Top-N Analysis en SQL se ocupa de cómo limitar el número de filas devueltas de conjuntos ordenados de datos en SQL.
Las consultas Top-N solicitan los n valores más pequeños o más grandes de una columna. Tanto los conjuntos de valores más pequeños como los más grandes se consideran consultas Top-N. Seguir este tipo de técnica de búsqueda podría ahorrar mucho tiempo y complejidades. El análisis Top-N es útil en casos donde la necesidad es mostrar solo los n registros más bajos o los n registros
más altos de una tabla basada en una condición. Este conjunto de resultados se puede utilizar para un análisis más detallado.
Por ejemplo, utilizando el análisis Top-N podemos realizar los siguientes tipos de consultas:
- Los cinco productos que más ventas han tenido en los últimos dos meses.
- Los tres principales agentes que vendieron el máximo de pólizas.
- Los menos dos estudiantes que obtuvieron calificaciones mínimas en los exámenes de fin de semestre.
Realización de análisis Top-N
Siguiendo las consultas mencionadas a continuación, podemos comprender fácilmente el funcionamiento del análisis Top-N en SQL:
Sintaxis:
SELECT [column_list], ROWNUM
FROM (SELECT [column_list]
FROM table_name
ORDER BY Top-N_clolumn)
WHERE ROWNUM<=N;
Realizaremos los diversos comandos en la siguiente tabla denominada Empleado:

Ejemplo 1:
Input :
SELECT ROWNUM as RANK, first_name, last_name, employee_id, salary
FROM (SELECT salary, first_name, last_name, employee_id
FROM Employee
ORDER BY salary)
WHERE ROWNUM<=3;
Producción :
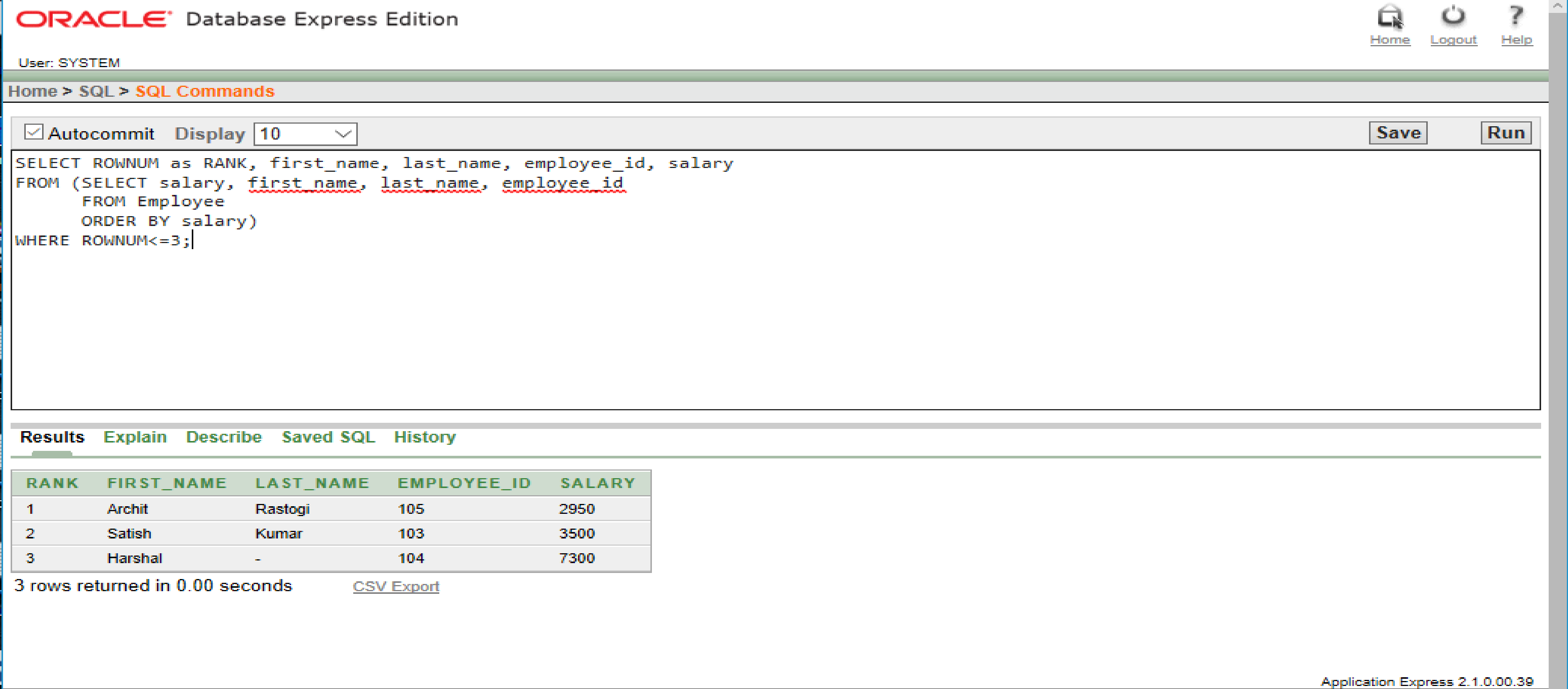
Explicación: En la instrucción SQL anterior, los campos obligatorios se muestran para los empleados con los 3 salarios más bajos. El resultado se muestra en orden creciente de sus salarios.
Ejemplo 2:
Input :
SELECT ROWNUM as RANK, first_name, employee_id, hire_date
FROM (SELECT first_name, employee_id, hire_date
FROM Employee
ORDER BY hire_date)
WHERE ROWNUM<=3;
Producción :
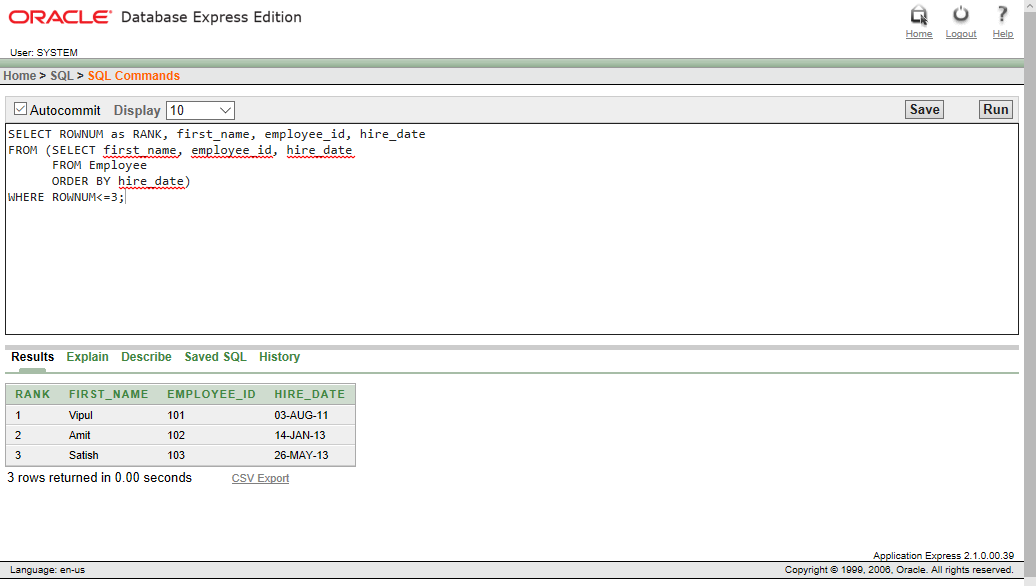
Explicación: En la instrucción SQL anterior, los campos obligatorios se muestran para los 3 empleados que fueron contratados antes. El resultado se muestra en orden creciente de su fecha de contratación.
Diferentes estilos para usar el análisis Top-N
- Vista en línea y ROWNUM: la consulta clásica de estilo Top-N utiliza una vista en línea ordenada para forzar los datos en el orden correcto que finalmente usa la verificación ROWNUM para limitar los datos devueltos.
Ejemplo:
Input :
SELECT first_name, last_name
FROM (SELECT first_name, last_name
FROM Employee
ORDER BY salary DESC)
WHERE ROWNUM<=4;
- Producción :

- Explicación: En la instrucción SQL anterior, los campos obligatorios se muestran para los 4 empleados mejor pagados. La modificación se realiza mediante la cláusula ORDER BY .
- Vista en línea anidada y ROWNUM: este método también se puede usar para paginar datos, como informes web paginados.
Ejemplo:
Input :
SELECT employee_id, first_name, salary
FROM (SELECT employee_id, first_name, salary, rownum AS rnum
FROM (SELECT employee_id, first_name, salary
FROM Employee
ORDER BY salary)
WHERE rownum<=4)
WHERE rnum>=2;
- Producción :

- Explicación: en la declaración SQL anterior, en primer lugar, la consulta interna se ejecuta y da su salida a la consulta externa, que finalmente nos da la salida deseada.
- Uso de la función RANGO: La función analítica RANGO asigna un rango secuencial a cada valor distinto en la salida.
Ejemplo:
Input :
SELECT dpartment_id, first_name
FROM (SELECT dpartment_id, first_name,
RANK() OVER (ORDER BY dpartment_id DESC) AS rnum
FROM Employee)
WHERE rnum<=3;
- Producción :
![]()
- Explicación: En la instrucción SQL anterior, la función RANK() también actúa como un campo virtual cuyo valor está restringido al final. La función RANK() no nos da las N filas superiores o los N valores distintos superiores. El número de filas devueltas depende del número de duplicados en los datos.
- Uso de la función DENSE_RANK: La función analítica DENSE_RANK es similar a la función RANK(). La diferencia es que las filas están compactadas por lo que no hay brechas.
Ejemplo:
Input :
SELECT dpartment_id, first_name
FROM (SELECT dpartment_id, first_name,
DENSE_RANK() OVER (ORDER BY dpartment_id DESC) AS rnum
FROM Employee)
WHERE rnum<=3;
- Producción :

- Explicación: En la instrucción SQL anterior, la función DENSE_RANK() también asigna el mismo rango a los valores duplicados pero no hay brecha en la secuencia de rango. Por lo tanto, siempre nos da un resultado de valores distintos Top N.
- Uso de la función ROW_NUMBER: La función analítica ROW_NUMBER es similar a la columna virtual ROWNUM pero, como todas las funciones analíticas, su acción puede limitarse a una salida específica de datos según el orden de los datos.
Ejemplo:
Input :
SELECT dpartment_id, first_name
FROM (SELECT dpartment_id, first_name,
ROW_NUMBER() OVER (ORDER BY dpartment_id DESC) AS rnum
FROM Employee)
WHERE rnum<=4;
- Producción :

- Explicación: en la instrucción SQL anterior, ROW_NUMBER() solo seleccionará los N valores principales, independientemente de que estén duplicados.
Publicación traducida automáticamente
Artículo escrito por akanshgupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA