Groupby es un concepto bastante simple. Podemos crear una agrupación de categorías y aplicar una función a las categorías. Es un concepto simple, pero es una técnica extremadamente valiosa que se usa ampliamente en la ciencia de datos. En los proyectos reales de ciencia de datos, tendrá que lidiar con grandes cantidades de datos y probar cosas una y otra vez, por lo que, para mayor eficiencia, utilizamos el concepto Groupby. El concepto de agrupación es realmente importante porque su capacidad para agregar datos de manera eficiente, tanto en el rendimiento como en la cantidad de código, es magnífica. Groupby se refiere principalmente a un proceso que involucra uno o más de los siguientes pasos:
- División: es un proceso en el que dividimos los datos en grupos aplicando algunas condiciones en los conjuntos de datos.
- Aplicar: Es un proceso en el que aplicamos una función a cada grupo de forma independiente
- Combinar: es un proceso en el que combinamos diferentes conjuntos de datos después de aplicar groupby y los resultados en una estructura de datos.
La siguiente imagen ayudará a comprender un proceso involucrado en el concepto Groupby.
1. Agrupe los valores únicos de la columna Equipo
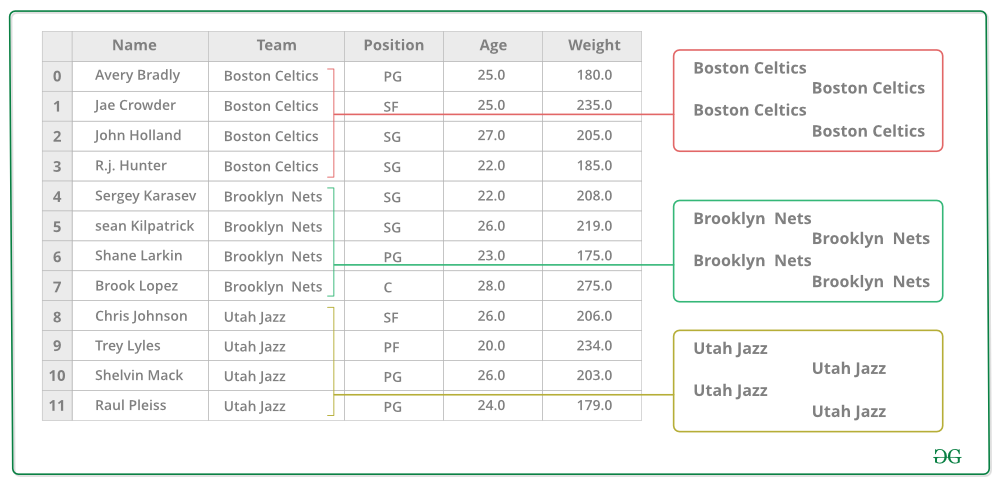
2. Ahora hay un cubo para cada grupo.
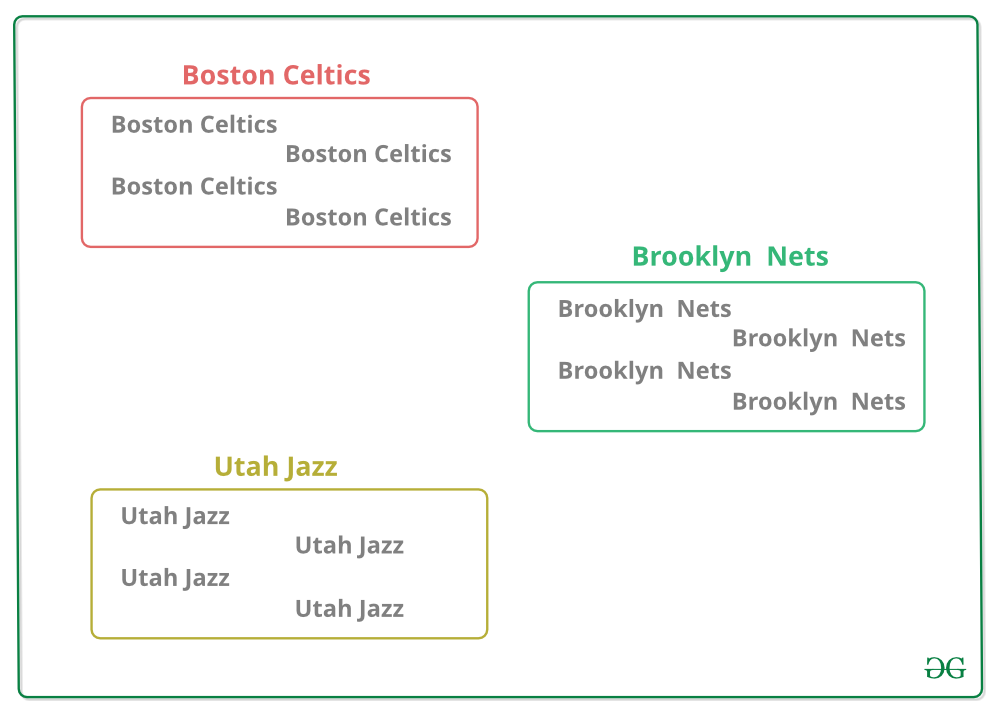
3. Mezcle los otros datos en los cubos
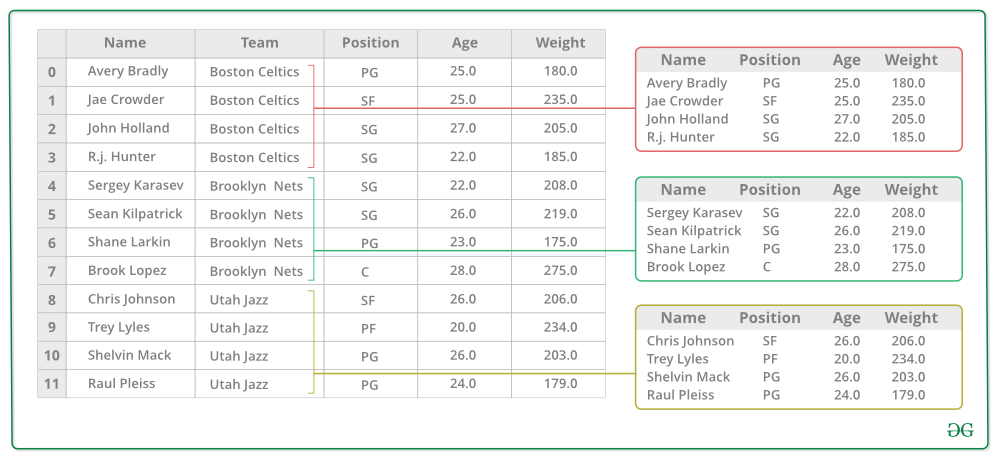
4. Aplicar una función en la columna de peso de cada balde.

División de datos en grupos
La división es un proceso en el que dividimos los datos en un grupo aplicando algunas condiciones en los conjuntos de datos. Para dividir los datos, aplicamos ciertas condiciones en los conjuntos de datos. Para dividir los datos, usamos la función groupby(), esta función se usa para dividir los datos en grupos según algunos criterios. Los objetos de Pandas se pueden dividir en cualquiera de sus ejes. La definición abstracta de agrupación es proporcionar una asignación de etiquetas a nombres de grupos. Los conjuntos de datos de Pandas se pueden dividir en cualquiera de sus objetos. Hay varias formas de dividir datos como:
- obj.groupby(clave)
- obj.groupby(clave, eje=1)
- obj.groupby([clave1, clave2])
Nota: En esto nos referimos a los objetos de agrupación como las claves.
Agrupación de datos con una clave:
para agrupar datos con una clave, pasamos solo una clave como argumento en la función groupby.
Python3
# importing pandas module
import pandas as pd
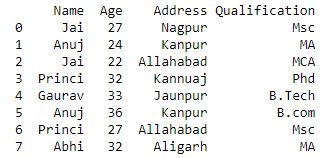
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora agrupamos un dato de Nombre usando la función groupby().
Python3
# using groupby function
# with one key
df.groupby('Name')
print(df.groupby('Name').groups)
Producción :
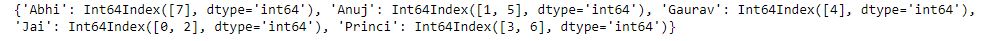
Ahora imprimimos las primeras entradas en todos los grupos formados.
Python3
# applying groupby() function to
# group the data on Name value.
gk = df.groupby('Name')
# Let's print the first entries
# in all the groups formed.
gk.first()
Producción :
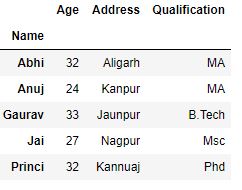
Agrupación de datos con varias claves:
para agrupar datos con varias claves, pasamos varias claves en la función groupby.
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora agrupamos los datos de «Nombre» y «Calificación» usando varias teclas en la función groupby.
Python3
# Using multiple keys in # groupby() function df.groupby(['Name', 'Qualification']) print(df.groupby(['Name', 'Qualification']).groups)
Producción :

Agrupación de datos por claves de clasificación:
las claves de grupo se ordenan de forma predeterminada mediante la operación groupby. El usuario puede pasar sort=False para posibles aceleraciones.
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32], }
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
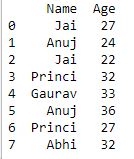
Ahora aplicamos groupby() sin ordenar
Python3
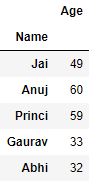
# using groupby function # without using sort df.groupby(['Name']).sum()
Producción :

Ahora aplicamos groupby() usando sort para lograr posibles aceleraciones
Python3
# using groupby function # with sort df.groupby(['Name'], sort = False).sum()
Producción :
Agrupación de datos con atributos de objeto: el atributo
de grupos es como un diccionario cuyas claves son los grupos únicos calculados y los valores correspondientes son las etiquetas de los ejes que pertenecen a cada grupo.
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora agrupamos datos como lo hacemos en un diccionario usando claves.
Python3
# using keys for grouping
# data
df.groupby('Name').groups
Producción :

Iterando a través de grupos
Para iterar un elemento de grupos, podemos iterar a través del objeto similar a itertools.obj.
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora iteramos un elemento de grupo de manera similar a como lo hacemos en itertools.obj.
Python3
# iterating an element
# of group
grp = df.groupby('Name')
for name, group in grp:
print(name)
print(group)
print()
Producción :
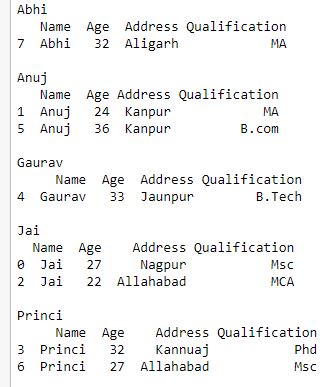
Ahora iteramos un elemento de grupo que contiene varias claves.
Python3
# iterating an element # of group containing # multiple keys grp = df.groupby(['Name', 'Qualification']) for name, group in grp: print(name) print(group) print()
Salida:
como se muestra en la salida, el nombre del grupo será tupla
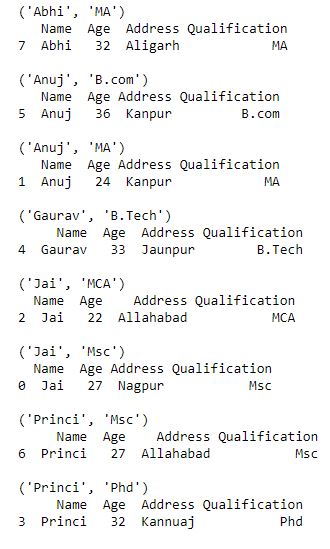
Selección de un grupo
Para seleccionar un grupo, podemos seleccionar el grupo usando GroupBy.get_group(). Podemos seleccionar un grupo aplicando una función GroupBy.get_group esta función selecciona un solo grupo.
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora seleccionamos un solo grupo usando Groupby.get_group.
Python3
# selecting a single group
grp = df.groupby('Name')
grp.get_group('Jai')
Producción :

Ahora seleccionamos un objeto agrupado en varias columnas.
Python3
# selecting object grouped
# on multiple columns
grp = df.groupby(['Name', 'Qualification'])
grp.get_group(('Jai', 'Msc'))
Producción :

Aplicando función al grupo
Después de dividir un dato en un grupo, aplicamos una función a cada grupo para que realicemos alguna operación que son:
- Agregación: es un proceso en el que calculamos una estadística de resumen (o estadísticas) sobre cada grupo. Por ejemplo, calcular sumas o medias de grupos
- Transformación: es un proceso en el que realizamos algunos cálculos específicos del grupo y devolvemos un índice similar. Por ejemplo, llenar NA dentro de grupos con un valor derivado de cada grupo
- Filtración: Es un proceso en el que descartamos algunos grupos, según un cómputo por grupos que evalúa Verdadero o Falso. Por ejemplo, filtrar datos según la suma o la media del grupo
Agregación:
la agregación es un proceso en el que calculamos una estadística de resumen sobre cada grupo. La función agregada devuelve un único valor agregado para cada grupo. Después de dividir los datos en grupos usando la función groupby, se pueden realizar varias operaciones de agregación en los datos agrupados.
Código #1: Uso de la agregación a través del método agregado
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora realizamos la agregación usando el método agregado.
Python3
# performing aggregation using
# aggregate method
grp1 = df.groupby('Name')
grp1.aggregate(np.sum)
Producción :
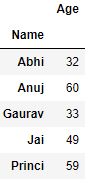
Ahora realizamos la agregación en un grupo que contiene varias claves
Python3
# performing aggregation on # group containing multiple # keys grp1 = df.groupby(['Name', 'Qualification']) grp1.aggregate(np.sum)
Producción :
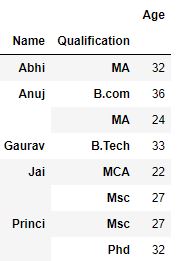
Aplicar varias funciones a la vez:
podemos aplicar varias funciones a la vez pasando una lista o un diccionario de funciones para hacer la agregación, generando un DataFrame.
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora aplicamos funciones múltiples pasando una lista de funciones.
Python3
# applying a function by passing
# a list of functions
grp = df.groupby('Name')
grp['Age'].agg([np.sum, np.mean, np.std])
Producción :
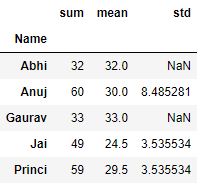
Aplicar diferentes funciones a las columnas de DataFrame:
para aplicar una agregación diferente a las columnas de un DataFrame, podemos pasar un diccionario para agregar.
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
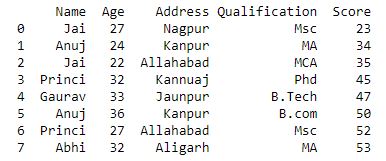
Ahora aplicamos una agregación diferente a las columnas de un marco de datos.
Python3
# using different aggregation
# function by passing dictionary
# to aggregate
grp = df.groupby('Name')
grp.agg({'Age' : 'sum', 'Score' : 'std'})
Producción :
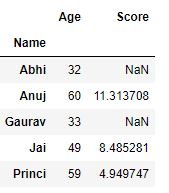
Transformación:
la transformación es un proceso en el que realizamos algunos cálculos específicos del grupo y devolvemos un índice similar. El método de transformación devuelve un objeto que está indexado del mismo (mismo tamaño) que el que se está agrupando. La función de transformación debe:
- Devolver un resultado que sea del mismo tamaño que el fragmento del grupo
- Operar columna por columna en el fragmento de grupo
- No realizar operaciones in situ en el fragmento de grupo.
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
Ahora realizamos algunos cálculos específicos del grupo y devolvemos un índice similar.
Python3
# using transform function
grp = df.groupby('Name')
sc = lambda x: (x - x.mean()) / x.std()*10
grp.transform(sc)
Producción :
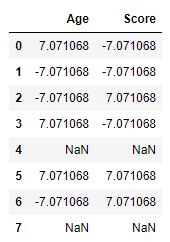
Filtración:
La filtración es un proceso en el que descartamos algunos grupos, de acuerdo con un cálculo por grupos que evalúa Verdadero o Falso. Para filtrar un grupo, usamos el método de filtro y aplicamos alguna condición por la cual filtramos el grupo.
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
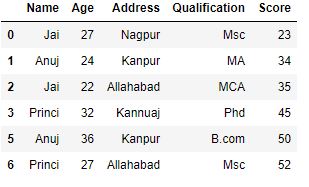
Ahora filtramos los datos para devolver el Nombre que ha vivido dos o más veces.
Python3
# filtering data using
# filter data
grp = df.groupby('Name')
grp.filter(lambda x: len(x) >= 2)
Producción :
Publicación traducida automáticamente
Artículo escrito por ABHISHEK TIWARI 13 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA