Un marco de datos es una estructura de datos tabulares bidimensionales y de tamaño variable con ejes etiquetados (filas y columnas). Puede contener entradas duplicadas y para borrarlas hay varias formas.
Consideremos el siguiente conjunto de datos .
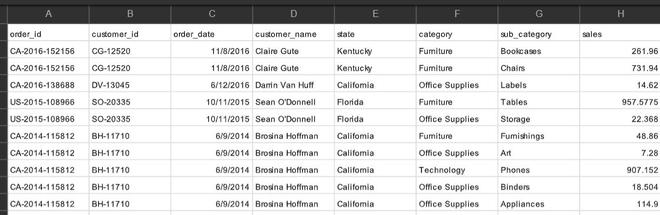
El marco de datos contiene valores duplicados en la columna order_id y customer_id. A continuación se muestran los métodos para eliminar valores duplicados de un marco de datos basado en dos columnas.
Método 1: usando drop_duplicates()
Acercarse:
- Soltaremos columnas duplicadas basadas en dos columnas
- Deje que esas columnas sean ‘order_id’ y ‘customer_id’
- Mantener solo la última entrada
- Restablecer el índice del marco de datos
A continuación se muestra el código Python para el enfoque anterior.
Python3
# import pandas library
import pandas as pd
# load data
df1 = pd.read_csv("super.csv")
# drop rows which have same order_id
# and customer_id and keep latest entry
newdf = df1.drop_duplicates(
subset = ['order_id', 'customer_id'],
keep = 'last').reset_index(drop = True)
# print latest dataframe
display(newdf)
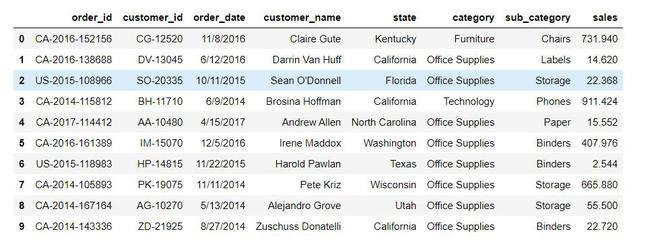
Producción:
Método 2: usando groupby()
Acercarse:
- Agruparemos filas en base a dos columnas.
- Deje que esas columnas sean ‘order_id’ y ‘customer_id’
- Mantener solo la primera entrada
El código Python para el enfoque anterior se proporciona a continuación.
Python3
# import pandas library
import pandas as pd
# read data
df1 = pd.read_csv("super.csv")
# group data over columns 'order_id'
# and 'customer_id' and keep first entry only
newdf1 = df1.groupby(['order_id', 'customer_id']).first()
# print new dataframe
print(newdf1)
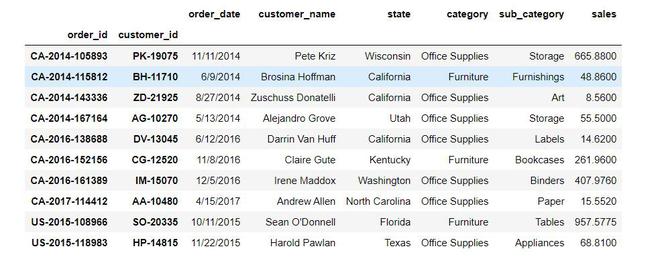
Producción:
Publicación traducida automáticamente
Artículo escrito por rohanchopra96 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA