Cuatro de cada diez empresas incluidas en la encuesta bianual de Cloud Native Computing Foundation informaron que ejecutan Kubernetes en entornos de producción.
A medida que más y más organizaciones se trasladan a microservicios y arquitecturas nativas de la nube que utilizan contenedores, buscan plataformas sólidas y comprobadas. Los profesionales se están mudando a Kubernetes. Con Kubernetes, puede dar pasos reales hacia una mejor seguridad de TI.
No se puede negar que Kubernetes ha arrasado en el tablero y está conquistando el mundo. Pero, como un aficionado que explora el campo en constante expansión de la computación en la nube, ¿alguna vez se preguntó qué es Kubernetes? ¿Qué hace y cómo está estructurado? Este artículo busca responder brevemente a las preguntas antes mencionadas y desarrollar una base sólida para los diversos componentes de un clúster de Kubernetes. También abarca los servicios de Kubernetes proporcionados por proveedores de servicios en la nube populares como Amazon Web Services (EKS).
¿Qué son los contenedores?
Tradicionalmente, los recipientes físicos que están hechos de lata o plástico almacenan galletas, frutas secas y una mezcla de otra parafernalia comestible. Aíslan la comida del medio extrínseco y la encierran en un ambiente hermético e impermeable. Esto evita que se vuelvan rancios y blandos.
Los contenedores DevOps difieren en la última funcionalidad. Son paquetes de software estandarizados que comprimen el código de la aplicación junto con sus dependencias específicas del entorno, como el tiempo de ejecución, las herramientas del sistema y la configuración, para que la aplicación tenga una ejecución multiplataforma fluida y confiable. Mientras que los contenedores tangibles convencionales aíslan el contenido de la atmósfera externa, los contenedores basados en la nube replican las dependencias centradas en la plataforma para permitir la implementación multiplataforma y reducir la contrariedad entre plataformas. Por lo tanto, el sistema operativo está virtualizado y puede optimizar soluciones para múltiples cargas de trabajo en una sola instancia de sistema operativo.
¿Qué es Kubernetes?
Kubernetes es un sistema de orquestación de código abierto para contenedores y aplicaciones en contenedores. Facilita su implementación, escalado y administración automatizados. Fue creado por Google y ahora es propiedad de Cloud Native Computing Foundation.
En términos sencillos, Kubernetes es como un administrador que supervisa la informatización de las operaciones de los contenedores al eliminar los métodos manuales inicialmente aprovechados en el escalado y la implementación. Un punto importante a tener en cuenta es que Kubernetes no es solo un sistema de orquestación ordinario que se adhiere a la ejecución de un flujo de trabajo mecanizado prescrito. Es una constitución de procesos de control independientes e inteligibles que conducen el estado existente del sistema al estado deseado predefinido. Varios proveedores de nube pública, como Amazon Web Services, brindan Elastic Kubernetes Services (EKS) con la flexibilidad dinámica para iniciar, ejecutar y escalar aplicaciones de Kubernetes en la nube o en las instalaciones.
Otro dato curioso es que cuando hablamos de Kubernetes (K8), nos estamos dirigiendo hacia un clúster de Kubernetes. Un clúster de Kubernetes es un conjunto de unidades de trabajo y administración (Nodes) que ejecutan y dirigen las aplicaciones en contenedores. Dentro de los clústeres, los contenedores pueden ejecutarse en múltiples entornos. AWS EKS Distro se puede utilizar para crear clústeres de Kubernetes sólidos y potentes. Ahora analizaremos el marco arquitectónico de un clúster de Kubernetes y los componentes que contiene.
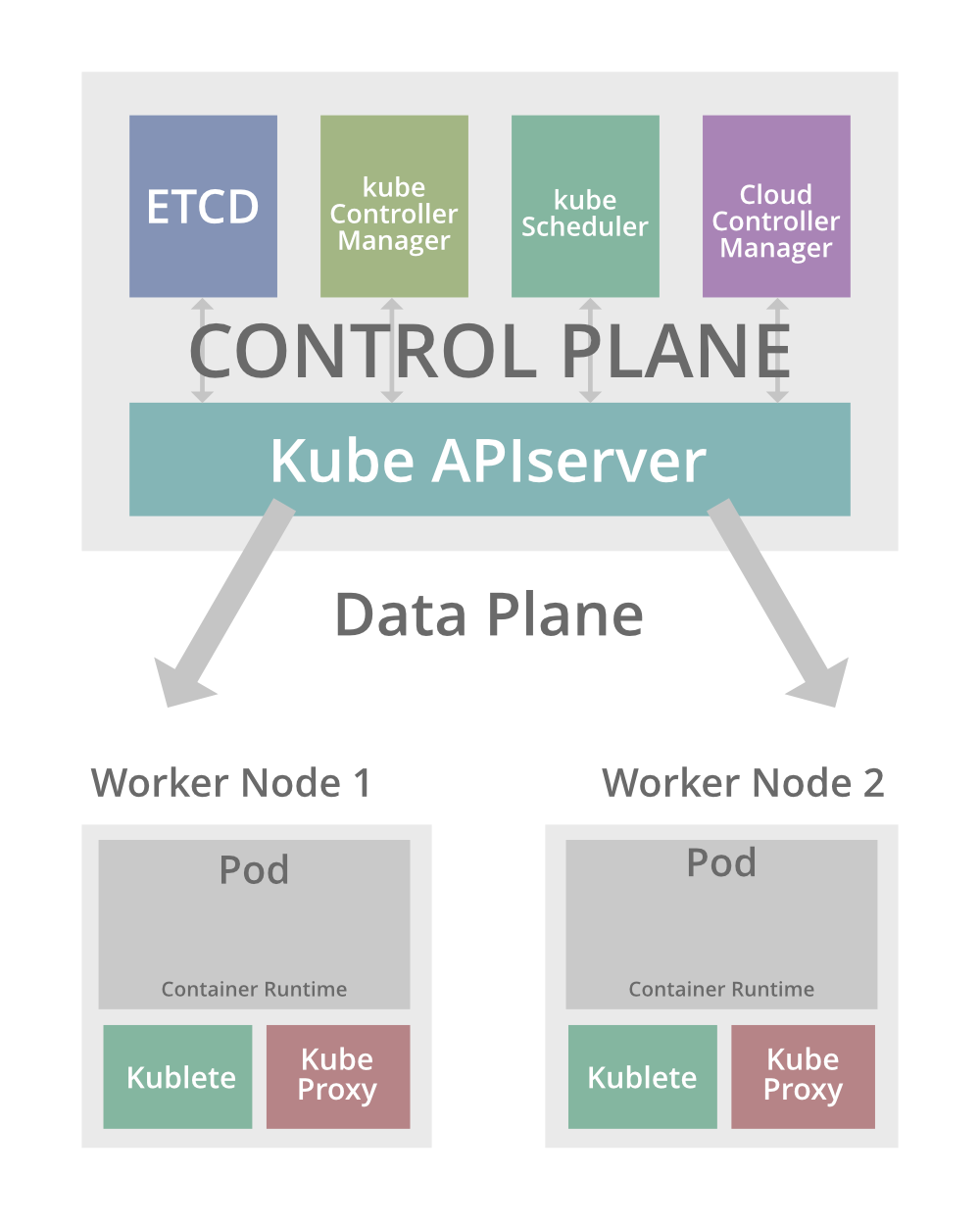
El marco de un clúster de Kubernetes
Al inspeccionar la infografía antes mencionada, puede deducir que un clúster típico de K8 está segregado en 2 unidades principales: un plano de control y un plano de datos. Profundicemos en los detalles de cada unidad y los diversos componentes integrados en cada uno de ellos.
El plano de control
El plano de control funciona como el cerebro del grupo K8s. Toma decisiones globales para el clúster y responde a los eventos del clúster. También se conoce como el Node Maestro. Esto se debe a que, en proveedores de servicios en la nube como AWS EKS, el plano de control regula el flujo de trabajo de los diversos Nodes de trabajo registrados en él. Kubernetes proporciona interfaces de red flexibles en las nubes privadas virtuales únicas (VPC) para conectar el plano de control a los Nodes de trabajo. El plano de control de EKS también permite registrar registros de auditoría y diagnóstico desde el plano de control a los registros de CloudWatch para una mejor copia de seguridad. El plano de control tiene 5 subunidades principales.
1. Servidor API de Kube : una API es una interfaz de programación de aplicaciones que permite que dos aplicaciones se comuniquen entre sí y compartan datos. Un servidor de API expone los datos de la API sin el desarrollo de aplicaciones personalizadas, lo que facilita el flujo de datos. El servidor de la API de Kube proporciona una interfaz para el clúster al autenticar y organizar el estado (datos). Después de determinar la validez del estado o la solicitud, el servidor de la API de Kube lo procesa y permite que los usuarios autenticados, los componentes externos y los componentes del clúster interactúen entre sí.
2. ETCD- Pronunciado como ‘et-cee-dee’, este es un almacén de clave-valor de código abierto (organizado jerárquicamente). Es una forma robusta y confiable de almacenar datos para ser utilizados por el clúster. ETCD permite a los usuarios leer y escribir código utilizando herramientas HTTP simples, como curl. Un punto importante a tener en cuenta es que si el clúster K8s utiliza ETCD como su almacén de respaldo principal, es obligatorio contar con un plan de respaldo bien formulado. Esto se debe a que todos los objetos de K8 se almacenan en ETCD y se necesitan bloqueos regulares para recuperar los clústeres si se pierden en escenarios catastróficos. Las instantáneas integradas de ETCD y las instantáneas de volumen son 2 amplios espectros de copias de seguridad de clústeres de ETCD. En AWS, el ETCD está completamente administrado por EKS. EKS ejecuta un ETCD dedicado y personalizado para cada clúster y ofrece flexibilidad y escalabilidad.
3. Administrador de controlador de Kube : el administrador de controlador ejecuta procesos de controlador. Es como un director de proyecto típico. Los bucles de control (sin terminación) que ejecuta inspeccionan el flujo de datos y el estado compartido del clúster mediante la API. AWS EKS Controller Manager regula los procesos del controlador para lograr el hito deseado. Por lo general, hay varios controladores que se ejecutan en un clúster. Pero para facilitar el flujo de trabajo, todos los controladores se compilan en un solo proceso.
4. Kube Scheduler : el EKS Kube Scheduler es un proceso que asigna pods a los Nodes. Decide qué Node es un recurso válido para los pods en cuestión mientras evalúa su configuración, arquetipo y propósito. Luego asigna cada pod a sus respectivos Nodes y los vincula. Hablaremos de los pods en detalle cuando profundicemos en los componentes del plano de datos.
5. Cloud Controller Manager : Cloud Controller Manager ejecuta controladores específicos de CSP. AWS EKS Cloud Controller Manager crea y administra los balanceadores de carga de AWS y los ciclos de vida de los Nodes. Esto significa que los clústeres de Kubernetes locales no los necesitan. Al igual que Kube Controller Manager, Cloud Controller Manager también tiene bucles de control compilados en un archivo. Su función principal es vincular el clúster a la API del CSP y filtrar los componentes que interactúan solo con el clúster.
El plano de datos
El plano de datos funciona como el cuerpo de un clúster de Kubernetes típico. Recibe requests e instrucciones del cerebro (plano de control) y ejecuta los procesos requeridos en los diversos Nodes trabajadores que funcionan como órganos. El plano de datos proporciona servicios como memoria, redes y almacenamiento para permitir un procesamiento flexible y dinámico hacia el estado de referencia. El plano de datos consta originalmente de varios Nodes trabajadores (máquinas virtuales) para facilitar la disponibilidad del estado y mejorar el rendimiento. Ahora discutiremos los diversos componentes de un Node de trabajo regular.
1. Pod : un pod es el objeto desplegable fundamental más pequeño dentro de un clúster de Kubernetes. Si observa la infografía nuevamente, puede ver que un pod contiene un contenedor Docker (o cualquier contenedor). El pod crea una capa de entorno en ejecución para que el contenedor se abstraiga durante el tiempo de ejecución del contenedor para permitir una interfaz de usuario. En palabras más simples, es una abstracción que contiene uno o varios acopladores/contenedores con recursos específicos del contenedor, como redes, volúmenes compartidos, etc. Por lo general, un pod admite la ejecución de una sola aplicación, pero también puede ejecutar varias aplicaciones.
2. Servicios : al igual que cada sitio web tiene una URL para identificarlo, a cada módulo se le asigna una dirección IP para facilitar la comunicación. Dado que los pods son susceptibles a daños y podrían bloquearse debido a una falla en el servicio, podrían replicarse fácilmente y recibir una nueva dirección IP más adelante. Sin embargo, una discrepancia en la dirección IP pondría en peligro la interacción de los componentes del clúster. Un servicio es una dirección IP permanente asignada a cada pod. Por lo tanto, incluso si el pod falla y se crea uno nuevo en su lugar, tendrá el mismo servicio que el pod anterior.
3. Container Runtime : Container Runtime es el software necesario para ejecutar un contenedor. En AWS EKS, el tiempo de ejecución del contenedor utilizado en el clúster puede incluso cambiar con el tiempo. Pero esto no afectaría la implementación de los Dockers.
4. Kubelet : un Kubelet es como un administrador local para los Nodes. Comprueba para asegurarse de que los contenedores se ejecutan dentro de sus respectivos pods. Kubelet no es responsable de los contenedores que no fueron creados por Kubernetes. La última versión del pod de AWS Fargate en AWS EKS se implementa con una versión de kubelet que es la misma que la de kubelet en el plano de control de clúster actualizado.
5. Proxy de Kube : el proxy de Kube es un personal de la policía de tránsito que supervisa el cumplimiento de las reglas de la red en los Nodes. Garantiza el flujo fluido del tráfico de datos. Un proxy de Kube es un complemento, pero es bastante esencial para el servicio principal. En AWS EKS, el proxy de Kube observa las reglas de red en cada Node de instancia EC2. No se implementan en los Nodes de Fargate.
Referencias:
- https://docs.aws.amazon.com/eks/latest/userguide/kubernetes-versions.html
- https://kubernetes.io/docs/concepts/overview/components/#node-components
- https://kubernetes.io/docs/tutorials/kubernetes-basics/explore/explore-intro/
- https://docs.aws.amazon.com/eks/latest/userguide/managing-kube-proxy.html
Publicación traducida automáticamente
Artículo escrito por ssanya0904 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA