La función Group_by() pertenece al paquete dplyr en el lenguaje de programación R, que agrupa los marcos de datos. La función Group_by() por sí sola no dará ningún resultado. Debe ir seguido de la función summarise() con una acción apropiada para realizar. Funciona de manera similar a GROUP BY en SQL y tabla dinámica en Excel.
Sintaxis:
grupo_por(col,…)
Sintaxis:
group_by(col,..) %>% resumen(acción)
El conjunto de datos en uso:
Group_by() en una sola columna
Esta es la forma más sencilla de agrupar una columna, simplemente pase el nombre de la columna que se agrupará en la función group_by() y la acción que se realizará en esta columna agrupada en la función summarise().
Ejemplo: agrupar una sola columna por group_by()
R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_region = df %>% group_by(Region) %>%
summarise(total_sales = sum(Sales),
total_profits = sum(Profit),
.groups = 'drop')
View(df_grp_region)
Producción:
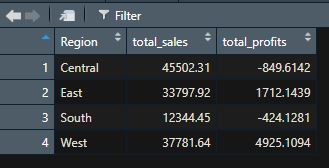
Group_by() en múltiples columnas
La función Group_by() también se puede realizar en dos o más columnas, los nombres de las columnas deben estar en el orden correcto. La agrupación ocurrirá de acuerdo con el nombre de la primera columna en la función group_by y luego la agrupación se realizará de acuerdo con la segunda columna.
Ejemplo: agrupar varias columnas
R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(total_Sales = sum(Sales),
total_Profit = sum(Profit),
.groups = 'drop')
View(df_grp_reg_cat)
Producción:
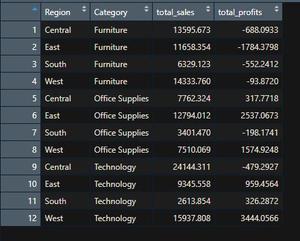
También podemos calcular la media, el recuento, el mínimo o el máximo reemplazando la suma en la función de resumen o agregación. Por ejemplo, encontraremos las ventas y las ganancias medias para el mismo ejemplo group_by anterior.
Ejemplo:
R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(mean_Sales = mean(Sales),
mean_Profit = mean(Profit),
.groups = 'drop')
View(df_grp_reg_cat)
Producción:
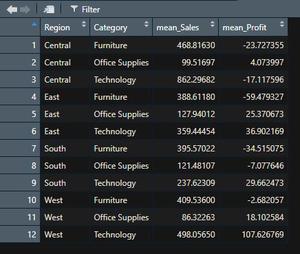
Publicación traducida automáticamente
Artículo escrito por pasulakiransai y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA