El procesamiento de consultas incluye traducciones de consultas de alto nivel en expresiones de bajo nivel que se pueden usar a nivel físico del sistema de archivos, optimización de consultas y ejecución real de consultas para obtener el resultado real.
El diagrama de bloques del procesamiento de consultas es como:
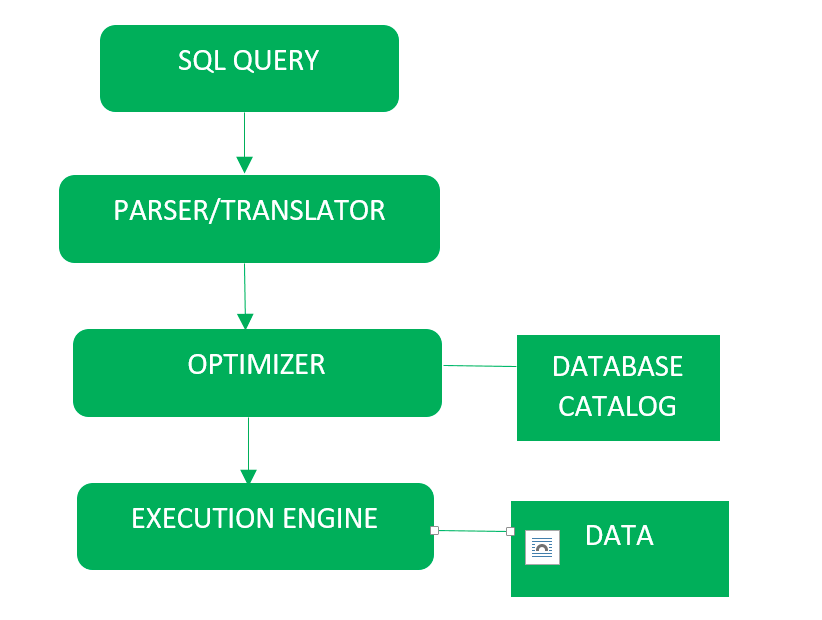
El diagrama detallado se dibuja como:
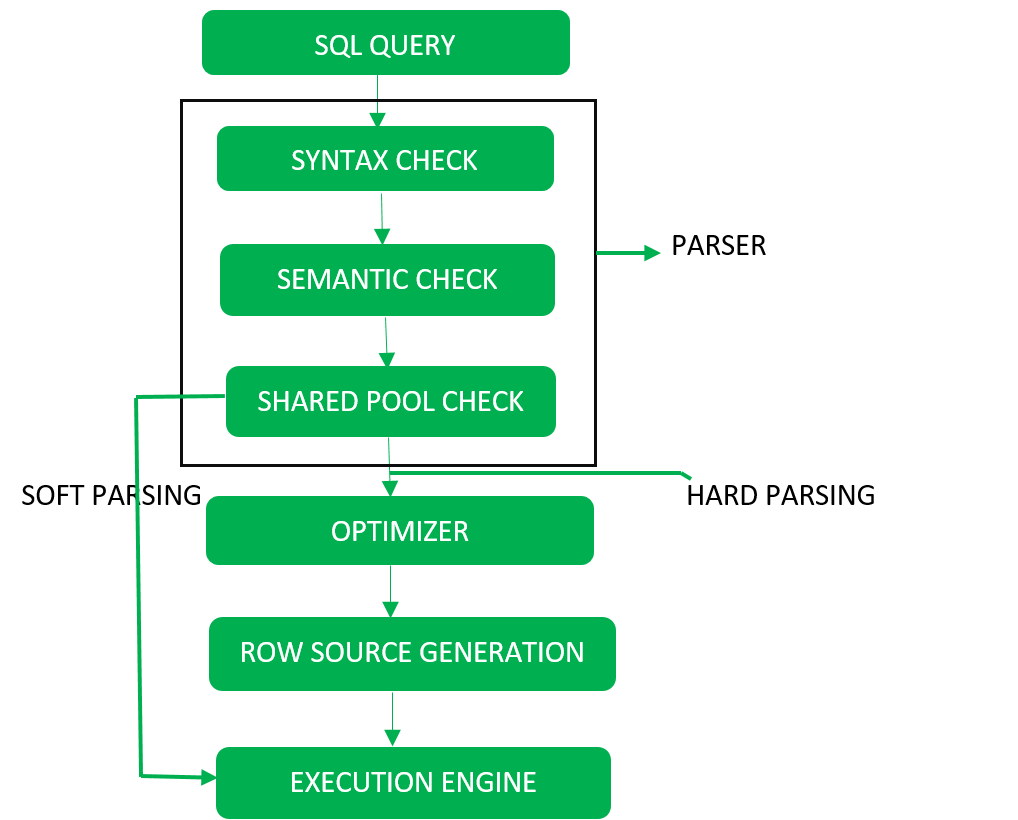
Se realiza en los siguientes pasos:
- Paso 1:
Analizador: durante la llamada de análisis, la base de datos realiza las siguientes comprobaciones: comprobación de sintaxis, comprobación semántica y comprobación de grupo compartido, después de convertir la consulta en álgebra relacional.Parser realiza las siguientes comprobaciones como (consulte el diagrama detallado):
- Comprobación de sintaxis: concluye la validez sintáctica de SQL. Ejemplo:
SELECT * FORM employee
Aquí, esta verificación da un error de ortografía incorrecta de FROM.
- Verificación semántica: determina si la declaración es significativa o no. Ejemplo: la consulta contiene un nombre de tabla que no existe y se comprueba con esta comprobación.
- Comprobación de grupo compartido: cada consulta posee un código hash durante su ejecución. Por lo tanto, esta verificación determina la existencia de código hash escrito en el grupo compartido si existe código en el grupo compartido, entonces la base de datos no tomará pasos adicionales para la optimización y ejecución.
Análisis duro y análisis suave:
si hay una consulta nueva y su código hash no existe en el grupo compartido, esa consulta debe pasar por los pasos adicionales conocidos como análisis duro; de lo contrario, si existe el código hash, la consulta no pasa por los pasos adicionales. . Simplemente pasa directamente al motor de ejecución (consulte el diagrama detallado). Esto se conoce como análisis suave.
Hard Parse incluye los siguientes pasos: Optimizer y generación de fuentes de filas. - Comprobación de sintaxis: concluye la validez sintáctica de SQL. Ejemplo:
- Paso 2:
Optimizador: durante la etapa de optimización, la base de datos debe realizar un análisis completo al menos para una declaración DML única y realizar la optimización durante este análisis. Esta base de datos nunca optimiza DDL a menos que incluya un componente DML como una subconsulta que requiera optimización.Es un proceso en el que se examinan múltiples planes de ejecución de consultas para satisfacer una consulta y se satisface el plan de consulta más eficiente para su ejecución.
El catálogo de la base de datos almacena los planes de ejecución y luego el optimizador pasa el plan de menor costo para su ejecución.Generación de origen de filas:
la generación de origen de filas es un software que recibe un plan de ejecución óptimo del optimizador y produce un plan de ejecución iterativo que puede utilizar el resto de la base de datos. el plan iterativo es el programa binario que, cuando lo ejecuta el motor sql, produce el conjunto de resultados. - Paso 3:
motor de ejecución: finalmente ejecuta la consulta y muestra el resultado requerido.
Publicación traducida automáticamente
Artículo escrito por priyankagujral y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA