1. Modelo de datos
jerárquicos: el modelo de datos jerárquicos es el tipo de modelo de datos más antiguo. Fue desarrollado por IBM en 1968. Organiza los datos en una estructura similar a un árbol. El modelo jerárquico consiste en lo siguiente:
- Contiene Nodes que están conectados por ramas.
- El Node superior se llama Node raíz.
- Si aparecen varios Nodes en el nivel superior, estos pueden llamarse segmentos raíz.
- Cada Node tiene exactamente un padre.
- Un padre puede tener muchos hijos.
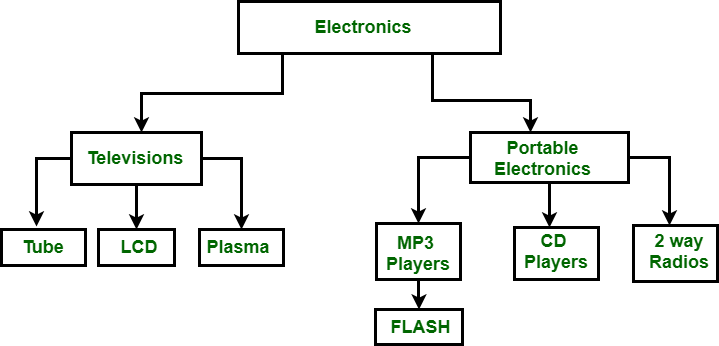
En la figura anterior, Electrónica es el Node raíz que tiene dos hijos, es decir, Televisores y Electrónica portátil. Estos dos tienen más hijos para los que actúan como padres. Por ejemplo: La televisión tiene hijos como Tubo, LCD y Plasma, para estos tres Televisión actúan como padres. Sigue una relación de uno a muchos.
2. Modelo
de datos relacionales: el modelo de datos relacionales fue desarrollado por EF Codd en 1970. No hay enlaces físicos como en el modelo de datos jerárquicos. Las siguientes son propiedades del modelo de datos relacionales:
- Los datos se representan únicamente en forma de tabla.
- Se trata sólo de datos, no de estructura física.
- Proporciona información sobre metadatos.
- En la intersección de la fila y la columna, solo habrá un valor para la tupla.
- Proporciona una manera de manejar las consultas con facilidad.
Diferencia entre el modelo de datos jerárquico y relacional:
| Modelo de datos jerárquicos |
Modelo de datos relacionales |
|---|---|
| En este modelo, se utiliza el método de jerarquía de datos para almacenar. Es el método más antiguo. | Es el modelo de base de datos más flexible y eficiente. Es la base de datos más utilizada en la actualidad. |
| Implementa 1:1 y 1:n. | Además de 1:1 y 1:n, también implementa relaciones de muchos a muchos. |
| Para organizar los registros, utiliza una estructura de árbol. | Para organizar registros, utiliza table. |
| Más posibilidades de complejidad. | No hay posibilidad de complejidad. |
| No hay una función de consulta declarativa. En los tiempos actuales se están modelando usando NoSQL | Proporciona facilidad de consulta declarativa usando SQL. |
| Los registros están vinculados con la ayuda de punteros. | Los registros están vinculados con la ayuda de filas y columnas. |
| La anomalía de inserción sale en este modelo, es decir, el Node secundario no se puede insertar sin el Node principal. | No hay anomalía de inserción. |
| Existe una anomalía de eliminación en este modelo, es decir, es difícil eliminar el Node principal. | No hay ninguna anomalía de borrado. |
| Se utiliza para acceder a datos que son complejos y asimétricos. | Se utiliza para acceder a datos que son complejos y simétricos. |
| Este modelo carece de independencia de datos. | Este modelo proporciona independencia de datos. |
| Este diseño se utiliza en los tiempos modernos para un acceso más rápido a los datos. Esto se obtiene mediante compensaciones, es decir, renunciando a la redundancia donde los niveles (de padres a hijos) son relativamente menores. | Debido a que las uniones de relaciones de muchos a muchos toman un alto costo en la búsqueda con consultas de múltiples parámetros |
| Actualmente este modelo se está utilizando en carritos de compra y buscadores. Hay herramientas que pueden emular una base de datos jerárquica, por ejemplo, Mangodb, firebase | La mayoría del software tradicional utiliza una base de datos relacional común, por ejemplo, Oracle dB, MS sql server, IBM DB2 |
Publicación traducida automáticamente
Artículo escrito por itskawal2000 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA