Aquí vamos a ver cómo recuperar registros únicos (distintos) de una tabla de base de datos de Microsoft SQL Server sin usar la cláusula DISTINCT.
Vamos a crear una tabla de empleados en una base de datos llamada «geeks».
Creando base de datos:
CREATE DATABASE geeks;
Usando la base de datos:
USE geeks;
Tenemos la siguiente tabla dup_table en nuestra base de datos geeks :
CREATE TABLE dup_table( dup_id int, dup_name varchar(20));
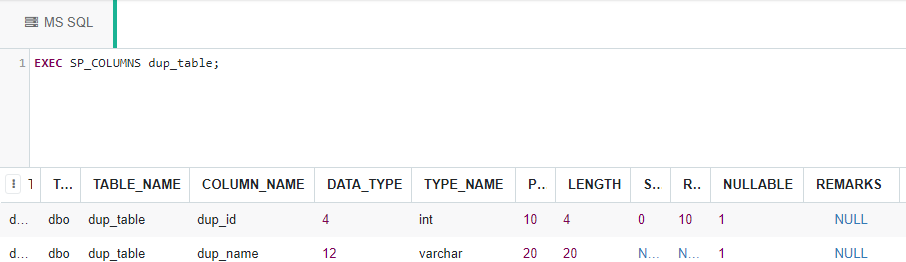
Para ver el esquema de la tabla, use el siguiente comando:
EXEC SP_COLUMNS dup_table;
Agregar valores en la tabla dup_table :
Use la siguiente consulta para agregar registros a la tabla:
INSERT INTO dup_table VALUES (1, 'yogesh'), (2, 'ashish'), (3, 'ajit'), (4, 'vishal'), (3, 'ajit'), (2, 'ashish'), (1, 'yogesh');
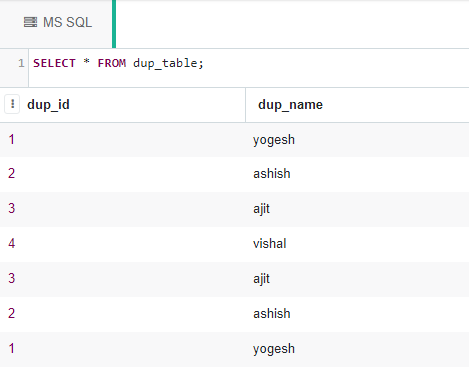
Ahora recuperaremos todos los datos de la tabla dup_table :
SELECT * FROM dup_table;
Ahora recuperemos filas distintas sin usar la cláusula DISTINCT.
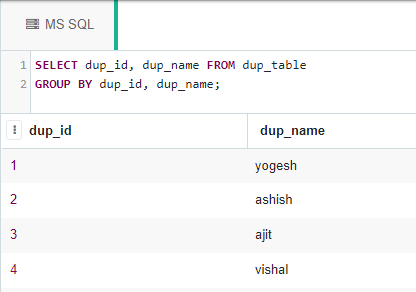
Mediante el uso de la cláusula GROUP BY:
La cláusula GROUP BY se puede usar para consultar filas distintas en una tabla:
SELECT dup_id, dup_name FROM dup_table GROUP BY dup_id, dup_name;
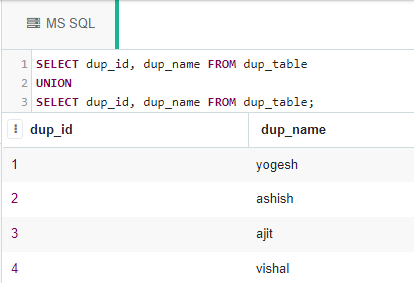
Mediante el uso de un operador conjunto UNION:
El operador set UNION también se puede usar para consultar filas distintas en una tabla:
SELECT dup_id, dup_name FROM dup_table UNION SELECT dup_id, dup_name FROM dup_table;
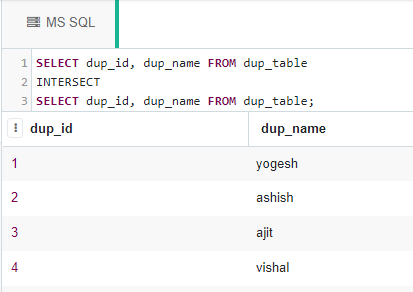
Al usar el operador set INTERSECT:
El operador INTERSECT se puede usar para consultar filas distintas en una tabla:
SELECT dup_id, dup_name FROM dup_table INTERSECT SELECT dup_id, dup_name FROM dup_table;
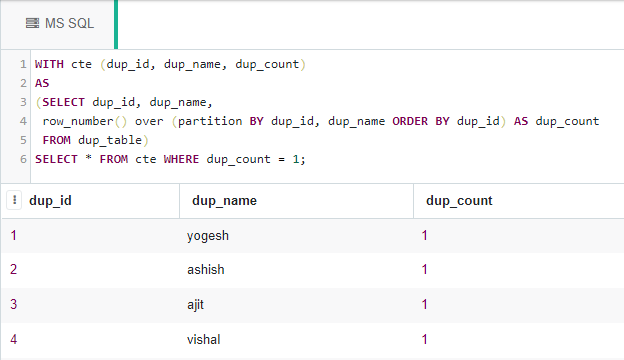
Mediante el uso de la función CTE & row_number():
CTE significa Expresiones de tabla comunes. También se puede usar para consultar filas distintas en una tabla con la función row_number() como se muestra a continuación:
WITH cte (dup_id, dup_name, dup_count) AS (SELECT dup_id, dup_name, row_number() over (partition BY dup_id, dup_name ORDER BY dup_id) AS dup_count FROM dup_table) SELECT * FROM cte WHERE dup_count = 1;