Como todos sabemos, Hadoop es un marco escrito en Java que utiliza un gran grupo de hardware básico para mantener y almacenar datos de gran tamaño. Hadoop funciona con el algoritmo de programación MapReduce que introdujo Google. Hoy en día, muchas empresas de grandes marcas están utilizando Hadoop en su organización para manejar grandes datos, por ejemplo. Facebook, Yahoo, Netflix, eBay, etc. La arquitectura de Hadoop consta principalmente de 4 componentes.
- Mapa reducido
- HDFS (Sistema de archivos distribuido Hadoop)
- YARN (otro marco de recursos más)
- Utilidades comunes o Hadoop Common
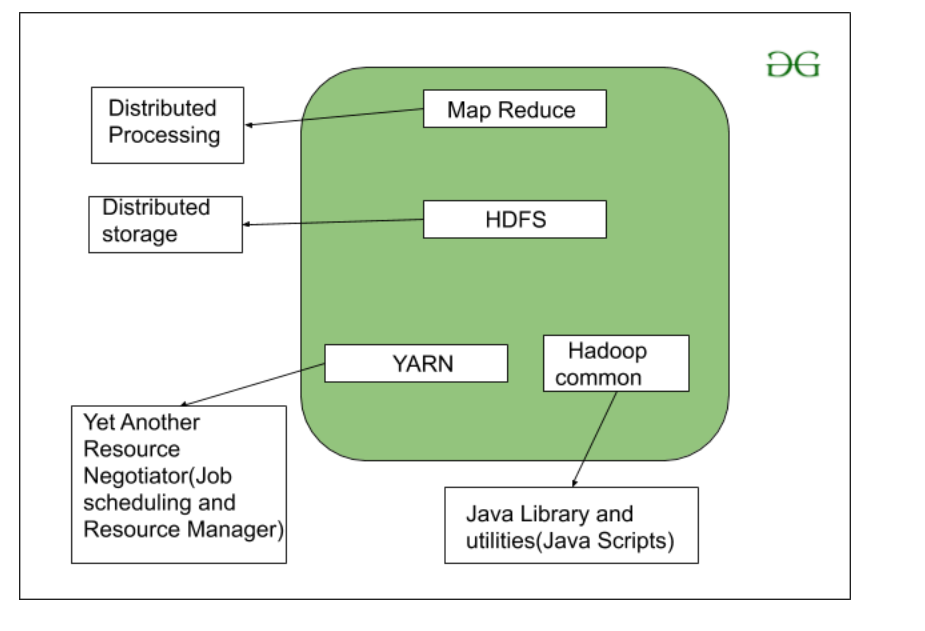
Comprendamos el papel de cada uno de este componente en detalle.
1. MapReducir
MapReduce no es más que un algoritmo o una estructura de datos que se basa en el marco YARN. La característica principal de MapReduce es realizar el procesamiento distribuido en paralelo en un clúster de Hadoop, lo que hace que Hadoop funcione tan rápido. Cuando se trata de Big Data, el procesamiento en serie ya no sirve de nada. MapReduce tiene principalmente 2 tareas que se dividen en fases:
En la primera fase, se utiliza Map y en la siguiente fase se utiliza Reduce .
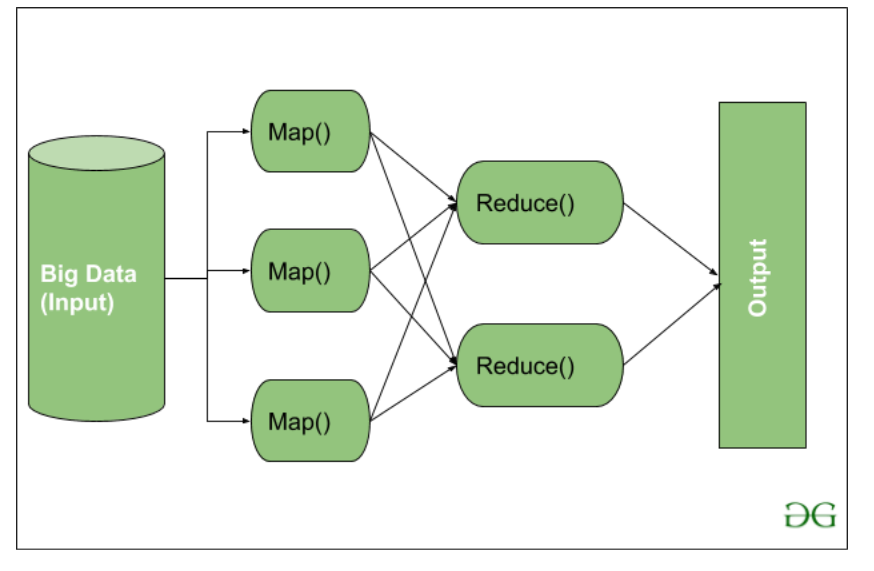
Aquí, podemos ver que la entrada se proporciona a la función Map(), luego su salida se usa como entrada a la función Reducir y después de eso, recibimos nuestra salida final. Entendamos lo que hace Map() y Reduce().
Como podemos ver, se proporciona una entrada a Map(), ahora que estamos usando Big Data. La entrada es un conjunto de datos. La función Map() aquí divide estos bloques de datos en tuplas que no son más que un par clave-valor. Estos pares clave-valor ahora se envían como entrada a Reduce(). La función Reduce() luego combina estas tuplas rotas o el par clave-valor en función de su valor clave y el conjunto de formularios de tuplas, y realiza alguna operación como clasificación, trabajo de tipo de suma, etc., que luego se envía al Node de salida final. Finalmente, se obtiene la salida.
El procesamiento de datos siempre se realiza en Reducer según los requisitos comerciales de esa industria. Así es como se utilizan primero Map() y luego Reduce uno por uno.
Comprendamos la tarea de mapa y la tarea de reducción en detalle.
Tarea de mapa:
- RecordReader El propósito de recordreader es romper los récords. Es responsable de proporcionar pares clave-valor en una función Map(). La clave es en realidad su información de ubicación y el valor son los datos asociados con él.
- Mapa: Un mapa no es más que una función definida por el usuario cuyo trabajo es procesar las Tuplas obtenidas del lector de registros. La función Map() no genera ningún par clave-valor o genera varios pares de estas tuplas.
- Combiner: Combiner se utiliza para agrupar los datos en el flujo de trabajo del mapa. Es similar a un reductor local. El valor-clave intermedio que se genera en el Mapa se combina con la ayuda de este combinador. El uso de un combinador no es necesario ya que es opcional.
- Particionado: el particionado es responsable de obtener los pares clave-valor generados en las fases del mapeador. El particionador genera los fragmentos correspondientes a cada reductor. Esta partición también obtiene el código hash de cada clave. Luego, el particionador realiza su módulo (Hashcode) con el número de reductores ( key.hashcode()% (número de reductores)).
Reducir tarea
- Shuffle and Sort: la tarea de Reducer comienza con este paso, el proceso en el que Mapper genera el valor-clave intermedio y los transfiere a la tarea de Reducer se conoce como Shuffling . Mediante el proceso de barajado, el sistema puede ordenar los datos utilizando su valor clave.
Una vez que se realizan algunas de las tareas de mapeo, comienza la reproducción aleatoria, por lo que es un proceso más rápido y no espera a que finalice la tarea realizada por Mapper.
- Reducir: la función o tarea principal de Reduce es recopilar la tupla generada a partir de Map y luego realizar algún tipo de proceso de clasificación y agregación en esos valores clave según su elemento clave.
- Formato de salida: una vez que se realizan todas las operaciones, los pares clave-valor se escriben en el archivo con la ayuda del escritor de registros, cada registro en una nueva línea y la clave y el valor separados por espacios.
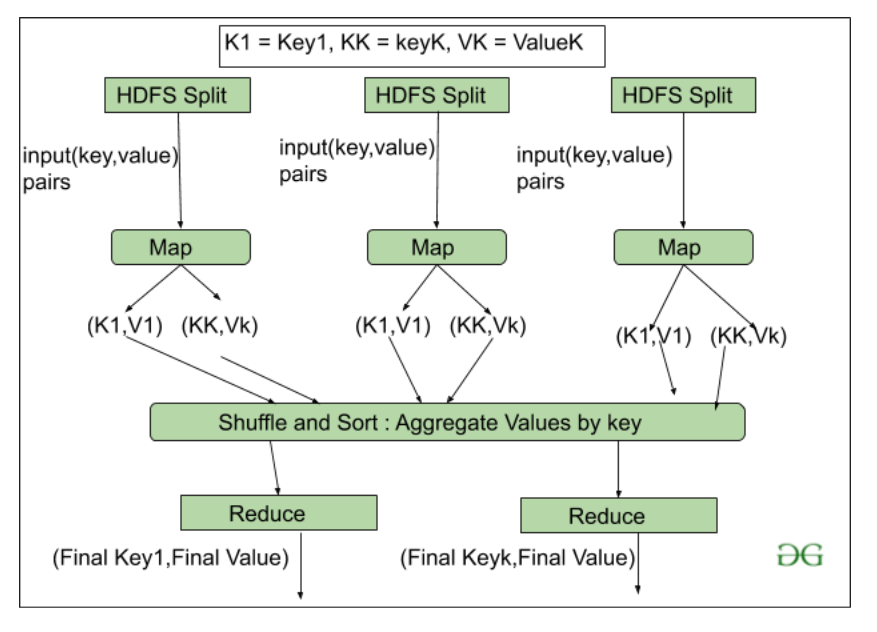
2. HDFS
HDFS (Sistema de archivos distribuidos de Hadoop) se utiliza para el permiso de almacenamiento en un clúster de Hadoop. Está diseñado principalmente para trabajar en dispositivos de hardware básicos (dispositivos económicos), trabajando en un diseño de sistema de archivos distribuido. HDFS está diseñado de tal manera que cree más en almacenar los datos en una gran cantidad de bloques en lugar de almacenar pequeños bloques de datos.
HDFS en Hadoop proporciona tolerancia a fallas y alta disponibilidad para la capa de almacenamiento y los demás dispositivos presentes en ese clúster de Hadoop. Nodes de almacenamiento de datos en HDFS.
- NodeNombre(Maestro)
- Node de datos (esclavo)
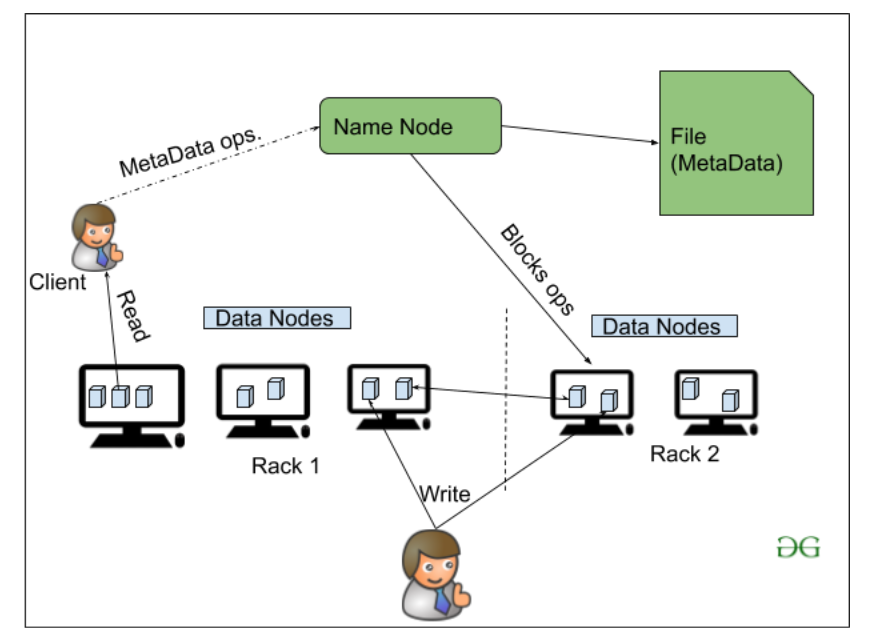
NameNode: NameNode funciona como maestro en un clúster de Hadoop que guía el Datanode (esclavos). Namenode se utiliza principalmente para almacenar los metadatos, es decir, los datos sobre los datos. Los metadatos pueden ser los registros de transacciones que realizan un seguimiento de la actividad del usuario en un clúster de Hadoop.
Los metadatos también pueden ser el nombre del archivo, el tamaño y la información sobre la ubicación (número de bloque, identificadores de bloque) de Datanode que Namenode almacena para encontrar el DataNode más cercano para una comunicación más rápida. Namenode instruye a los DataNodes con la operación como eliminar, crear, replicar, etc.
DataNode: DataNodes funciona como un esclavo. Los DataNodes se utilizan principalmente para almacenar los datos en un clúster de Hadoop, la cantidad de DataNodes puede ser de 1 a 500 o incluso más. Cuanto mayor sea el número de DataNode, el clúster de Hadoop podrá almacenar más datos. Por lo tanto, se recomienda que DataNode tenga una capacidad de almacenamiento alta para almacenar una gran cantidad de bloques de archivos.
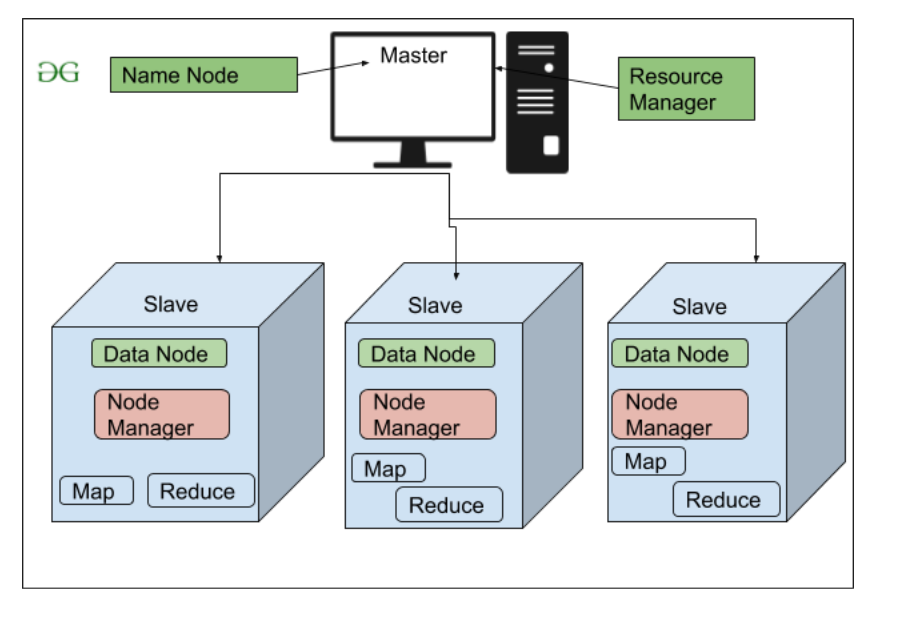
Arquitectura de alto nivel de Hadoop
Bloque de archivos en HDFS: los datos en HDFS siempre se almacenan en términos de bloques. Entonces, el bloque único de datos se divide en varios bloques de 128 MB de tamaño, que es el valor predeterminado y también puede cambiarlo manualmente.
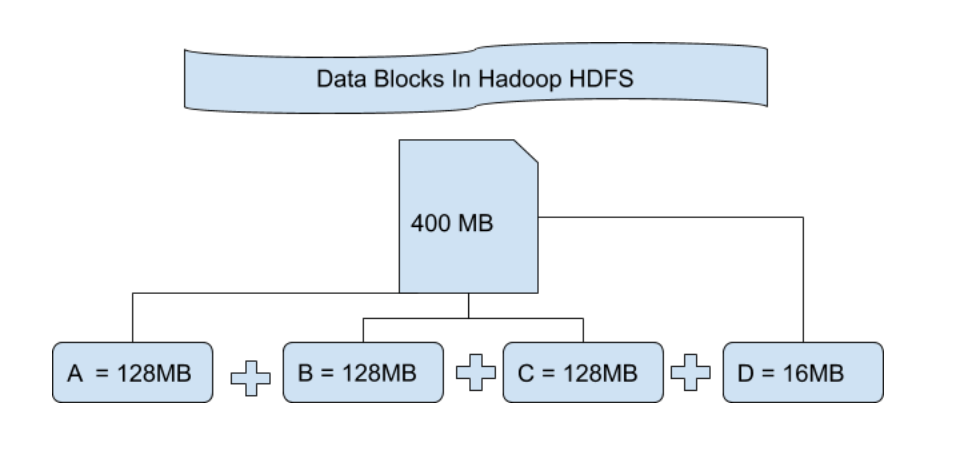
Entendamos este concepto de dividir un archivo en bloques con un ejemplo. Supongamos que ha cargado un archivo de 400 MB en su HDFS, lo que sucede es que este archivo se dividió en bloques de 128 MB + 128 MB + 128 MB + 16 MB = 400 MB de tamaño. Significa que se crean 4 bloques cada uno de 128 MB excepto el último. Hadoop no sabe o no le importa qué datos se almacenan en estos bloques, por lo que considera los bloques de archivos finales como un registro parcial, ya que no tiene idea al respecto. En el sistema de archivos de Linux, el tamaño de un bloque de archivos es de aproximadamente 4 KB, que es mucho menor que el tamaño predeterminado de los bloques de archivos en el sistema de archivos de Hadoop. Como todos sabemos, Hadoop está configurado principalmente para almacenar datos de gran tamaño en petabytes, esto es lo que hace que el sistema de archivos de Hadoop sea diferente de otros sistemas de archivos, ya que se puede escalar.
Replicación En HDFS La replicación asegura la disponibilidad de los datos. La replicación es hacer una copia de algo y la cantidad de veces que hace una copia de esa cosa en particular se puede expresar como su factor de replicación. Como hemos visto en Bloques de archivos, HDFS almacena los datos en forma de varios bloques al mismo tiempo, Hadoop también está configurado para hacer una copia de esos bloques de archivos.
De forma predeterminada, el factor de replicación para Hadoop se establece en 3, lo que se puede configurar, lo que significa que puede cambiarlo manualmente según sus requisitos, como en el ejemplo anterior, hemos creado 4 bloques de archivos, lo que significa que se realizan 3 réplicas o copias de cada bloque de archivos. se hacen un total de 4×3 = 12 bloques para el propósito de la copia de seguridad.
Esto se debe a que, para ejecutar Hadoop, utilizamos hardware básico (hardware de sistema económico) que puede fallar en cualquier momento. No estamos usando la supercomputadora para nuestra configuración de Hadoop. Es por eso que necesitamos una función de este tipo en HDFS que pueda hacer copias de esos bloques de archivos con fines de respaldo, esto se conoce como tolerancia a fallas.
Ahora, una cosa que también debemos tener en cuenta es que después de hacer tantas réplicas de nuestros bloques de archivos, estamos desperdiciando gran parte de nuestro almacenamiento, pero para la organización de grandes marcas, los datos son mucho más importantes que el almacenamiento, por lo que a nadie le importa este almacenamiento adicional. Puede configurar el factor de replicación en su archivo hdfs-site.xml .
Conocimiento del rack El rack no es más que la colección física de Nodes en nuestro clúster de Hadoop (quizás 30 o 40). Un gran clúster de Hadoop consta de tantos bastidores. con la ayuda de esta información de Racks, Namenode elige el Datanode más cercano para lograr el máximo rendimiento mientras realiza la lectura/escritura de información que reduce el tráfico de red.
Arquitectura HDFS
3. YARN (Otro negociador de recursos más)
YARN es un marco en el que funciona MapReduce. YARN realiza 2 operaciones que son la programación de trabajos y la gestión de recursos. El propósito del programador de trabajos es dividir una tarea grande en trabajos pequeños para que cada trabajo se pueda asignar a varios esclavos en un clúster de Hadoop y se pueda maximizar el procesamiento. Job Scheduler también realiza un seguimiento de qué trabajo es importante, qué trabajo tiene más prioridad, las dependencias entre los trabajos y toda la demás información, como el tiempo de trabajo, etc. Y el uso de Resource Manager es administrar todos los recursos que están disponibles para ejecutar un clúster de Hadoop.
Características del HILO
- Multi Alquiler
- Escalabilidad
- Utilización de clúster
- Compatibilidad
4. Utilidades comunes o comunes de Hadoop
Las utilidades comunes o comunes de Hadoop no son más que nuestra biblioteca java y archivos java o podemos decir los scripts java que necesitamos para todos los demás componentes presentes en un clúster de Hadoop. HDFS, YARN y MapReduce utilizan estas utilidades para ejecutar el clúster. Hadoop Common verifica que la falla de hardware en un clúster de Hadoop sea común, por lo que Hadoop Framework debe resolverla automáticamente en el software.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA