Muchos de nosotros somos conscientes del control de versiones cuando se trata de trabajar con varios desarrolladores en un solo proyecto y colaborar con ellos. No hay duda de que el control de versiones hace que los desarrolladores trabajen más fácil y rápido. En la mayor parte de la organización, los desarrolladores utilizan el Sistema de control de versiones centralizado (CVCS) como Subversion (SVN) o el Sistema de versiones simultáneas (CVS) o el Sistema de control de versiones distribuido (DVCS) como Git (escrito en C ), Mercurial (escrito en Python ) o Bazar (Escrito en Python).
Ahora vamos al grano, ¿cuál es mejor o cuál debemos elegir? Compararemos el flujo de trabajo, la curva de aprendizaje, la seguridad, la popularidad y otros aspectos de cada uno.
En primer lugar, debemos romper el mito que tienen la mayoría de los principiantes sobre DVCS: » No hay una versión central en el código ni una rama maestra «. Eso no es cierto, en DVCS también hay una rama maestra o una versión central en el código , pero funciona de manera diferente al control de fuente centralizado.

Repasemos la descripción general de ambos sistemas de control de versiones.
Sistema de control de versiones centralizado
En el control de fuente centralizado, hay un servidor y un cliente. El servidor es el depósito principal que contiene todas las versiones del código. Para trabajar en cualquier proyecto, en primer lugar, el usuario o cliente debe obtener el código del repositorio principal o del servidor. Entonces, el cliente se comunica con el servidor y extrae todo el código o la versión actual del código del servidor a su máquina local. En otros términos, podemos decir que debe realizar una actualización del repositorio principal y luego obtener la copia local del código en su sistema. Entonces, una vez que obtenga la última versión del código, comience a realizar sus propios cambios en el código y, después de eso, simplemente debe confirmar esos cambios directamente en el repositorio principal. Confirmar un cambio simplemente significa fusionar su propio código en el repositorio principal o crear una nueva versión del código fuente.
Habrá un solo repositorio y ese contendrá todo el historial o versión del código y diferentes ramas del código. Por lo tanto, el flujo de trabajo básico que implica el control de fuente centralizado es obtener la última versión del código de un repositorio central que también contendrá el código de otras personas, realizar sus propios cambios en el código y luego confirmar o fusionar esos cambios en el repositorio central. .
Sistema de control de versiones distribuido
En el control de versiones distribuido, la mayor parte del mecanismo o modelo se aplica igual que el centralizado. La única gran diferencia que encontrará aquí es que, en lugar de un único repositorio que es el servidor, aquí cada desarrollador o cliente tiene su propio servidor y tendrá una copia de todo el historial o versión del código y todas sus ramas. en su servidor o máquina local. Básicamente, cada cliente o usuario puede trabajar localmente y desconectado, lo cual es más conveniente que el control de fuente centralizado y por eso se llama distribuido.
No necesita confiar en el servidor central, puede clonar todo el historial o copiar el código en su disco duro. Entonces, cuando comienza a trabajar en un proyecto, clona el código del repositorio principal en su propio disco duro, luego obtiene el código de su propio repositorio para realizar cambios y, después de realizar los cambios, envía los cambios a su repositorio local y en En este punto, su repositorio local tendrá ‘ conjuntos de cambios ‘ pero aún está desconectado del repositorio principal (el repositorio principal tendrá diferentes ‘ conjuntos de cambios ‘ de todos y cada uno de los repositorios de desarrolladores individuales), por lo que para comunicarse con él, emita un solicite al repositorio principal y envíe su código de repositorio local al repositorio principal. Obtener el nuevo cambio de un repositorio se llama “tirar ” y fusionar el ‘conjunto de cambios’ de su repositorio local se llama “ empujar ”.
No sigue la forma de comunicar o fusionar el código directamente con el repositorio principal después de realizar cambios. En primer lugar, confirma todos los cambios en su propio servidor o repositorio y luego el ‘conjunto de cambios’ se fusionará con el repositorio principal.
A continuación se muestra el diagrama para comprender mejor la diferencia entre estos dos:
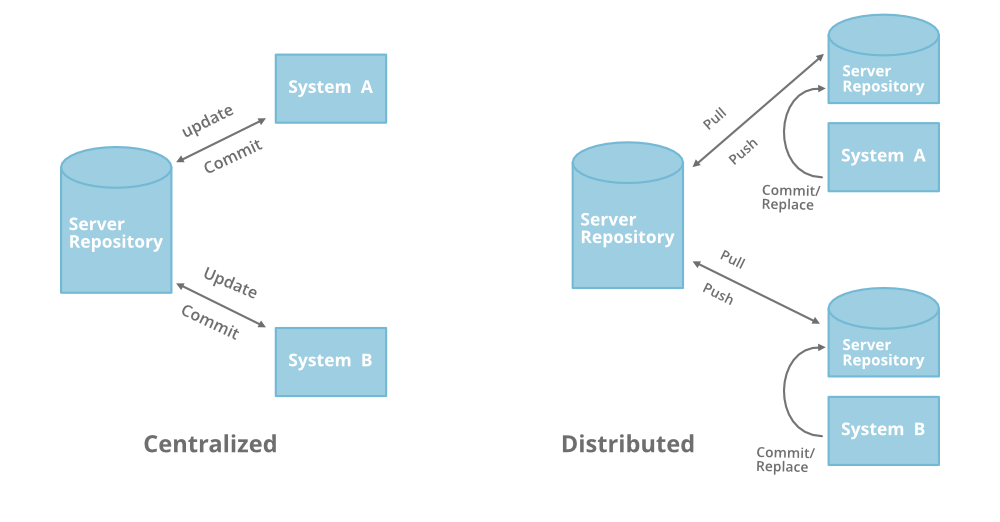
Diferencia básica con pros y contras
- El control de versiones centralizado es más fácil de aprender que el distribuido. Si es un principiante, tendrá que recordar todos los comandos para todas las operaciones en DVCS y trabajar en DVCS puede resultar confuso al principio. CVCS es fácil de aprender y fácil de configurar.
- DVCS tiene la mayor ventaja de que le permite trabajar sin conexión y brinda flexibilidad. Tiene todo el historial del código en su propio disco duro, por lo que todos los cambios los realizará en su propio servidor o en su propio repositorio que no requiere una conexión a Internet, pero esto no es en el caso de CVCS.
- DVCS es más rápido que CVCS porque no necesita comunicarse con el servidor remoto para todos y cada uno de los comandos. Usted hace todo localmente, lo que le brinda el beneficio de trabajar más rápido que CVCS.
- Trabajar en ramas es fácil en DVCS. Cada desarrollador tiene un historial completo del código en DVCS, por lo que los desarrolladores pueden compartir sus cambios antes de fusionar todos los conjuntos de cambios en el servidor remoto. En CVCS es difícil y lleva mucho tiempo trabajar en sucursales porque requiere comunicarse directamente con el servidor.
- Si el proyecto tiene una larga historia o el proyecto contiene archivos binarios grandes, en ese caso, descargar todo el proyecto en DVCS puede tomar más tiempo y espacio de lo normal, mientras que en CVCS solo necesita obtener unas pocas líneas de código porque no No es necesario guardar el historial completo o el proyecto completo en su propio servidor, por lo que no se necesita espacio adicional.
- Si el servidor principal falla o falla en DVCS, aún puede obtener la copia de seguridad o el historial completo del código de su repositorio o servidor local donde ya se guardó la revisión completa del código. Este no es el caso de CVCS, solo hay un único servidor remoto que tiene un historial de código completo.
- Los conflictos de combinación con el código de otro desarrollador son menores en DVCS. Porque cada desarrollador trabaja en su propio código. Los conflictos de combinación son más en CVCS en comparación con DVCS.
- En DVCS, a veces los desarrolladores aprovechan la ventaja de tener todo el historial del código y pueden trabajar durante demasiado tiempo de forma aislada, lo que no es bueno. Esto no es en el caso de CVCS.
Conclusión: veamos la popularidad de DVCS y CVCS en todo el mundo.

Fuente de la imagen: Tendencias de Google
De Google Trends y todos los puntos anteriores, está claro que DVCS tiene más ventajas y es más popular que CVCS, pero si tenemos que hablar sobre elegir un control de versión, entonces también depende de cuál te sea más conveniente aprender como Un principiante. Puede elegir cualquiera de ellos, pero DVCS brinda más beneficios una vez que sigue el flujo de usar sus comandos.
Publicación traducida automáticamente
Artículo escrito por anuupadhyay y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA