Como sabemos, Python es un lenguaje adecuado para guionistas y desarrolladores. Escribamos un script para Personal Voice Assistant usando Python. La consulta para el asistente se puede manipular según la necesidad del usuario. El asistente implementado puede abrir la aplicación (si está instalada en el sistema), buscar en Google, Wikipedia y YouTube sobre la consulta, calcular cualquier pregunta matemática, etc. con solo dar el comando de voz . Podemos procesar los datos según la necesidad o podemos agregar la funcionalidad, depende de cómo codifiquemos las cosas. Estamos utilizando la API de reconocimiento de voz de Google y el texto a voz de Google para la entrada y salida de voz, respectivamente. Además, para calcular la expresión matemática se puede utilizar WolframAlpha API . Paquete de sonidose utiliza para reproducir el sonido mp3 guardado del sistema.
Requisitos del paquete externo de Python:
-> gTTS : Google Text To Speech, para convertir el texto dado a voz -> Speech_recognition : para reconocer el comando de voz y convertirlo en texto -> Selenium : para el trabajo basado en la web desde el navegador -> wolframalpha : para el cálculo proporcionado por el usuario -> playsound : para reproducir el archivo de audio guardado. -> playaudio – para motor de voz en python
Bueno, comencemos con el código. Dividiremos cada función como un solo código para facilitar su comprensión. Aquí está la función principal, con la función get_audio() y assist_speaks. Se crea la función get_audio() para obtener el audio del usuario que usa el micrófono, el límite de frase se establece en 5 segundos (puede cambiarlo). La función Asistente habla se crea para proporcionar la salida de acuerdo con los datos procesados.
Python3
# importing speech recognition package from google api
import speech_recognition as sr
import playsound # to play saved mp3 file
from gtts import gTTS # google text to speech
import os # to save/open files
import wolframalpha # to calculate strings into formula
from selenium import webdriver # to control browser operations
num = 1
def assistant_speaks(output):
global num
# num to rename every audio file
# with different name to remove ambiguity
num += 1
print("PerSon : ", output)
toSpeak = gTTS(text = output, lang ='en', slow = False)
# saving the audio file given by google text to speech
file = str(num)+".mp3
toSpeak.save(file)
# playsound package is used to play the same file.
playsound.playsound(file, True)
os.remove(file)
def get_audio():
rObject = sr.Recognizer()
audio = ''
with sr.Microphone() as source:
print("Speak...")
# recording the audio using speech recognition
audio = rObject.listen(source, phrase_time_limit = 5)
print("Stop.") # limit 5 secs
try:
text = rObject.recognize_google(audio, language ='en-US')
print("You : ", text)
return text
except:
assistant_speaks("Could not understand your audio, PLease try again !")
return 0
# Driver Code
if __name__ == "__main__":
assistant_speaks("What's your name, Human?")
name ='Human'
name = get_audio()
assistant_speaks("Hello, " + name + '.')
while(1):
assistant_speaks("What can i do for you?")
text = get_audio().lower()
if text == 0:
continue
if "exit" in str(text) or "bye" in str(text) or "sleep" in str(text):
assistant_speaks("Ok bye, "+ name+'.')
break
# calling process text to process the query
process_text(text)
Entonces, aquí tenemos una idea de cómo le damos voz a la máquina y tomamos información del usuario. El siguiente paso y el paso principal es cómo desea procesar su entrada. Este es solo un código básico, hay muchos otros algoritmos (NLP) que se pueden usar para procesar el texto de manera adecuada. Lo hemos hecho estático. Además, se ha utilizado Wolframalpha api para calcular la parte de cálculos.
Python3
def process_text(input):
try:
if 'search' in input or 'play' in input:
# a basic web crawler using selenium
search_web(input)
return
elif "who are you" in input or "define yourself" in input:
speak = '''Hello, I am Person. Your personal Assistant.
I am here to make your life easier. You can command me to perform
various tasks such as calculating sums or opening applications etcetra'''
assistant_speaks(speak)
return
elif "who made you" in input or "created you" in input:
speak = "I have been created by Sheetansh Kumar."
assistant_speaks(speak)
return
elif "geeksforgeeks" in input:# just
speak = """Geeks for Geeks is the Best Online Coding Platform for learning."""
assistant_speaks(speak)
return
elif "calculate" in input.lower():
# write your wolframalpha app_id here
app_id = "WOLFRAMALPHA_APP_ID"
client = wolframalpha.Client(app_id)
indx = input.lower().split().index('calculate')
query = input.split()[indx + 1:]
res = client.query(' '.join(query))
answer = next(res.results).text
assistant_speaks("The answer is " + answer)
return
elif 'open' in input:
# another function to open
# different application available
open_application(input.lower())
return
else:
assistant_speaks("I can search the web for you, Do you want to continue?")
ans = get_audio()
if 'yes' in str(ans) or 'yeah' in str(ans):
search_web(input)
else:
return
except :
assistant_speaks("I don't understand, I can search the web for you, Do you want to continue?")
ans = get_audio()
if 'yes' in str(ans) or 'yeah' in str(ans):
search_web(input)
Ahora que hemos procesado la entrada, ¡es hora de actuar! Hay dos funciones incluidas que son search_web y open_application. search_web es solo un rastreador web que utiliza el paquete Selenium para procesar. Puede buscar en google , wikipedia y puede abrir YouTube . Solo tienes que decir incluir el nombre y se abrirá en el navegador Firefox. Para otros navegadores, debe instalar un paquete de navegador adecuado en selenium. Aquí estamos usando webdriver para Firefox. open_application es solo una función que usa el paquete os para abrir la aplicación presente en el sistema.
Python3
def search_web(input):
driver = webdriver.Firefox()
driver.implicitly_wait(1)
driver.maximize_window()
if 'youtube' in input.lower():
assistant_speaks("Opening in youtube")
indx = input.lower().split().index('youtube')
query = input.split()[indx + 1:]
driver.get("http://www.youtube.com/results?search_query =" + '+'.join(query))
return
elif 'wikipedia' in input.lower():
assistant_speaks("Opening Wikipedia")
indx = input.lower().split().index('wikipedia')
query = input.split()[indx + 1:]
driver.get("https://en.wikipedia.org/wiki/" + '_'.join(query))
return
else:
if 'google' in input:
indx = input.lower().split().index('google')
query = input.split()[indx + 1:]
driver.get("https://www.google.com/search?q =" + '+'.join(query))
elif 'search' in input:
indx = input.lower().split().index('google')
query = input.split()[indx + 1:]
driver.get("https://www.google.com/search?q =" + '+'.join(query))
else:
driver.get("https://www.google.com/search?q =" + '+'.join(input.split()))
return
# function used to open application
# present inside the system.
def open_application(input):
if "chrome" in input:
assistant_speaks("Google Chrome")
os.startfile('C:\Program Files (x86)\Google\Chrome\Application\chrome.exe')
return
elif "firefox" in input or "mozilla" in input:
assistant_speaks("Opening Mozilla Firefox")
os.startfile('C:\Program Files\Mozilla Firefox\\firefox.exe')
return
elif "word" in input:
assistant_speaks("Opening Microsoft Word")
os.startfile('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Microsoft Office 2013\\Word 2013.lnk')
return
elif "excel" in input:
assistant_speaks("Opening Microsoft Excel")
os.startfile('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Microsoft Office 2013\\Excel 2013.lnk')
return
else:
assistant_speaks("Application not available")
return
Estos son algunos de los ejemplos y resultados, que pueden ayudarlo a comprender cómo funciona el procesamiento anterior.
1. Say "Search google Geeks for Geeks" 2. Say "Play Youtube your favourite song" 3. Say "Wikipedia Dhoni" 4. Say "Open Microsoft Word" 5. Say "Calculate anything you want"
En todos los casos anteriores, se dará hacer lo que se le diga. Si el asistente no puede entender lo que se le dice, le pedirá que lo busque en Google. Porque lo que el asistente no puede hacer lo maneja este asistente. A continuación se muestran algunas capturas de pantalla de la conversación entre el humano y el asistente. 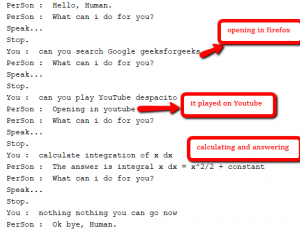

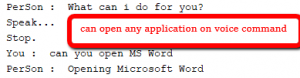 Bueno, eso es todo. La funcionalidad anterior se puede codificar de muchas maneras, esta es una implementación básica. Asegúrese de tener la última versión de todos los paquetes anteriores para un trabajo sin problemas. Para ejecutar el código anterior, combine todas las funciones en el mismo archivo.
Bueno, eso es todo. La funcionalidad anterior se puede codificar de muchas maneras, esta es una implementación básica. Asegúrese de tener la última versión de todos los paquetes anteriores para un trabajo sin problemas. Para ejecutar el código anterior, combine todas las funciones en el mismo archivo.
Publicación traducida automáticamente
Artículo escrito por Sheetansh kumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA