El módulo BeautifulSoup en Python nos permite extraer datos de archivos HTML locales. Por alguna razón, las páginas del sitio web pueden almacenarse en un entorno local (fuera de línea) y, cuando sea necesario, puede haber requisitos para obtener los datos de ellas. A veces, también puede ser necesario obtener datos de varios archivos HTML almacenados localmente. Por lo general, los archivos HTML tienen etiquetas como <h1>, <h2>,… <p>, <div>, etc. Con BeautifulSoup, podemos descartar el contenido y obtener los detalles necesarios.
Instalación
Se puede instalar escribiendo el siguiente comando en la terminal.
pip install beautifulsoup4
Empezando
Si hay un archivo HTML almacenado en una ubicación y necesitamos eliminar el contenido a través de Python usando BeautifulSoup, lxml es una excelente API, ya que está diseñada para analizar XML y HTML. Admite tanto el análisis de un paso como el análisis paso a paso.
La función Prettify() en BeautifulSoup ayuda a ver la naturaleza de las etiquetas y su anidamiento.
Ejemplo: Vamos a crear un archivo HTML de muestra.
Python3
# Necessary imports
import sys
import urllib.request
# Save a reference to the original
# standard output
original_stdout = sys.stdout
# as an example, taken my article list
# published link page and stored in local
with urllib.request.urlopen('https://auth.geeksforgeeks.org/user/priyarajtt/articles') as webPageResponse:
outputHtml = webPageResponse.read()
# Scraped contents are placed in
# samplehtml.html file and getting
# used for next set of examples
with open('samplehtml.html', 'w') as f:
# Here the standard output is
# written to the file that we
# used above
sys.stdout = f
print(outputHtml)
# Reset the standard output to its
# original value
sys.stdout = original_stdout
Producción:
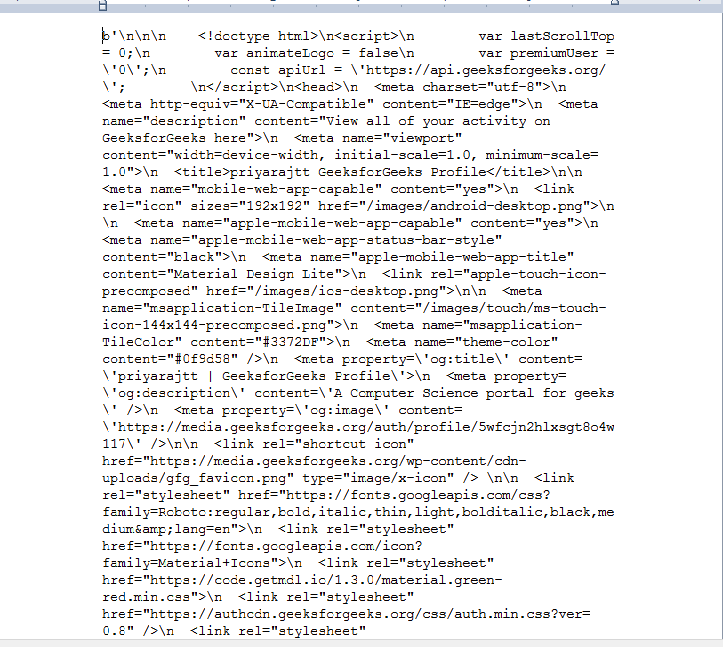
Ahora, use el método prettify() para ver las etiquetas y el contenido de una manera más fácil.
Python3
# Importing BeautifulSoup and
# it is in the bs4 module
from bs4 import BeautifulSoup
# Opening the html file. If the file
# is present in different location,
# exact location need to be mentioned
HTMLFileToBeOpened = open("samplehtml.html", "r")
# Reading the file and storing in a variable
contents = HTMLFileToBeOpened.read()
# Creating a BeautifulSoup object and
# specifying the parser
beautifulSoupText = BeautifulSoup(contents, 'lxml')
# Using the prettify method to modify the code
# Prettify() function in BeautifulSoup helps
# to view about the tag nature and their nesting
print(beautifulSoupText.body.prettify())
Producción :
De esta manera puede obtener datos HTML. Ahora haz algunas operaciones y algunas revelaciones en los datos.
Ejemplo 1:
Podemos usar métodos find() y, dado que los contenidos HTML cambian dinámicamente, es posible que no sepamos el nombre exacto de la etiqueta. En ese momento, podemos usar findAll(True) para obtener primero el nombre de la etiqueta y luego podemos realizar cualquier tipo de manipulación. Por ejemplo, obtenga el nombre de la etiqueta y la longitud de la etiqueta.
Python3
# Importing BeautifulSoup and it
# is in the bs4 module
from bs4 import BeautifulSoup
# Opening the html file. If the file
# is present in different location,
# exact location need to be mentioned
HTMLFileToBeOpened = open("samplehtml.html", "r")
# Reading the file and storing in a variable
contents = HTMLFileToBeOpened.read()
# Creating a BeautifulSoup object and
# specifying the parser
beautifulSoupText = BeautifulSoup(contents, 'lxml')
# To get all the tags present in the html
# and getting their length
for tag in beautifulSoupText.findAll(True):
print(tag.name, " : ", len(beautifulSoupText.find(tag.name).text))
Producción:
Ejemplo 2:
Ahora, en lugar de raspar un archivo HTML, queremos hacerlo con todos los archivos HTML presentes en ese directorio (puede haber necesidades para casos como diariamente, un directorio en particular puede llenarse con los datos en línea y como un proceso por lotes , se debe realizar un raspado).
Podemos usar las funcionalidades del módulo «OS». Tomemos el directorio actual todos los archivos HTML para nuestros ejemplos
Así que nuestra tarea es hacer que todos los archivos HTML se eliminen. De la siguiente manera, podemos lograr. Todos los archivos HTML de la carpeta se rasparon uno por uno y se recuperaron las etiquetas de todos los archivos, y se muestran en el video adjunto.
Python3
# necessary import for getting
# directory and filenames
import os
from bs4 import BeautifulSoup
# Get current working directory
directory = os.getcwd()
# for all the files present in that
# directory
for filename in os.listdir(directory):
# check whether the file is having
# the extension as html and it can
# be done with endswith function
if filename.endswith('.html'):
# os.path.join() method in Python join
# one or more path components which helps
# to exactly get the file
fname = os.path.join(directory, filename)
print("Current file name ..", os.path.abspath(fname))
# open the file
with open(fname, 'r') as file:
beautifulSoupText = BeautifulSoup(file.read(), 'html.parser')
# parse the html as you wish
for tag in beautifulSoupText.findAll(True):
print(tag.name, " : ", len(beautifulSoupText.find(tag.name).text))
Producción:
Publicación traducida automáticamente
Artículo escrito por priyarajtt y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA