Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.pct_change()calcula el cambio porcentual entre el elemento actual y el anterior. Esta función calcula por defecto el cambio porcentual desde la fila inmediatamente anterior.
Nota: esta función es principalmente útil en los datos de series temporales.
Sintaxis: DataFrame.pct_change(periods=1, fill_method=’pad’, limit=Ninguno, freq=Ninguno, **kwargs)
Parámetros:
períodos: Períodos a cambiar para formar un cambio porcentual.
fill_method: Cómo manejar los NA antes de calcular los cambios porcentuales.
limit : El número de NA consecutivos para llenar antes de detenerse
freq : Incremento para usar desde la API de serie temporal (por ejemplo, ‘M’ o BDay()).
**kwargs: los argumentos de palabras clave adicionales se pasan a DataFrame.shift o Series.shift.Devuelve: El mismo tipo que el objeto que llama.
Ejemplo n.º 1: use pct_change()la función para encontrar el cambio porcentual en los datos de la serie temporal.
# importing pandas as pd
import pandas as pd
# Creating the time-series index
ind = pd.date_range('01/01/2000', periods = 6, freq ='W')
# Creating the dataframe
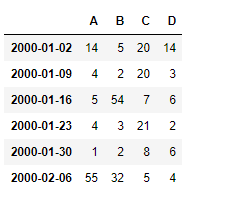
df = pd.DataFrame({"A":[14, 4, 5, 4, 1, 55],
"B":[5, 2, 54, 3, 2, 32],
"C":[20, 20, 7, 21, 8, 5],
"D":[14, 3, 6, 2, 6, 4]}, index = ind)
# Print the dataframe
df
Usemos la dataframe.pct_change()función para encontrar el cambio porcentual en los datos.
# find the percentage change with the previous row df.pct_change()
Salida: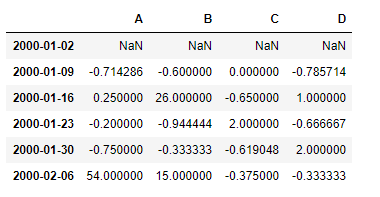
la primera fila contiene NaNvalores, ya que no hay una fila anterior a partir de la cual podamos calcular el cambio.
Ejemplo #2: Use pct_change()la función para encontrar el cambio porcentual en los datos que también tienen NaNvalores.
# importing pandas as pd
import pandas as pd
# Creating the time-series index
ind = pd.date_range('01/01/2000', periods = 6, freq ='W')
# Creating the dataframe
df = pd.DataFrame({"A":[14, 4, 5, 4, 1, 55],
"B":[5, 2, None, 3, 2, 32],
"C":[20, 20, 7, 21, 8, None],
"D":[14, None, 6, 2, 6, 4]}, index = ind)
# apply the pct_change() method
# we use the forward fill method to
# fill the missing values in the dataframe
df.pct_change(fill_method ='ffill')
Producción :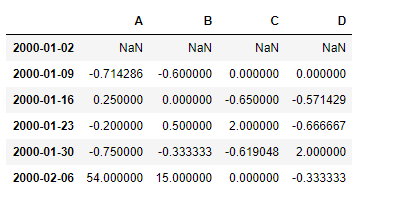
La primera fila contiene NaNvalores, ya que no hay una fila anterior a partir de la cual podamos calcular el cambio. Todos los NaNvalores en el marco de datos se han llenado usando el ffillmétodo.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA