El análisis de supervivencia en el lenguaje de programación R se ocupa de la predicción de eventos en un momento específico. Se trata de la ocurrencia de un evento interesante dentro de un tiempo específico y su falla produce observaciones censuradas, es decir, observaciones incompletas.
Análisis de supervivencia en lenguaje de programación R
Las ciencias biológicas son la aplicación más importante del análisis de supervivencia en el que podemos predecir el tiempo de los organismos, por ejemplo. cuando se multiplicarán a tamaños, etc.
Métodos utilizados para hacer análisis de supervivencia:
Hay dos métodos que se pueden utilizar para realizar un análisis de supervivencia en el lenguaje de programación R:
- Método de Kaplan-Meier
- Modelo de riesgo proporcional de Cox
Método Kaplan-Meier
El método de Kaplan-Meier se utiliza en la distribución de supervivencia utilizando el estimador de Kaplan-Meier para datos truncados o censurados. Es una estadística no paramétrica que nos permite estimar la función de supervivencia y, por lo tanto, no se basa en la distribución de probabilidad subyacente. Las estimaciones de Kaplan-Meier se basan en el número de pacientes (cada paciente como una fila de datos) del número total de pacientes que sobreviven durante un tiempo determinado después del tratamiento. (que es el evento).
Representamos la función de Kaplan-Meier mediante la fórmula:
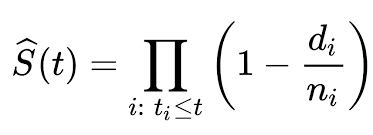
Aquí S(t) representa la probabilidad de que la vida sea más larga que t con ti (Al menos ocurrió un evento), di representa el número de eventos (por ejemplo, muertes) que ocurrieron en el tiempo ti y ni representa el número de individuos que sobrevivieron hasta tiempo ti .
Ejemplo:
Usaremos el paquete Survival para el análisis. Uso del conjunto de datos Lung precargado en el paquete de supervivencia que contiene datos de 228 pacientes con cáncer de pulmón avanzado del grupo de tratamiento del cáncer de North Central en función de 10 características. El conjunto de datos contiene valores faltantes, por lo que se supone que el tratamiento de los valores faltantes se realiza a su lado antes del modelo de construcción.
R
# Installing package
install.packages("survival")
# Loading package
library(survival)
# Dataset information
?lung
# Fitting the survival model
Survival_Function = survfit(Surv(lung$time,
lung$status == 2)~1)
Survival_Function
# Plotting the function
plot(Survival_Function)
Aquí, estamos interesados en el » tiempo » y el » estado «, ya que juegan un papel importante en el análisis. El tiempo representa el tiempo de supervivencia de los pacientes. Dado que los pacientes sobreviven, consideraremos su estado como muerto o no muerto (censurado).
La función Surv() toma dos tiempos y estados como entrada y crea un objeto que sirve como entrada de la función survfir() . Pasamos ~1 en la función survfit() para asegurarnos de que le estamos diciendo a la función que se ajuste al modelo sobre la base del objeto de supervivencia y tenga una interrupción.
survfit() crea curvas de supervivencia e imprime la cantidad de valores, la cantidad de eventos (personas que padecen cáncer), el tiempo medio y el intervalo de confianza del 95%. La trama da el siguiente resultado:
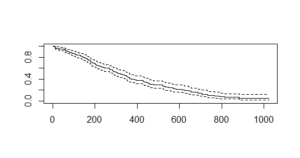
Aquí, el eje x especifica » Número de días » y el eje y especifica la » probabilidad de supervivencia «. Las líneas discontinuas son el intervalo de confianza superior y el intervalo de confianza inferior.
También tenemos el intervalo de confianza que muestra el margen de error esperado, es decir, en días de sobrevivir 200 días, el intervalo de confianza superior alcanza 0,76 o 76 % y luego baja a 0,60 o 60 % .
Modelo de riesgos proporcionales de Cox
Es un modelo de regresión que mide el riesgo instantáneo de muerte y es un poco más difícil de ilustrar que el estimador de Kaplan-Meier. Consiste en la función de riesgo h(t) que describe la probabilidad del evento o riesgo h (p. ej. supervivencia) hasta un tiempo particular t . La función de riesgo considera covariables (variables independientes en regresión) para comparar la supervivencia de grupos de pacientes.
No asume una distribución de probabilidad subyacente, pero asume que los riesgos de los grupos de pacientes que comparamos son constantes a lo largo del tiempo y, por eso, se conoce como » modelo de riesgo proporcional «.
Ejemplo:
Usaremos el paquete Survival para el análisis. Uso del conjunto de datos Lung precargado en el paquete de supervivencia que contiene datos de 228 pacientes con cáncer de pulmón avanzado del grupo de tratamiento del cáncer de North Central en función de 10 características. El conjunto de datos contiene valores faltantes, por lo que se supone que el tratamiento de los valores faltantes se realiza a su lado antes del modelo de construcción. Usaremos la función de riesgo proporcional de cox coxph() para construir el modelo.
R
# Installing package
install.packages("survival")
# Loading package
library(survival)
# Dataset information
?lung
# Fitting the Cox model
Cox_mod <- coxph(Surv(lung$time,
lung$status == 2)~., data = lung)
# Summarizing the model
summary(Cox_mod)
# Fitting survfit()
Cox <- survfit(Cox_mod)
# Plotting the function
plot(Cox)
Aquí, estamos interesados en el » tiempo » y el » estado «, ya que juegan un papel importante en el análisis. El tiempo representa el tiempo de supervivencia de los pacientes. Dado que los pacientes sobreviven, consideraremos su estado como muerto o no muerto (censurado).
La función Surv() toma dos tiempos y estados como entrada y crea un objeto que sirve como entrada de la función survfir() . Pasamos ~1 en la función survfit() para asegurarnos de que le estamos diciendo a la función que se ajuste al modelo sobre la base del objeto de supervivencia y tenga una interrupción.
El resultado de Cox_mod es similar al modelo de regresión. Hay algunas características importantes como edad, sexo, ph.ecog y wt. pérdida. La trama da el siguiente resultado:
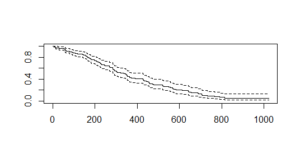
Aquí, el eje x especifica «Número de días» y el eje y especifica » probabilidad de supervivencia «. Las líneas discontinuas son el intervalo de confianza superior y el intervalo de confianza inferior. En comparación con el gráfico de Kaplan-Meier, el gráfico de Cox es alto para los valores iniciales y más bajo para los valores más altos debido a que hay más variables en el gráfico de Cox.
También tenemos el intervalo de confianza que muestra el margen de error esperado, es decir, en días de sobrevivir 200 días, el intervalo de confianza superior llega a 0,82 o 82% y luego baja a 0,70 o 70%.
Nota: el modelo de Cox ofrece mejores resultados que Kaplan-Meier, ya que es más volátil con los datos y las características. El modelo de Cox también es más alto para valores más bajos y viceversa, es decir, cae bruscamente cuando aumenta el tiempo.