Requisito previo – DBMS | Organización de archivos: conjunto 1 , Organización de archivos: conjunto 2
Organización de archivos de árbol B+ –
B+ Tree, como su nombre indica, utiliza una estructura similar a un árbol para almacenar registros en un archivo. Utiliza el concepto de indexación de claves donde la clave principal se utiliza para ordenar los registros. Para cada clave principal, se genera un valor de índice y se asigna al registro. Un índice de un registro es la dirección del registro en el archivo.
B+ Tree es muy similar al árbol de búsqueda binaria, con la única diferencia de que en lugar de solo dos hijos, puede tener más de dos. Toda la información se almacena en el Node hoja y los Nodes intermedios actúan como punteros a los Nodes hoja. La información en los Nodes hoja siempre permanece como una lista enlazada secuencial ordenada.
En el diagrama anterior, 56 es el Node raíz, que también se denomina Node principal del árbol.
Los Nodes intermedios aquí, solo consisten en la dirección de los Nodes hoja. No contienen ningún registro real. Los Nodes hoja consisten en el registro real. Todos los Nodes hoja están equilibrados.
Pros y contras de la organización de archivos de árbol B+ –
Pros –
- El recorrido del árbol es más fácil y rápido.
- La búsqueda se vuelve fácil ya que todos los registros se almacenan solo en Nodes hoja y se ordenan en una lista enlazada secuencial.
- No hay restricción en el tamaño del árbol B+. Puede crecer/reducirse a medida que aumenta/disminuye el tamaño de los datos.
Contras –
- Ineficiente para tablas estáticas.
Organización de archivos de clúster –
En la organización de archivos de clúster, dos o más tablas/registros relacionados se almacenan dentro del mismo archivo conocido como clústeres. Estos archivos tendrán dos o más tablas en el mismo bloque de datos y los atributos clave que se utilizan para mapear estas tablas juntas se almacenan solo una vez.
Por lo tanto, reduce el costo de buscar y recuperar varios registros en diferentes archivos, ya que ahora se combinan y guardan en un solo grupo.
Por ejemplo tenemos dos tablas o relación Empleado y Departamento. Estas tablas están relacionadas entre sí.
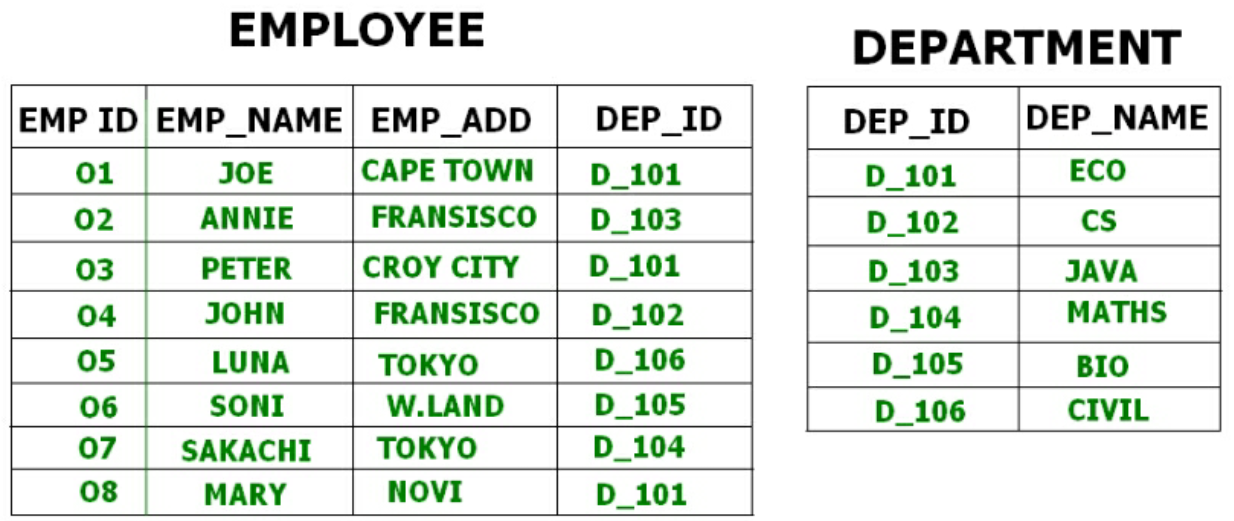
Por lo tanto, estas tablas pueden combinarse mediante una operación de combinación y pueden verse en un archivo de clúster.

Si tenemos que insertar, actualizar o eliminar algún registro podemos hacerlo directamente. Los datos se ordenan según la clave principal o la clave con la que se realiza la búsqueda. La clave de clúster es la clave con la que se realiza la unión de la tabla.
Tipos de organización de archivos de clúster: hay dos formas de implementar este método:
- Clústeres indexados:
en el agrupamiento indexado, los registros se agrupan en función de la clave del clúster y se almacenan juntos. El ejemplo mencionado anteriormente de la relación Empleado y Departamento es un ejemplo de Clúster indexado donde los registros se basan en la ID del Departamento. - Hash Clusters:
esto es muy similar al clúster indexado con la única diferencia de que, en lugar de almacenar los registros en función de la clave del clúster, generamos el valor de la clave hash y almacenamos los registros con el mismo valor de la clave hash.
Publicación traducida automáticamente
Artículo escrito por Smitha Dinesh Semwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA