivo, por lo que en este caso, nuestro desplazamiento de fila es 4. Nuestro desplazamiento de columna, es decir, a cuántas columnas se encuentra nuestra celda objetivo, por lo que en este caso, nuestro desplazamiento de columna es 3. Entonces, nuestra fórmula de compensación se verá así:
=OFFSET(B2;4;3)
Ahora, también podemos hacer referencia a un rango de valores en nuestro conjunto de datos usando solo una celda, y en esto, también utilizaremos nuestros dos últimos parámetros.
Supongamos que desea hacer referencia a C2: C6, comenzando solo desde B2, por lo que en esta fila el desplazamiento será 0, ya que la celda inicial del rango, es decir, C2, está en la misma fila, como en B2. El desplazamiento de columna será 1, ya que la celda C2 está una columna por delante de la celda B2. La altura de las filas será el número de celdas contenidas en el rango dado, por lo que en C2 a C6, el rango de 5 celdas está cubierto, por lo que la altura de las filas tomará 5 como argumento. Para la altura de la columna, como sugiere el nombre, se refiere a cuántas celdas de manera horizontal se les da un rango de celdas que cubren. Como podemos ver, las columnas van de manera vertical, por lo que la altura de nuestra columna es 1. Para ser más precisos, la altura de las columnas no es otra que el ancho de las columnas que cubre su rango de valores. Así que la fórmula para esto será:
=OFFSET(B2;0;1;5;1)
En Excel, no se recomienda poner alto para las filas y alto para los valores negativos de la columna.
Ahora, veremos una combinación compensada trabajando juntos:
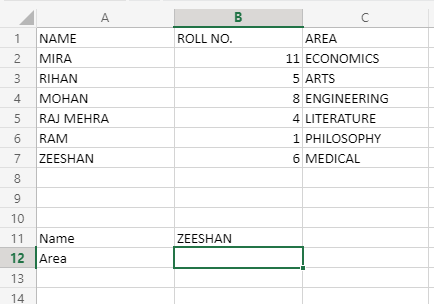
Teniendo en cuenta este conjunto de datos, queremos saber en qué área de estudio está estudiando Zeeshan. Entonces, primero, veamos cómo se ve la sintaxis de la coincidencia compensada:
=OFFSET(Reference cell,MATCH(RowLookupNumber,RowLookupRange,Boolean for matching precision),
MATCH(ColumnLookupNumber,ColumnLookupRange,Boolean for matching precision))
Para entender esta sintaxis, consideremos la situación anterior e intentemos averiguar el área de estudio en la que Zeeshan estudia usando la coincidencia de compensación. Entonces, la fórmula será:
=OFFSET(A1;MATCH("ZEESHAN";A2:A7;0);MATCH("AREA";A1:C1;0))
Poniendo esta fórmula en la celda B12, la respuesta será MÉDICA. Ahora, ¿cómo funciona esto? Entendámoslo argumento por argumento:
- A1: Esta es la referencia a partir de la cual se iniciará el desplazamiento para la búsqueda.
- «ZEESHAN»: Este es el valor de búsqueda que buscará la coincidencia en el rango dado.
- A2:A7: Este es el rango para el valor de búsqueda de filas, en este rango de coincidencias se buscará la palabra clave «ZEESHAN».
- 0: este argumento significará para la búsqueda precisa, lo que significa 0, y para la búsqueda aproximada, se pasa 1 aquí.
- «ÁREA»: este es el valor de búsqueda de columna que la coincidencia encontrará en el rango dado. Entonces, aquí puede ver, los parámetros de desplazamiento están siendo dirigidos por los valores de retorno de la coincidencia para buscar en forma 2D.
- A1:C1: este es el rango de búsqueda de columna, que será utilizado por coincidencia para buscar la columna denominada «ÁREA».
- 0: este argumento significará para la búsqueda precisa, lo que significa 0, y para la búsqueda aproximada, se pasa 1 aquí.
La principal ventaja que tiene este método, aparte de otros métodos, es que es un proceso de búsqueda mucho más rápido y que consume menos tiempo en Excel.
Ahora, veremos cómo podemos comparar dos tablas:
Comparación de Tablas:
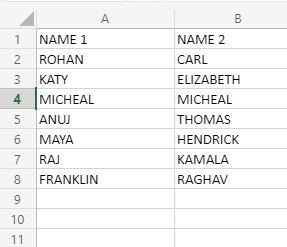
Ahora, supongamos que tenemos 2 tablas, nombre 1 y nombre 2, y estas representan empleados de 2 departamentos diferentes, por lo que, obviamente, su nombre no puede ser el mismo. Entonces, compararemos las 2 tablas usando nuestro concepto de comparación de tablas.
Entonces, aquí usaremos una fórmula IF muy básica para realizar la tarea anterior. Funciona como una declaración condicional «si», que se encuentra en la mayoría de los lenguajes de programación. Entonces, la fórmula para hacer la tarea anterior será:
=IF(A2=B2;"VERIFY";"CLEAR")
Ahora. cuando apliquemos esta fórmula en las celdas C2 a C8, el conjunto de datos resultante se verá así:
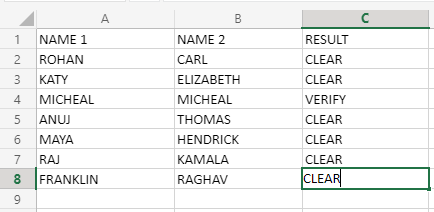
Ahora, trabajando con esta fórmula, ya que solo compara los 2 valores en las celdas correspondientes de las columnas A y B, y devuelve CLEAR, si los valores no coinciden; de lo contrario, devolverá VERIFY, como se devuelve al comparar A4 CON B4. Este proceso también se puede realizar, sin usar la fórmula IF, y simplemente comparando las celdas correspondientes de A y B. Esto devolverá un valor VERDADERO tradicional si se encuentra la coincidencia; de lo contrario, se devolverá FALSO. Entonces, la fórmula IF solo se usa cuando queremos fabricar nuestros valores de retorno.
Publicación traducida automáticamente
Artículo escrito por gs2000april y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA