Problema: dados 2 procesos i y j, debe escribir un programa que pueda garantizar la exclusión mutua entre los dos sin ningún soporte de hardware adicional.
Recomendamos encarecidamente consultar la solución básica a continuación discutida en el artículo anterior.
Algoritmo de Peterson para exclusión mutua | Conjunto 1
Estaríamos resolviendo 2 problemas en el algoritmo anterior.
Desperdicio de ciclos de reloj de CPU
En términos sencillos, cuando un subproceso estaba esperando su turno, terminaba en un ciclo de tiempo largo que probaba la condición millones de veces por segundo, por lo que realizaba cálculos innecesarios. Hay una mejor manera de esperar, y se conoce como “rendimiento” .
Para comprender lo que hace, debemos profundizar en cómo funciona el programador de procesos en Linux. La idea mencionada aquí es una versión simplificada del programador, la implementación real tiene muchas complicaciones.
Considere el siguiente ejemplo,
hay tres procesos, P1, P2 y P3. El proceso P3 es tal que tiene un bucle while similar al de nuestro código, que no hace cálculos tan útiles, y sale del bucle solo cuando P2 finaliza su ejecución. El planificador los pone a todos en una cola de turno rotativo. Ahora, digamos que la velocidad del reloj del procesador es 1000000/seg, y asigna 100 relojes a cada proceso en cada iteración. Entonces, primero se ejecutará P1 durante 100 relojes (0.0001 segundos), luego P2 (0.0001 segundos) seguido de P3 (0.0001 segundos), ahora como no hay más procesos, este ciclo se repite hasta que finaliza P2 y luego sigue la ejecución de P3 y eventualmente su terminación.
Esto es una completa pérdida de los 100 ciclos de reloj de la CPU. Para evitar esto, renunciamos mutuamente a la porción de tiempo de la CPU, es decir, el rendimiento, que esencialmente finaliza esta porción de tiempo y el planificador toma el siguiente proceso para ejecutar. Ahora, probamos nuestra condición una vez, luego renunciamos a la CPU. Teniendo en cuenta que nuestra prueba toma 25 ciclos de reloj, ahorramos el 75% de nuestro cálculo en un intervalo de tiempo. Para poner esto gráficamente,
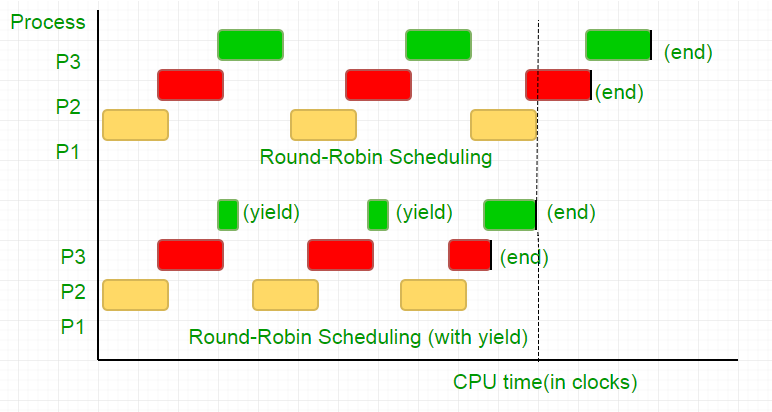
Teniendo en cuenta que la velocidad del reloj del procesador es de 1 MHz, ¡esto supone un gran ahorro!.
Diferentes distribuciones proporcionan diferentes funciones para lograr esta funcionalidad. Linux proporciona sched_yield() .
C
void lock(int self)
{
flag[self] = 1;
turn = 1-self;
while (flag[1-self] == 1 &&
turn == 1-self)
// Only change is the addition of
// sched_yield() call
sched_yield();
}
Valla de la memoria.
El código del tutorial anterior podría haber funcionado en la mayoría de los sistemas, pero no era 100 % correcto. La lógica era perfecta, pero la mayoría de las CPU modernas emplean optimizaciones de rendimiento que pueden provocar una ejecución desordenada. Este reordenamiento de las operaciones de memoria (cargas y almacenamientos) normalmente pasa desapercibido dentro de un solo hilo de ejecución, pero puede causar un comportamiento impredecible en programas concurrentes.
Considere este ejemplo,
C
while (f == 0); // Memory fence required here print x;
En el ejemplo anterior, el compilador considera que las 2 declaraciones son independientes entre sí y, por lo tanto, intenta aumentar la eficiencia del código reordenándolas, lo que puede generar problemas para los programas concurrentes. Para evitar esto, colocamos una valla de memoria para dar pistas al compilador sobre la posible relación entre las declaraciones a través de la barrera.
Así que el orden de las declaraciones,
bandera[auto] = 1;
turno = 1-yo;
while (comprobar condición de giro)
yield();
tiene que ser exactamente igual para que el bloqueo funcione, de lo contrario terminará en una condición de punto muerto.
Para garantizar esto, los compiladores brindan una instrucción que evita ordenar las declaraciones a través de esta barrera. En el caso de gcc, es __sync_synchronize() .
Entonces el código modificado se convierte
en Implementación completa en C:
C
// Filename: peterson_yieldlock_memoryfence.c
// Use below command to compile:
// gcc -pthread peterson_yieldlock_memoryfence.c -o peterson_yieldlock_memoryfence
#include<stdio.h>
#include<pthread.h>
#include "mythreads.h"
int flag[2];
int turn;
const int MAX = 1e9;
int ans = 0;
void lock_init()
{
// Initialize lock by reseting the desire of
// both the threads to acquire the locks.
// And, giving turn to one of them.
flag[0] = flag[1] = 0;
turn = 0;
}
// Executed before entering critical section
void lock(int self)
{
// Set flag[self] = 1 saying you want
// to acquire lock
flag[self]=1;
// But, first give the other thread the
// chance to acquire lock
turn = 1-self;
// Memory fence to prevent the reordering
// of instructions beyond this barrier.
__sync_synchronize();
// Wait until the other thread loses the
// desire to acquire lock or it is your
// turn to get the lock.
while (flag[1-self]==1 && turn==1-self)
// Yield to avoid wastage of resources.
sched_yield();
}
// Executed after leaving critical section
void unlock(int self)
{
// You do not desire to acquire lock in future.
// This will allow the other thread to acquire
// the lock.
flag[self]=0;
}
// A Sample function run by two threads created
// in main()
void* func(void *s)
{
int i = 0;
int self = (int *)s;
printf("Thread Entered: %d\n",self);
lock(self);
// Critical section (Only one thread
// can enter here at a time)
for (i=0; i<MAX; i++)
ans++;
unlock(self);
}
// Driver code
int main()
{
pthread_t p1, p2;
// Initialize the lock
lock_init();
// Create two threads (both run func)
Pthread_create(&p1, NULL, func, (void*)0);
Pthread_create(&p2, NULL, func, (void*)1);
// Wait for the threads to end.
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("Actual Count: %d | Expected Count:"
" %d\n",ans,MAX*2);
return 0;
}
C
// mythread.h (A wrapper header file with assert
// statements)
#ifndef __MYTHREADS_h__
#define __MYTHREADS_h__
#include <pthread.h>
#include <assert.h>
#include <sched.h>
void Pthread_mutex_lock(pthread_mutex_t *m)
{
int rc = pthread_mutex_lock(m);
assert(rc == 0);
}
void Pthread_mutex_unlock(pthread_mutex_t *m)
{
int rc = pthread_mutex_unlock(m);
assert(rc == 0);
}
void Pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg)
{
int rc = pthread_create(thread, attr, start_routine, arg);
assert(rc == 0);
}
void Pthread_join(pthread_t thread, void **value_ptr)
{
int rc = pthread_join(thread, value_ptr);
assert(rc == 0);
}
#endif // __MYTHREADS_h__
Producción:
Thread Entered: 1 Thread Entered: 0 Actual Count: 2000000000 | Expected Count: 2000000000
Este artículo es una contribución de Pinkesh Badjatiya . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA