En este artículo, vamos a escribir un script de python para llenar varias columnas en su lugar en Python usando la biblioteca pandas. Un marco de datos es una estructura de datos 2D que se puede almacenar en formatos CSV, Excel, .dB, SQL. Usaremos Pandas Library of python para completar los valores faltantes en Data Frame.
Entendamos esto con la implementación:
Primero creando un conjunto de datos con pandas
Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan,
np.nan, 4,
2, np.nan,
np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Printing The dataframe
display(dataframe)
Producción:
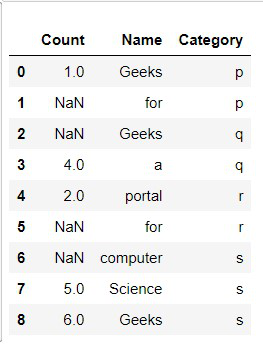
Ejemplo 1: llenar los valores de las columnas que faltan con valores fijos:
Podemos usar la función fillna() para imputar los valores faltantes de un marco de datos a cada columna definida por un diccionario de valores. La limitación de este método es que solo podemos usar valores constantes para completar.
Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Creating a constant value for column Count
constant_values = {'Count': 10}
dataframe = dataframe.fillna(value = constant_values)
# Printing the dataframe
display(dataframe)
Producción:
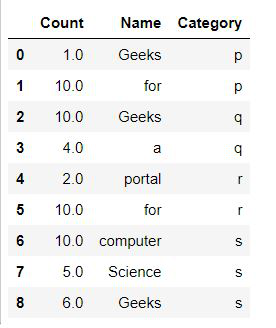
Ejemplo 2: llenar los valores de las columnas que faltan con la mean():
En este método, los valores se definen mediante un método llamado mean() que descubre la media de los valores existentes de la columna dada y luego imputa los valores medios en cada uno de los valores faltantes (NaN).
Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Filling Count column with mean of Count column
dataframe.fillna(dataframe['Count'].mean(), inplace = True)
# Printing the Dataframe
display(dataframe)
Producción:
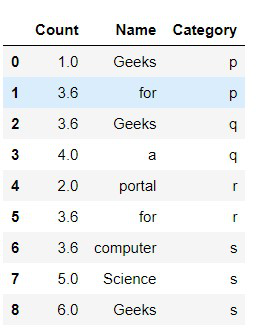
Ejemplo 3: Rellenar los valores de columna que faltan con mode().
La moda es el valor que aparece con mayor frecuencia en un conjunto de valores de datos. Si X es una variable aleatoria discreta, la moda es el valor x en el que la función de masa de probabilidad toma su valor máximo. En otras palabras, es el valor que es más probable que se muestree.
Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan,
1, 2, np.nan,np.nan,
5, 1],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Using Mode() function to impute the values using fillna
dataframe.fillna(dataframe['Count'].mode()[0], inplace = True)
# Printing the Dataframe
display(dataframe)
Producción:
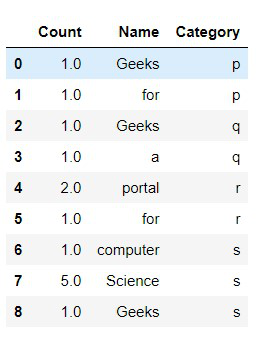
.