Pandas es un excelente paquete de Python para manipular datos y algunas de las herramientas que aprendemos como principiantes son funciones de agregación y agrupación de pandas.
Groupby() es una función que se utiliza para dividir los datos en el marco de datos en grupos según una condición dada. La agregación , por otro lado, opera en series, datos y devuelve un resumen numérico de los datos. Hay muchas funciones de agregación como count(),max(),min(),mean(),std(),describe() . Podemos combinar ambas funciones para encontrar múltiples agregaciones en una columna en particular. Para obtener más detalles sobre esto, consulte este artículo Cómo combinar Groupby y la función de agregación múltiple en Pandas.
En lugar de usar la agregación groupby en conjunto, podemos realizar groupby sin agregación, lo que se aplica a los datos agregados por separado. Veremos esto con un ejemplo en el que tomaremos un conjunto de datos de cáncer de mama con diferentes características numéricas como área media, peor textura y muchas más. La columna objetivo tiene 0, lo que significa que el cáncer es benigno y 1, que el cáncer es maligno.
Ejemplo 1:
Python3
# importing python libraries and breast_cancer dataset from sklearn import numpy as np import pandas as pd from sklearn import datasets from sklearn.datasets import load_breast_cancer # data is loaded in a DataFrame cancer_data = load_breast_cancer() df = pd.DataFrame(cancer_data.data, columns=cancer_data.feature_names) df['target'] = pd.Series(cancer_data.target) df.head()
Producción:
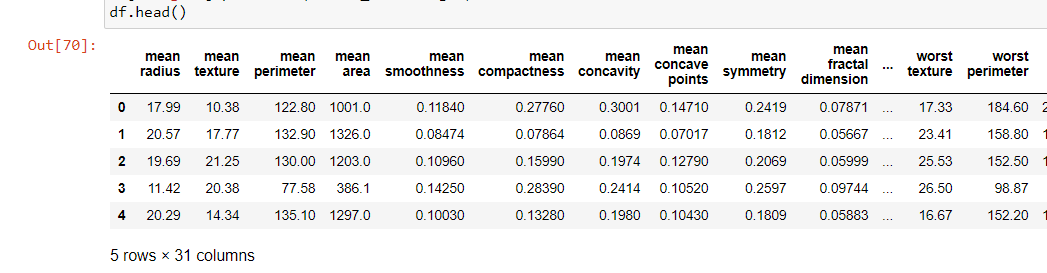
Por lo tanto, podemos visualizar los datos que tienen todas las columnas, pero todas las columnas están en forma numérica y no hay datos categóricos en lugar de solo la columna objetivo, así que echemos un vistazo en el objetivo y otra columna llamada ‘peor textura’.
Python3
print(df['target'].describe(), df['worst texture'].describe())
Producción:
count 569.000000 mean 0.627417 std 0.483918 min 0.000000 25% 0.000000 50% 1.000000 75% 1.000000 max 1.000000 Name: target, dtype: float64 count 569.000000 mean 25.677223 std 6.146258 min 12.020000 25% 21.080000 50% 25.410000 75% 29.720000 max 49.540000 Name: worst texture, dtype: float64
Aquí podemos ver el resumen de la columna objetivo y la peor textura , tomamos solo estas columnas para comprender mejor las funciones agregadas de groupby.
Python3
df1 = df[['worst texture', 'worst area', 'target']] gr1 = df1.groupby(df1['target']).mean() gr1
Producción:
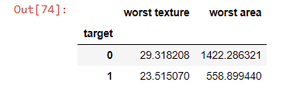
Así que aquí vemos la media de la peor textura y la peor área agrupadas alrededor del cáncer benigno y maligno, ahora los datos normales han sido interferidos por este método, y tenemos que agregarlos por separado, por eso es útil agrupar sin agregación.
Python3
# function to take the data as group and perform aggregation
def meanofTargets(group1):
wt = group1['worst texture'].agg('mean')
wa = group1['worst area'].agg('mean')
group1['Mean worst texture'] = wt
group1['Mean worst area'] = wa
return group1
df2 = df1.groupby('target').apply(meanofTargets)
df2
Producción:
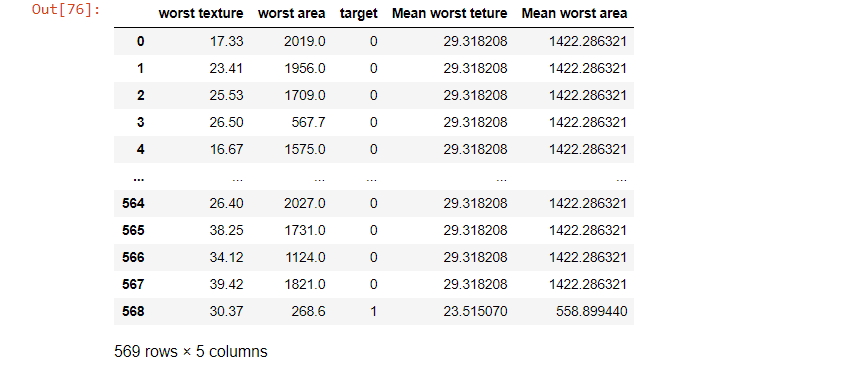
Por lo tanto, en el conjunto de datos anterior, podemos unir la media de la peor área y la peor textura en una columna separada, y lo hacemos con el método groupby de la columna objetivo donde agrupó los ‘1’ y 0′ por separado.
Ejemplo 2:
De manera similar, veamos otro ejemplo del uso de groupby sin agregación. Pero como no hay una columna categórica, tendremos que hacer una columna categórica yo mismo. Para esto, elijamos el área media que tiene un valor máximo de 2500 y un valor mínimo de 150, por lo que los clasificaremos en 6 grupos de rango 400 usando el método de corte de pandas para convertir continuos a categóricos. Como esto no se refiere al tema del artículo, consulte el repositorio de GitHub aquí para obtener más información.
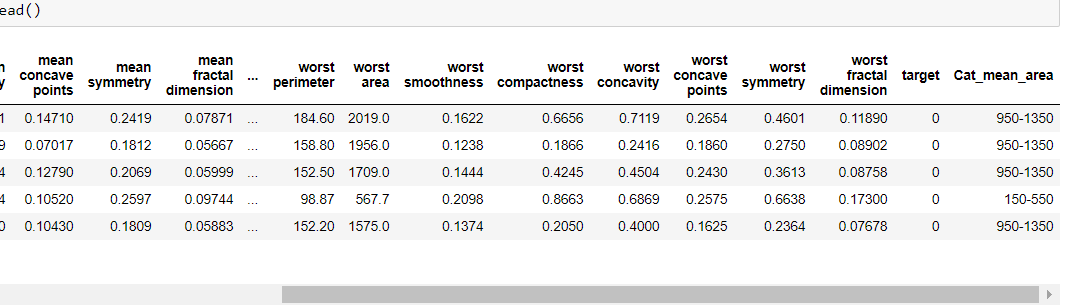
Por lo tanto, hacemos una columna categórica ‘Cat_mean_area’ y podemos realizar el método de agregación groupby aquí también. Pero en lugar de agrupar todo el conjunto de datos, podemos usar algunas columnas específicas, como solo el área media y el objetivo .
Python3
# dataframe df_3 to contain only mean_area,Cat_mean_area and target df_3 = df_2[['mean area', 'Cat_mean_area', 'target']] # applying groupby sum gr2 = df_3.groupby(df_2['Cat_mean_area']).sum() gr2
Producción:
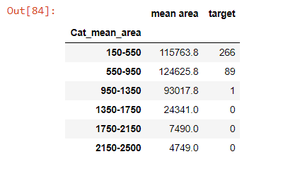
Por lo tanto, siguiendo los pasos mencionados anteriormente, realizamos groupby sin agregación.
Python3
# function to take the data as group and perform aggregation
def totalTargets(group):
g = group['target'].agg('sum')
group['Total_targets'] = g
return group
df_4 = df_3.groupby(df_3['Cat_mean_area']).apply(totalTargets)
df_4
Producción:
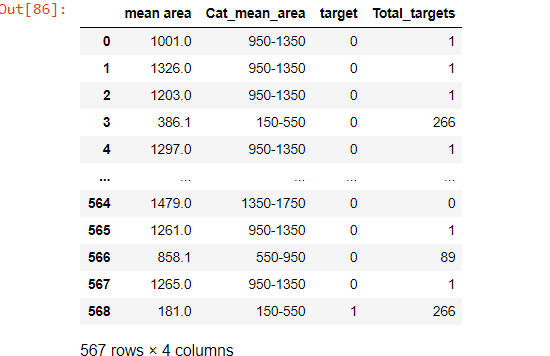
Publicación traducida automáticamente
Artículo escrito por barnadipdey2510 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA