Una base de datos consta de una gran cantidad de datos. Los datos se agrupan dentro de una tabla en RDBMS y cada tabla tiene registros relacionados. Un usuario puede ver que los datos se almacenan en forma de tablas, pero en realidad esta enorme cantidad de datos se almacena en la memoria física en forma de archivos.
Archivo: un archivo se denomina colección de información relacionada que se registra en un almacenamiento secundario, como discos magnéticos, cintas magnéticas y discos ópticos.
¿Qué es la organización de archivos?
La Organización del Archivo se refiere a las relaciones lógicas entre varios registros que constituyen el archivo, particularmente con respecto a los medios de identificación y acceso a cualquier registro específico. En términos simples, el almacenamiento de archivos en cierto orden se denomina organización de archivos. La estructura del archivo se refiere al formato de la etiqueta y los bloques de datos y de cualquier registro de control lógico.
Tipos de organizaciones de archivos:
Se han introducido varios métodos para organizar archivos. Estos métodos particulares tienen ventajas y desventajas sobre la base del acceso o la selección. Por lo tanto, depende del programador decidir el método de organización de archivos más adecuado de acuerdo con sus requisitos.
Algunos tipos de organizaciones de archivos son:
- Organización de archivos secuenciales
- Organización de archivos de montón
- Organización de archivos hash
- Organización de archivos de árbol B+
- Organización de archivos en clúster
Discutiremos cada una de las Organizaciones de archivos en más conjuntos de este artículo junto con las diferencias y ventajas/desventajas de cada método de Organización de archivos.
Organización de archivos secuenciales –
El método más fácil para la organización de archivos es el método secuencial. En este método, los archivos se almacenan uno tras otro de manera secuencial. Hay dos formas de implementar este método:
- Método de archivo de pila: este método es bastante simple, en el que almacenamos los registros en una secuencia, es decir, uno tras otro en el orden en que se insertan en las tablas.
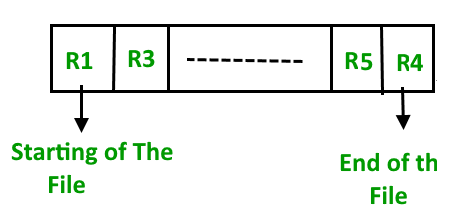
- Inserción de un nuevo registro:
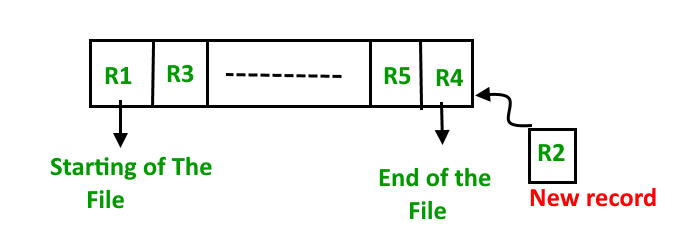
deje que R1, R3 y así sucesivamente hasta R5 y R4 sean cuatro registros en la secuencia. Aquí, los registros no son más que una fila en cualquier tabla. Supongamos que se debe insertar un nuevo registro R2 en la secuencia, luego simplemente se coloca al final del archivo.
- Método de archivo ordenado: en este método, como sugiere el propio nombre, cada vez que se debe insertar un nuevo registro, siempre se inserta de manera ordenada (ascendente o descendente). La clasificación de los registros puede basarse en cualquier clave principal o en cualquier otra clave.
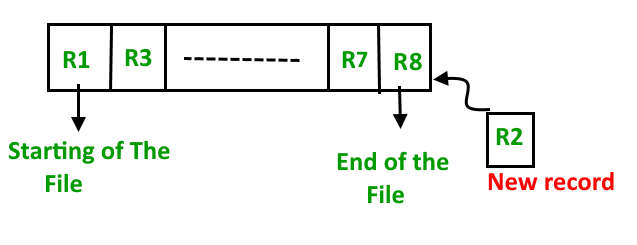
- Inserción de un nuevo registro:
supongamos que existe una secuencia ordenada preexistente de cuatro registros R1, R3, y así sucesivamente hasta R7 y R8. Supongamos que se debe insertar un nuevo registro R2 en la secuencia, luego se insertará al final del archivo y luego ordenará la secuencia.
Pros y contras de la organización de archivos secuenciales –
Pros –
- Método rápido y eficiente para una gran cantidad de datos.
- Diseño simple.
- Los archivos se pueden almacenar fácilmente en cintas magnéticas, es decir, un mecanismo de almacenamiento más económico.
Contras –
- Pérdida de tiempo, ya que no podemos saltar sobre un registro en particular que se requiere, sino que tenemos que movernos de manera secuencial, lo que requiere nuestro tiempo.
- El método de archivo ordenado es ineficiente ya que requiere tiempo y espacio para clasificar los registros.
Organización de archivos de montón:
Heap File Organization funciona con bloques de datos. En este método, los registros se insertan al final del archivo, en los bloques de datos. No se requiere clasificar ni ordenar en este método. Si un bloque de datos está lleno, el nuevo registro se almacena en algún otro bloque. Aquí, el otro bloque de datos no necesita ser el siguiente bloque de datos, pero puede ser cualquier bloque en la memoria. Es responsabilidad de DBMS almacenar y administrar los nuevos registros.
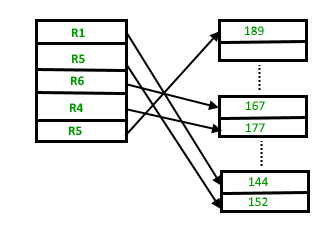
Inserción de un nuevo registro:
supongamos que tenemos cuatro registros en el montón R1, R5, R6, R4 y R3 y supongamos que se debe insertar un nuevo registro R2 en el montón, ya que el último bloque de datos, es decir, el bloque de datos 3 está lleno, lo hará. insertarse en cualquiera de los bloques de datos seleccionados por el DBMS, digamos el bloque de datos 1.
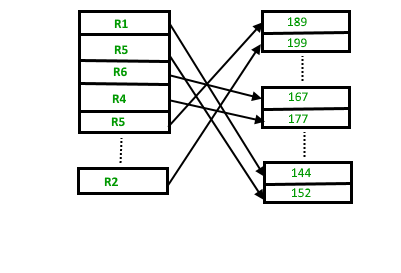
Si queremos buscar, eliminar o actualizar datos en la organización del archivo heap, recorreremos los datos desde el principio del archivo hasta que obtengamos el registro solicitado. Por lo tanto, si la base de datos es muy grande, buscar, eliminar o actualizar el registro llevará mucho tiempo.
Pros y contras de la organización de archivos Heap –
Pros –
- Obtener y recuperar registros es más rápido que el registro secuencial, pero solo en el caso de bases de datos pequeñas.
- Cuando es necesario cargar una gran cantidad de datos en la base de datos a la vez, este método de organización de archivos es el más adecuado.
Contras –
- Problema de bloques de memoria no utilizados.
- Ineficiente para bases de datos más grandes.
Lea el siguiente conjunto: (Organización de archivos DBMS-Conjunto 2) | Hashing en DBMS
Publicación traducida automáticamente
Artículo escrito por Smitha Dinesh Semwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA