Los datos del mundo real están llenos de valores faltantes. Para trabajar en ellos, necesitamos imputar estos valores faltantes y sacar conclusiones significativas de ellos. En este artículo, discutiremos cómo completar los valores de NaN en datos categóricos. En el caso de características categóricas, no podemos utilizar métodos de imputación estadística.
Primero, creemos un conjunto de datos de muestra para comprender los métodos para completar los valores faltantes:
Python3
# import modules
import numpy as np
import pandas as pd
# create dataset
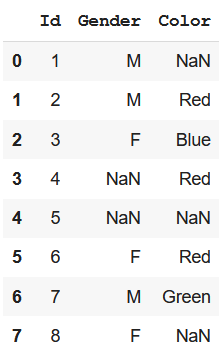
data = {'Id': [1, 2, 3, 4, 5, 6, 7, 8],
'Gender': ['M', 'M', 'F', np.nan,
np.nan, 'F', 'M', 'F'],
'Color': [np.nan, "Red", "Blue",
"Red", np.nan, "Red",
"Green", np.nan]}
# convert to data frame
df = pd.DataFrame(data)
display(df)
Producción:
Para completar los valores que faltan en las características categóricas, podemos seguir cualquiera de los enfoques que se mencionan a continuación:
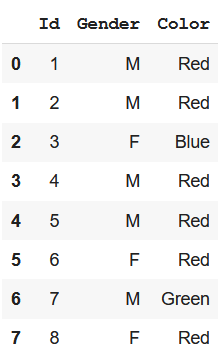
Método 1: Llenar con la clase más frecuente
Un enfoque para completar estos valores faltantes puede ser reemplazarlos con la clase más común o que ocurra. Podemos hacer esto tomando el índice de la clase más común que se puede determinar usando el método value_counts() . Veamos el ejemplo de cómo funciona:
Python3
# filling with most common class df_clean = df.apply(lambda x: x.fillna(x.value_counts().index[0])) df_clean
Producción:
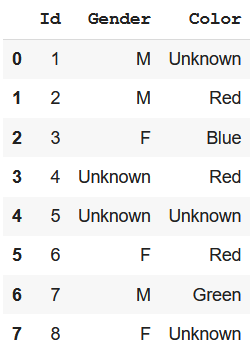
Método 2: Llenar con clase desconocida
A veces, la información que falta es valiosa en sí misma, y no será apropiado imputarla con la clase más común. En tal caso, podemos reemplazarlos con un valor como «Desconocido» o «Perdido» usando el método fillna() . Veamos un ejemplo de esto:
Python3
# filling with Unknown class
df_clean = df.fillna("Unknown")
df_clean
Producción:
Método 3: Uso de Imputer categórico de la biblioteca sklearn-pandas
Tenemos scikit learn imputer, pero solo funciona para datos numéricos. Entonces tenemos sklearn_pandas con el transformador equivalente a eso, que puede funcionar con datos de string. Reemplaza los valores faltantes con los más frecuentes en esa columna. Veamos un ejemplo de reemplazo de valores NaN de la columna «Color»:
Python3
# using sklearn-pandas package from sklearn_pandas import CategoricalImputer # handling NaN values imputer = CategoricalImputer() data = np.array(df['Color'], dtype=object) imputer.fit_transform(data)
Producción:

Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA