El algoritmo de programación de disco SCAN de período fijo (FSCAN) se enfoca principalmente en manejar una alta variación en el tiempo de búsqueda más corto primero (SSTF) . El algoritmo SCAN también se propone para manejar la situación mencionada anteriormente, pero el uso del algoritmo SCAN provoca una gran demora al manejar las requests que se encuentran en los extremos del disco. El algoritmo FSCAN determina cómo se moverá el cabezal de lectura y escritura del disco para manejar el problema del manejo de la alta variación de SSTF.
¿Cómo funciona?
FSCAN hace uso de dos colas, una de las colas almacena requests r/w antiguas y la otra cola almacena requests r/w nuevas. Cuando se manejan requests antiguas, solo se procesan las requests nuevas. Las variaciones del algoritmo FSCAN también pueden consistir en N colas, lo que a su vez hará que el tiempo de respuesta sea más rápido.
¿Cómo maneja el tema de la “varianza alta en SSTF”?
FSCAN aborda el problema mencionado anteriormente al «congelar» la cola una vez que comienza el escaneo, las requests que llegan después de que comienza el escaneo se procesan en el siguiente escaneo.
Análisis de rendimiento:
citando el análisis teórico, se puede ver que SCAN da como resultado un tiempo de respuesta promedio más bajo que FSCAN y un tiempo de respuesta promedio más alto que el tiempo de búsqueda más corto primero (SSTF). El algoritmo FSCAN tiene un buen rendimiento debido al alto rendimiento y al bajo tiempo de respuesta promedio. FSCAN elimina el problema del aplazamiento indefinido.
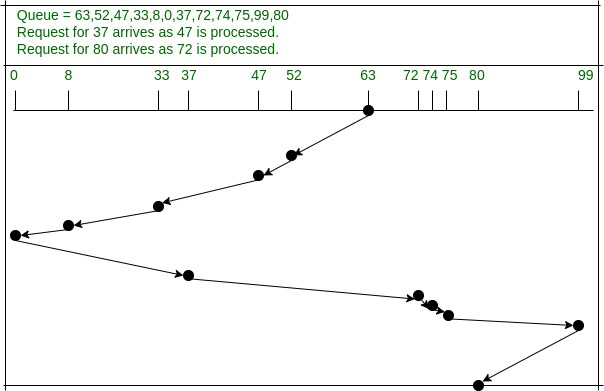
Ejemplo: cómo se procesan las requests
Publicación traducida automáticamente
Artículo escrito por Cyberfreak y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA