Diseñar un servicio de acortador de URL es una de las preguntas más frecuentes en la ronda de diseño de sistemas en las entrevistas. Deberá indicar su enfoque para diseñar este servicio dentro de un período de tiempo limitado ( 45 minutos o menos ). Muchos candidatos tienen más miedo de esta ronda que de la ronda de codificación porque no tienen la idea de qué temas y compensaciones deben cubrir dentro de este período de tiempo limitado. En primer lugar, recuerde que la ronda de diseño del sistema es extremadamente abierta y no existe una respuesta estándar. Incluso para la misma pregunta, tendrá una discusión totalmente diferente con diferentes entrevistadores.

En este blog, discutiremos cómo diseñar un servicio de acortador de URL, pero antes de continuar, queremos que lea el artículo » ¿Cómo descifrar la ronda de diseño del sistema en las entrevistas?» ”. Le dará una idea de cómo es esta ronda, qué se espera que haga en esta ronda y qué errores debe evitar frente al entrevistador.
¿Cómo diseñaría un servicio de acortador de URL como TinyURL?
Los servicios de acortamiento de URL como bit.ly o TinyURL son muy populares para generar alias más cortos para URL largas. Debe diseñar este tipo de servicio web donde, si un usuario proporciona una URL larga, el servicio devuelve una URL corta y si el usuario proporciona una URL corta, devuelve la URL larga original. Por ejemplo, acortando la URL dada a través de TinyURL:
https://www.geeksforgeeks.org/get-your-dream-job-with-amazon-sde-test-series/?ref=leftbar-rightbar
Obtenemos el resultado que se muestra a continuación.
https://tinyurl.com/y7vg2xjl
Muchos candidatos podrían estar pensando que diseñar este servicio no es difícil. Cuando un usuario proporciona una URL larga, conviértala en una URL corta y actualice la base de datos y cuando el usuario accede a la URL corta, busque la URL corta en la base de datos, obtenga esa URL larga y redirija al usuario a la URL original. ¿Es realmente sencillo? Absolutamente no si pensamos en la escalabilidad de este servicio.
Cuando le hagan esta pregunta en sus entrevistas, no salte a los detalles técnicos de inmediato. La mayoría de los candidatos cometen errores aquí e inmediatamente comienzan a enumerar un montón de herramientas, bases de datos y marcos. En este tipo de pregunta, el entrevistador quiere una idea de diseño de alto nivel donde pueda dar la solución para la escalabilidad y durabilidad del servicio.
Comencemos hablando primero del requisito…
1. Requisito
Antes de saltar a la solución, siempre aclare todas las suposiciones que está haciendo al comienzo de la entrevista. Haga preguntas para identificar el alcance del sistema. Esto aclarará la duda inicial y sabrá cuáles son los detalles específicos que el entrevistador quiere considerar en este servicio.
- Dada una URL larga, el servicio debería generar un alias único y más corto.
- Cuando el usuario accede a un enlace corto, el servicio debe redirigir al enlace original.
- Los enlaces caducan después de un período de tiempo predeterminado estándar.
- El sistema debe tener alta disponibilidad. Es muy importante tener esto en cuenta porque si el servicio deja de funcionar, toda la redirección de URL comenzará a fallar.
- La redirección de URL debe ocurrir en tiempo real con una latencia mínima.
- Los enlaces acortados no deben ser predecibles.
Comencemos por hacer algunas suposiciones sobre el tráfico (para la escalabilidad) y la longitud de la URL.
2. Tráfico
Supongamos que nuestro servicio tiene 30 millones de nuevas URL acortadas por mes. Supongamos que almacenamos cada solicitud de acortamiento de URL (y el enlace acortado asociado) durante 5 años. Para este período el servicio generará alrededor de 1,8 B de registros.
30 million * 5 years * 12 months = 1.8B
3. Longitud de la URL
Consideremos que estamos usando 7 caracteres para generar una URL corta. Estos caracteres son una combinación de 62 caracteres [AZ, az, 0-9] algo así como http://ad.com/abXdef2 .
4. Modelado de capacidad de datos
Discuta el modelo de capacidad de datos para estimar el almacenamiento del sistema. Necesitamos entender cuántos datos podríamos tener que insertar en nuestro sistema. Piense en las diferentes columnas o atributos que se almacenarán en nuestra base de datos y calcule el almacenamiento de datos durante cinco años. Hagamos la suposición dada a continuación para diferentes atributos…
- Considere un tamaño de URL largo promedio de 2 KB, es decir, para 2048 caracteres.
- Tamaño de URL corto: 17 bytes para 17 caracteres
- created_at- 7 bytes
- expiration_length_in_minutes -7 bytes
El cálculo anterior dará un total de 2,031 KB por entrada de URL abreviada en la base de datos. Si calculamos el almacenamiento total, para 30 millones de usuarios activos, tamaño total = 30000000 * 2,031 = 60780000 KB = 60,78 GB por mes. En un Año de 0.7284 TB y en 5 años 3.642 TB de datos.
Necesitamos pensar en las lecturas y escrituras que ocurrirán en nuestro sistema para esta cantidad de datos. Esto decidirá qué tipo de base de datos (RDBMS o NoSQL) necesitamos usar.
5. Lógica de acortamiento de URL (codificación)
Para convertir una URL larga en una URL corta única, podemos usar algunas técnicas de hashing como Base62 o MD5. Discutiremos ambos enfoques.
Codificación Base62: el codificador Base62 nos permite usar la combinación de caracteres y números que contiene AZ, az, 0–9 en total (26 + 26 + 10 = 62). Entonces, para una URL corta de 7 caracteres, podemos servir 62 ^ 7 ~= 3500 mil millones de URL, lo que es suficiente en comparación con la base 10 (la base 10 solo contiene números del 0 al 9, por lo que obtendrá solo 10 millones de combinaciones). Si usamos base62 asumiendo que el servicio está generando 1000 URL pequeñas por segundo, tomará 110 años agotar esta combinación de 3500 mil millones. Podemos generar un número aleatorio para la URL larga dada y convertirlo a base62 y usar el hash como una identificación de URL corta.
Python3
def to_base_62(deci): s = '012345689abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' hash_str = '' while deci > 0: hash_str= s[deci % 62] + hash_str deci /= 62 return hash_str print to_base_62(999)
Codificación MD5: MD5 también proporciona una salida base62, pero el hash MD5 proporciona una salida larga de más de 7 caracteres. El hash MD5 genera una salida larga de 128 bits, por lo que de 128 bits tomaremos 43 bits para generar una pequeña URL de 7 caracteres. MD5 puede crear muchas colisiones. Para dos o muchas entradas de URL largas diferentes, podemos obtener la misma identificación única para la URL corta y eso podría causar daños en los datos. Por lo tanto, debemos realizar algunas comprobaciones para asegurarnos de que esta identificación única no exista ya en la base de datos.
6. Base de datos
Podemos usar RDBMS que usa propiedades ACID, pero enfrentará el problema de escalabilidad con las bases de datos relacionales. Ahora, si cree que puede usar fragmentación y resolver el problema de escalabilidad en RDBMS, eso aumentará la complejidad del sistema. Hay 30 millones de usuarios activos, por lo que habrá conversiones y muchas redirecciones y resolución de URL cortas. Leer y escribir será pesado para estos 30 millones de usuarios, por lo que escalar el RDBMS usando fragmentos aumentará la complejidad del diseño cuando queramos tener nuestro sistema de manera distribuida. Es posible que deba usar hash coherente para equilibrar los tráficos y las consultas de la base de datos en el caso de RDBMS y que es un proceso complicado. Por lo tanto, para manejar esta enorme cantidad de tráfico en nuestro sistema, las bases de datos relacionales no son adecuadas y tampoco será una buena decisión escalar el RDBMS.
¡Ahora hablemos de NoSQL!
El único problema con el uso de la base de datos NoSQL es su eventual consistencia. Escribimos algo y lleva algún tiempo replicarlo en un Node diferente, pero nuestro sistema necesita alta disponibilidad y NoSQL cumple con este requisito. NoSQL puede manejar fácilmente los 30 millones de usuarios activos y es fácil de escalar. Solo necesitamos seguir agregando los Nodes cuando queremos expandir el almacenamiento.
Técnicas para generar y almacenar TinyURL
Técnica 1
Analicemos la asignación de una URL larga a una URL corta en nuestra base de datos. Supongamos que generamos la URL pequeña usando la codificación base62, luego debemos realizar los pasos que se detallan a continuación…
- La pequeña URL debe ser única, así que primero verifique la existencia de esta pequeña URL en la base de datos (haciendo get(tiny) en la base de datos). Si ya está presente allí para alguna otra URL larga, genere una nueva URL corta.
- Si la URL corta no está presente en la base de datos, coloque longURL y TinyURL en la base de datos (put(TinyURL, longURL)).
Esta técnica funciona muy bien con un servidor, pero si habrá varios servidores, esta técnica creará una condición de carrera. Cuando varios servidores trabajen juntos, existirá la posibilidad de que todos puedan generar la misma identificación única o la misma URL diminuta para diferentes URL largas, e incluso después de verificar la base de datos, se les permitirá insertar las mismas URL diminutas simultáneamente (que es el mismo para diferentes URL largas) en la base de datos y esto puede terminar corrompiendo los datos.
Podemos usar la condición putIfAbsent(TinyURL, URL larga) o INSERT-IF-NOT-EXIST al insertar la URL pequeña, pero esto requiere soporte de DB, que está disponible en RDBMS pero no en NoSQL. Los datos son eventualmente coherentes en NoSQL, por lo que es posible que la compatibilidad con la función putIfAbsent no esté disponible en la base de datos NoSQL.
Técnica 2 (enfoque MD5)
- Codifique la URL larga utilizando el enfoque MD5 y tome solo los primeros 7 caracteres para generar TinyURL.
- Los primeros 7 caracteres pueden ser los mismos para diferentes URL largas, así que revise la base de datos (como hemos discutido en la técnica 1) para verificar que TinyURL no se esté usando ya.
- Ventajas: este enfoque ahorra algo de espacio en la base de datos, pero ¿cómo? Si dos usuarios desean generar una URL pequeña para la misma URL larga, la primera técnica generará dos números aleatorios y requiere dos filas en la base de datos, pero en la segunda técnica, la URL más larga tendrá el mismo MD5, por lo que tendrá los mismos primeros 43 bits, lo que significa que obtendremos algo de deduplicación y terminaremos ahorrando algo de espacio, ya que solo necesitamos almacenar una fila en lugar de dos filas en la base de datos.
MD5 ahorra algo de espacio en la base de datos para las mismas URL, pero para dos URL largas y diferentes nuevamente nos enfrentaremos al mismo problema que hemos discutido en la técnica 1. Podemos usar putIfAbsent pero NoSQL no es compatible con esta función. Así que pasemos a la tercera técnica para resolver este problema.
Técnica 3 (Enfrentamiento)
Usar un contador es una buena decisión para una solución escalable porque los contadores siempre se incrementan para que podamos obtener un nuevo valor para cada nueva solicitud.
Enfoque de servidor único:
- Un solo host o servidor (por ejemplo, base de datos) será responsable de mantener el contador.
- Cuando el host trabajador recibe una solicitud, se comunica con el host del contador, que devuelve un número único e incrementa el contador. Cuando llega la siguiente solicitud, el host del contador devuelve nuevamente el número único y esto continúa.
- Cada host trabajador obtiene un número único que se usa para generar TinyURL.
Problema: si el host del contador se cae durante algún tiempo, creará un problema, también si la cantidad de requests será alta, es posible que el host del contador no pueda manejar la carga. Entonces, los desafíos son un punto único de falla y un punto único de cuello de botella.
¿Y si hay varios servidores?
No puede mantener un solo contador y devuelve la salida a todos los servidores. Para resolver este problema, podemos usar múltiples contadores internos para múltiples servidores que usan diferentes rangos de contadores. Por ejemplo, el servidor 1 varía de 1 a 1 M, el servidor 2 varía de 1 M a 10 M, y así sucesivamente. Pero nuevamente nos enfrentaremos a un problema, es decir, si uno de los contadores se cae, entonces para otro servidor será difícil obtener el rango del contador de fallas y mantenerlo nuevamente. Además, si un contador alcanza su límite máximo, será difícil restablecer el contador porque no hay un solo host disponible para la coordinación entre todos estos servidores múltiples. La arquitectura estará desordenada ya que no sabemos qué servidor es el maestro o cuál es el esclavo y cuál es el responsable de la coordinación y sincronización.
Solución: para resolver este problema, podemos usar un servicio distribuido Zookeeper para administrar todas estas tareas tediosas y resolver los diversos desafíos de un sistema distribuido como una condición de carrera, interbloqueo o falla de partículas de datos. Zookeeper es básicamente un servicio de coordinación distribuido que administra un gran conjunto de hosts. Realiza un seguimiento de todas las cosas, como el nombre de los servidores, servidores activos, servidores inactivos, información de configuración de todos los hosts. Proporciona coordinación y mantiene la sincronización entre los múltiples servidores.
Analicemos cómo mantener un contador para hosts distribuidos usando Zookeeper.
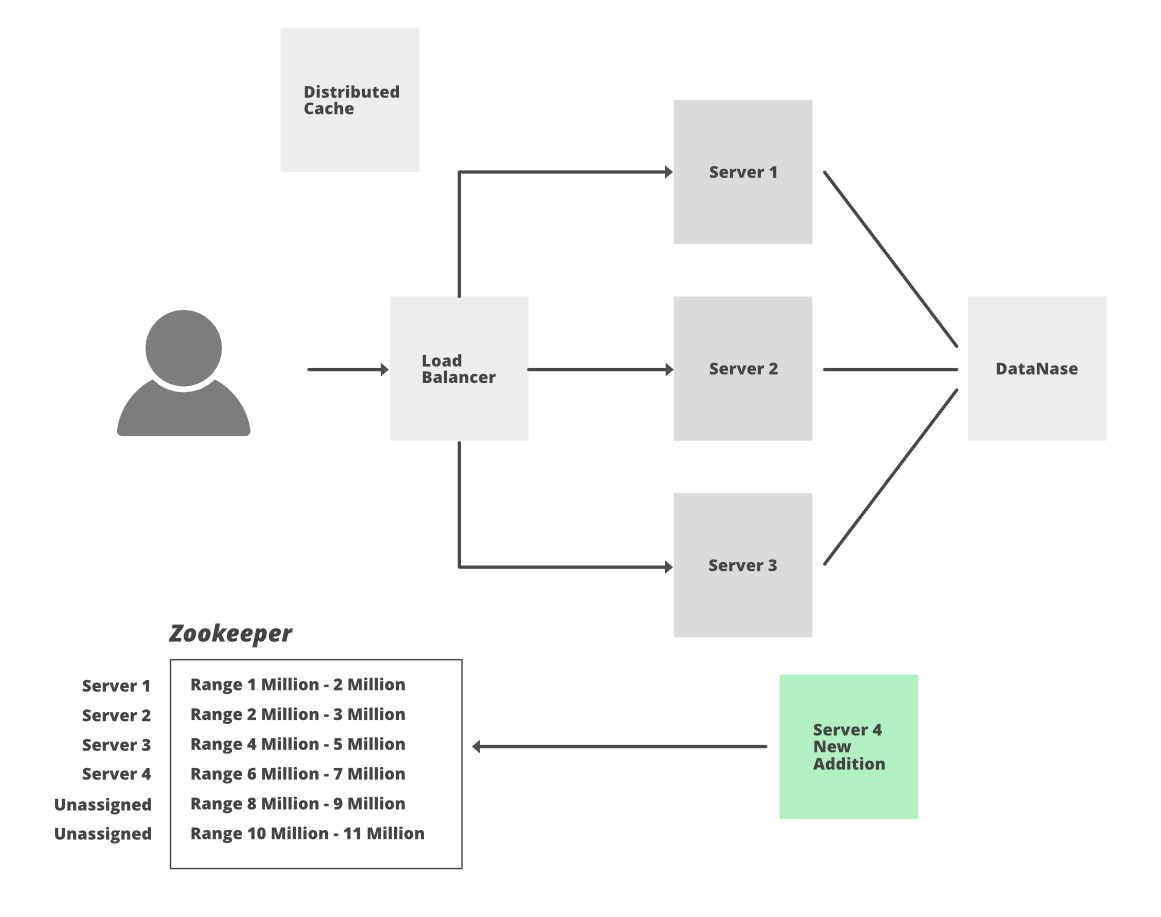
- De 3,5 billones de combinaciones, tome 1.000 millones de combinaciones.
- En Zookeeper, mantenga el rango y divida los mil millones en 1000 rangos de 1 millón cada uno, es decir, rango 1->(1 – 1,000,000), rango 2->(1,000,001 – 2,000,000)…. rango 1000->(999,000,001 – 1,000,000,000)
- Cuando se agreguen servidores, estos servidores solicitarán el rango no utilizado de Zookeepers. Supongamos que al servidor W1 se le asigna el rango 1, ahora W1 generará la pequeña URL incrementando el contador y usando la técnica de codificación. Cada vez será un número único, por lo que no hay posibilidad de colisión y tampoco es necesario seguir revisando la base de datos para asegurarse de que la URL ya exista o no. Podemos insertar directamente el mapeo de una URL larga y una URL corta en la base de datos.
- En el peor de los casos, si uno de los servidores se cae, solo perderemos un millón de combinaciones en Zookeeper (que no se usarán y tampoco podremos reutilizarlas), pero como tenemos 3,5 billones de combinaciones, no debemos preocuparnos por perder. esta combinación
- Si uno de los servidores alcanza su rango máximo o límite, nuevamente puede tomar un nuevo rango nuevo de Zookeeper.
- La adición de un nuevo servidor también es fácil. Zookeeper asignará un rango de contador no utilizado a este nuevo servidor.
- Tomaremos los 2.000 millones cuando se agote el 1.000 millones para continuar el proceso.
Publicación traducida automáticamente
Artículo escrito por anuupadhyay y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA