En este artículo, aprenderemos cómo agrupar por múltiples valores y trazar los resultados de una sola vez. Aquí, tomamos el archivo «ejercicio.csv» de un conjunto de datos de la biblioteca de Seaborn , luego formamos diferentes datos de grupo y visualizamos el resultado.
Para este procedimiento, los pasos requeridos se detallan a continuación:
- Importación de bibliotecas para datos y su visualización.
- Cree e importe los datos con varias columnas.
- Forme un objeto grouby agrupando múltiples valores.
- Visualiza los datos agrupados.
A continuación se muestra la implementación con algunos ejemplos:
Ejemplo 1 :
En este ejemplo, tomamos el archivo «ejercicio.csv» de un conjunto de datos de la biblioteca Seaborn, luego formamos datos grupales al agrupar dos columnas «pulso» y «dieta» juntas sobre la base de una columna «tiempo» y, por último, visualizamos el resultado.
Python3
# importing packages
import seaborn
# load dataset and view
data = seaborn.load_dataset('exercise')
print(data)
# multiple groupby (pulse and diet both)
df = data.groupby(['pulse', 'diet']).count()['time']
print(df)
# plot the result
df.plot()
plt.xticks(rotation=45)
plt.show()
Producción :
Unnamed: 0 id diet pulse time kind
0 0 1 low fat 85 1 min rest
1 1 1 low fat 85 15 min rest
2 2 1 low fat 88 30 min rest
3 3 2 low fat 90 1 min rest
4 4 2 low fat 92 15 min rest
.. ... .. ... ... ... ...
85 85 29 no fat 135 15 min running
86 86 29 no fat 130 30 min running
87 87 30 no fat 99 1 min running
88 88 30 no fat 111 15 min running
89 89 30 no fat 150 30 min running
[90 rows x 6 columns]
pulse diet
80 no fat NaN
low fat 1.0
82 no fat NaN
low fat 1.0
83 no fat 2.0
...
140 low fat NaN
143 no fat 1.0
low fat NaN
150 no fat 1.0
low fat NaN
Name: time, Length: 78, dtype: float64
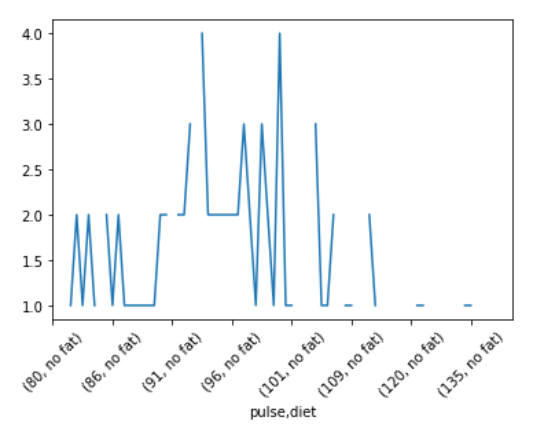
Ejemplo 2: Este ejemplo es la modificación del ejemplo anterior para una mejor visualización.
Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse and diet both)
df = data.groupby(['pulse', 'diet']).count()['time']
# plot the result
df.unstack().plot()
plt.xticks(rotation=45)
plt.show()
Producción :
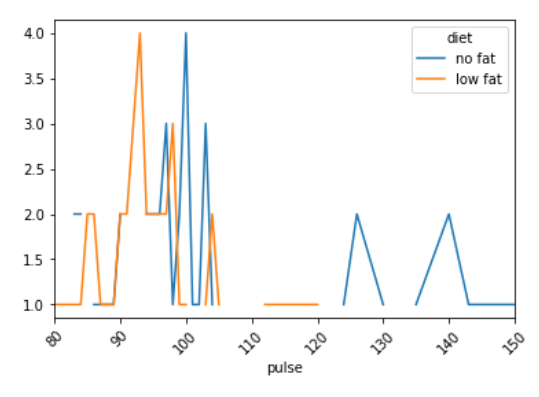
Ejemplo 3:
En este ejemplo, tomamos el archivo «ejercicio.csv» de un conjunto de datos de la biblioteca Seaborn y luego formamos datos grupales al agrupar tres columnas «pulso», «dieta» y «tiempo» juntas sobre la base de una columna «tipo» y en última visualización del resultado.
Python3
# importing packages
import seaborn
# load dataset and view
data = seaborn.load_dataset('exercise')
print(data)
# multiple groupby (pulse, diet and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
print(df)
# plot the result
df.plot()
plt.xticks(rotation=30)
plt.show()
Producción :
Unnamed: 0 id diet pulse time kind
0 0 1 low fat 85 1 min rest
1 1 1 low fat 85 15 min rest
2 2 1 low fat 88 30 min rest
3 3 2 low fat 90 1 min rest
4 4 2 low fat 92 15 min rest
.. ... .. ... ... ... ...
85 85 29 no fat 135 15 min running
86 86 29 no fat 130 30 min running
87 87 30 no fat 99 1 min running
88 88 30 no fat 111 15 min running
89 89 30 no fat 150 30 min running
[90 rows x 6 columns]
pulse diet time
80 no fat 1 min NaN
15 min NaN
30 min NaN
low fat 1 min 1.0
15 min NaN
...
150 no fat 15 min NaN
30 min 1.0
low fat 1 min NaN
15 min NaN
30 min NaN
Name: kind, Length: 234, dtype: float64
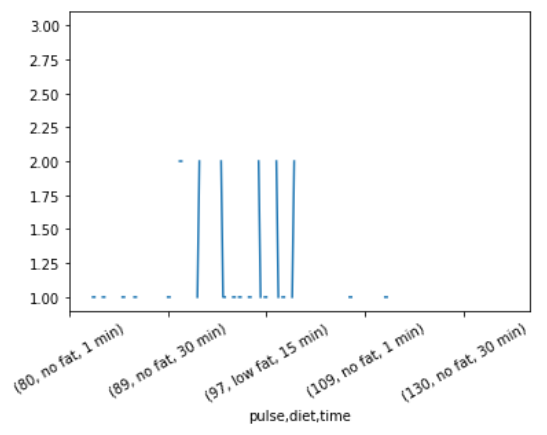
Ejemplo 4: Este ejemplo es la modificación del ejemplo anterior para una mejor visualización.
Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse, diet, and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
# plot the result
df.unsatck().plot()
plt.xticks(rotation=30)
plt.show()
Producción :
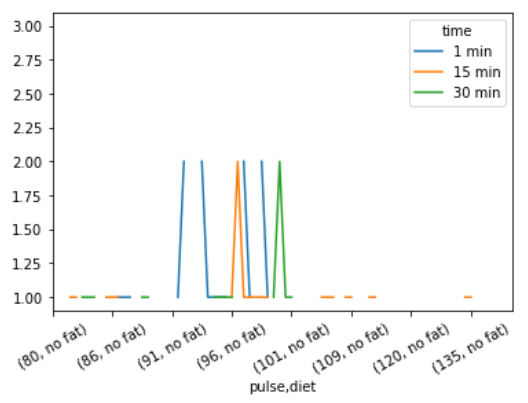
Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA