Dado un texto txt[0..n-1] y un patrón pat[0..m-1], escriba una función de búsqueda (char pat[], char txt[]) que imprima todas las apariciones de pat[] en txt []. Puede suponer que n > m.
Ejemplos:
Input: txt[] = "THIS IS A TEST TEXT"
pat[] = "TEST"
Output: Pattern found at index 10
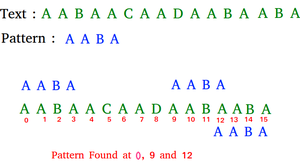
Input: txt[] = "AABAACAADAABAABA"
pat[] = "AABA"
Output: Pattern found at index 0
Pattern found at index 9
Pattern found at index 12
El algoritmo Naive String Matching desliza el patrón uno por uno. Después de cada diapositiva, uno por uno verifica los caracteres en el turno actual y, si todos los caracteres coinciden, imprime la coincidencia. Al igual que el algoritmo Naive, el algoritmo de Rabin-Karp también desliza el patrón uno por uno. Pero a diferencia del algoritmo Naive, el algoritmo Rabin Karp hace coincidir el valor hash del patrón con el valor hash de la substring de texto actual, y si los valores hash coinciden, solo comienza a hacer coincidir los caracteres individuales. Entonces, el algoritmo de Rabin Karp necesita calcular valores hash para las siguientes strings. 1) Patrón en sí. 2) Todas las substrings del texto de longitud m.
Python
# Following program is the python implementation of # Rabin Karp Algorithm given in CLRS book # d is the number of characters in the input alphabet d = 256 # pat -> pattern # txt -> text # q -> A prime number def search(pat, txt, q): M = len(pat) N = len(txt) i = 0 j = 0 p = 0 # hash value for pattern t = 0 # hash value for txt h = 1 # The value of h would be "pow(d, M-1)% q" for i in xrange(M-1): h = (h * d)% q # Calculate the hash value of pattern and first window # of text for i in xrange(M): p = (d * p + ord(pat[i]))% q t = (d * t + ord(txt[i]))% q # Slide the pattern over text one by one for i in xrange(N-M + 1): # Check the hash values of current window of text and # pattern if the hash values match then only check # for characters on by one if p == t: # Check for characters one by one for j in xrange(M): if txt[i + j] != pat[j]: break j+= 1 # if p == t and pat[0...M-1] = txt[i, i + 1, ...i + M-1] if j == M: print "Pattern found at index " + str(i) # Calculate hash value for next window of text: Remove # leading digit, add trailing digit if i < N-M: t = (d*(t-ord(txt[i])*h) + ord(txt[i + M]))% q # We might get negative values of t, converting it to # positive if t < 0: t = t + q # Driver program to test the above function txt = "GEEKS FOR GEEKS" pat = "GEEK" q = 101 # A prime number search(pat, txt, q) # This code is contributed by Bhavya Jain
Pattern found at index 0 Pattern found at index 10
Complejidad Temporal: O(nm), donde m es la longitud del patrón yn es la longitud
Espacio Auxiliar: O(1).
Consulte el artículo completo sobre el algoritmo de Rabin-Karp para la búsqueda de patrones para obtener más detalles.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA