El procesamiento de datos es la tarea de convertir datos de una forma determinada a una forma mucho más utilizable y deseada, es decir, haciéndolos más significativos e informativos. Usando algoritmos de aprendizaje automático, modelos matemáticos y conocimiento estadístico, todo este proceso puede automatizarse. El resultado de este proceso completo puede tener la forma deseada, como gráficos, videos, cuadros, tablas, imágenes y muchos más, según la tarea que estemos realizando y los requisitos de la máquina. Esto puede parecer simple, pero cuando se trata de organizaciones masivas como Twitter, Facebook, organismos administrativos como el Parlamento, la UNESCO y organizaciones del sector de la salud, todo este proceso debe realizarse de manera muy estructurada. Entonces, los pasos a realizar son los siguientes:
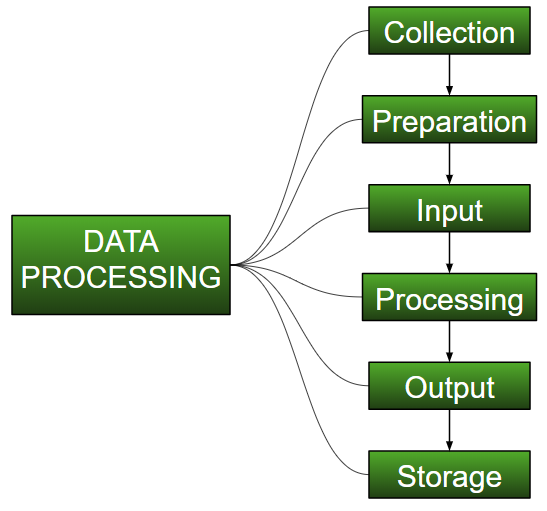
- Recopilación:
el paso más crucial al comenzar con ML es tener datos de buena calidad y precisión. Los datos se pueden recopilar de cualquier fuente autenticada como data.gov.in , Kaggle o el repositorio de conjuntos de datos de UCI . Por ejemplo, mientras se preparan para un examen competitivo, los estudiantes estudian con el mejor material de estudio al que pueden acceder para que aprendan lo mejor posible y obtengan los mejores resultados. De la misma manera, los datos precisos y de alta calidad harán que el proceso de aprendizaje del modelo sea más fácil y mejor y, en el momento de la prueba, el modelo arrojará resultados de última generación.
Se consume una gran cantidad de capital, tiempo y recursos en la recopilación de datos. Las organizaciones o los investigadores tienen que decidir qué tipo de datos necesitan para ejecutar sus tareas o investigaciones.
Ejemplo: trabajar en el reconocedor de expresiones faciales necesita numerosas imágenes que tengan una variedad de expresiones humanas. Los buenos datos aseguran que los resultados del modelo sean válidos y confiables.
- Preparación:
los datos recopilados pueden estar en una forma sin procesar que no se puede alimentar directamente a la máquina. Entonces, este es un proceso de recopilación de conjuntos de datos de diferentes fuentes, análisis de estos conjuntos de datos y luego construcción de un nuevo conjunto de datos para su posterior procesamiento y exploración. Esta preparación se puede realizar de forma manual o desde el enfoque automático. Los datos también se pueden preparar en formas numéricas, lo que aceleraría el aprendizaje del modelo.
Ejemplo: Una imagen se puede convertir a una array de dimensiones NXN, el valor de cada celda indicará el píxel de la imagen. - Entrada:
ahora los datos preparados pueden estar en un formato que puede no ser legible por máquina, por lo que para convertir estos datos al formato legible, se necesitan algunos algoritmos de conversión. Para que esta tarea se ejecute, se necesita un alto cálculo y precisión. Ejemplo: los datos se pueden recopilar a través de fuentes como datos de dígitos MNIST (imágenes), comentarios de Twitter, archivos de audio, videoclips. - Procesamiento:
esta es la etapa donde se requieren algoritmos y técnicas de ML para ejecutar las instrucciones proporcionadas sobre un gran volumen de datos con precisión y un cálculo óptimo. - Salida:
en esta etapa, la máquina obtiene los resultados de una manera significativa que el usuario puede inferir fácilmente. La salida puede ser en forma de informes, gráficos, videos, etc. - Almacenamiento:
este es el paso final en el que la salida obtenida y los datos del modelo de datos y toda la información útil se guardan para uso futuro.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA