Seaborn es una increíble biblioteca de visualización para el trazado de gráficos estadísticos en Python. Proporciona hermosos estilos predeterminados y paletas de colores para hacer que los gráficos estadísticos sean más atractivos. Está construido en la parte superior de la biblioteca matplotlib y también está estrechamente integrado en las estructuras de datos de pandas .
La tabla dinámica se utiliza para resumir datos que incluyen varios conceptos estadísticos. Para calcular el porcentaje de una categoría en una tabla dinámica, calculamos la relación entre el recuento de categorías y el recuento total. A continuación se muestran algunos ejemplos que muestran cómo incluir un porcentaje en una tabla dinámica:
Ejemplo 1:
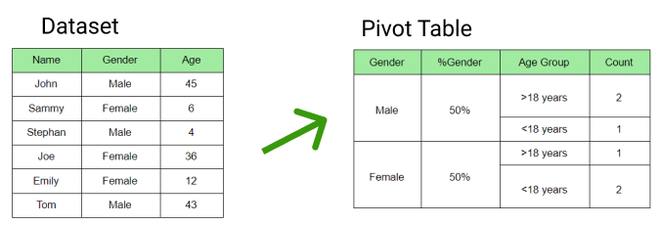
En la figura a continuación, se creó la tabla dinámica para el conjunto de datos dado donde se calculó el porcentaje de género.
Python3
# importing pandas library
import pandas as pd
# creating dataframe
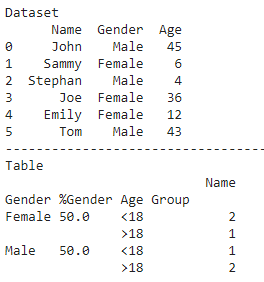
df = pd.DataFrame({'Name': ['John', 'Sammy', 'Stephan', 'Joe', 'Emily', 'Tom'],
'Gender': ['Male', 'Female', 'Male',
'Female', 'Female', 'Male'],
'Age': [45, 6, 4, 36, 12, 43]})
print("Dataset")
print(df)
print("-"*40)
# categorizing in age groups
def age_bucket(age):
if age <= 18:
return "<18"
else:
return ">18"
df['Age Group'] = df['Age'].apply(age_bucket)
# calculating gender percentage
gender = pd.DataFrame(df.Gender.value_counts(normalize=True)*100).reset_index()
gender.columns = ['Gender', '%Gender']
df = pd.merge(left=df, right=gender, how='inner', on=['Gender'])
# creating pivot table
table = pd.pivot_table(df, index=['Gender', '%Gender', 'Age Group'],
values=['Name'], aggfunc={'Name': 'count',})
# display table
print("Table")
print(table)
Producción:
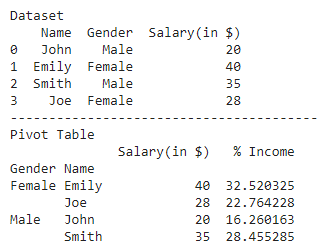
Ejemplo 2:
Aquí hay otro ejemplo que muestra cómo calcular el porcentaje de una variable a su suma total en una columna en particular:
Python3
# importing required libraries
import pandas as pd
import matplotlib.pyplot as plt
# creating dataframe
df = pd.DataFrame({
'Name': ['John', 'Emily', 'Smith', 'Joe'],
'Gender': ['Male', 'Female', 'Male', 'Female'],
'Salary(in $)': [20, 40, 35, 28]})
print("Dataset")
print(df)
print("-"*40)
# creating pivot table
table = pd.pivot_table(df, index=['Gender', 'Name'])
# calculating percentage
table['% Income'] = (table['Salary(in $)']/table['Salary(in $)'].sum())*100
# display table
print("Pivot Table")
print(table)
Producción: