En un sistema de gestión de bases de datos, cuando queremos recuperar un dato en particular, se vuelve muy ineficiente buscar todos los valores del índice y llegar a los datos deseados. En esta situación, la técnica Hashing entra en escena.
Hashing es una técnica eficiente para buscar directamente la ubicación de los datos deseados en el disco sin utilizar la estructura de índice. Los datos se almacenan en los bloques de datos cuya dirección se genera mediante el uso de la función hash. La ubicación de la memoria donde se almacenan estos registros se denomina bloque de datos o depósito de datos.
Prerequisite - Hashing Data Structure
Organización del archivo hash:
- Depósito de datos: los depósitos de datos son las ubicaciones de memoria donde se almacenan los registros. Estos cubos también se consideran Unidad de almacenamiento .
- Función hash: la función hash es una función de mapeo que asigna todo el conjunto de claves de búsqueda a la dirección de registro real. En general, la función hash utiliza la clave principal para generar el índice hash: la dirección del bloque de datos. La función hash puede ser una función matemática simple para cualquier función matemática compleja.
- Índice hash : el prefijo de un valor hash completo se toma como un índice hash. Cada índice hash tiene un valor de profundidad para indicar cuántos bits se utilizan para calcular una función hash. Estos bits pueden abordar 2n cubos. ¿Cuándo se consumen todos estos bits? luego, el valor de profundidad se incrementa linealmente y se asignan el doble de cubos.
Hashing estático:
En el hashing estático, cuando se proporciona un valor de clave de búsqueda, la función hash siempre calcula la misma dirección. Por ejemplo, si queremos generar una dirección para STUDENT_ID = 104 usando la función hash mod (5), siempre da como resultado la misma dirección de depósito 4. No habrá ningún cambio en la dirección del depósito aquí. Por lo tanto, una cantidad de cubos de datos en la memoria para este hashing estático permanece constante en todo momento.
Operaciones:
- Inserción: cuando se inserta un nuevo registro en la tabla, la función hash h genera una dirección de depósito para el nuevo registro en función de su clave hash K. Dirección de depósito = h(K)
- Búsqueda: cuando es necesario buscar un registro, se utiliza la misma función hash para recuperar la dirección del depósito del registro. Por ejemplo, si queremos recuperar el registro completo para el ID 104, y si la función hash es mod (5) en ese ID, la dirección del depósito generada sería 4. Luego iremos directamente a la dirección 4 y recuperaremos el registro completo. para ID 104. Aquí ID actúa como una clave hash.
- Eliminación: si queremos eliminar un registro, al usar la función hash, primero buscaremos el registro que se supone que debe eliminarse. Luego eliminaremos los registros de esa dirección en la memoria.
- Actualización : primero se busca el registro de datos que debe actualizarse mediante la función hash y luego se actualiza el registro de datos.
Ahora, si queremos insertar algunos registros nuevos en el archivo, pero la dirección del depósito de datos generada por la función hash no está vacía o los datos ya existen en esa dirección. Esto se convierte en una situación crítica a manejar. Esta situación en el hashing estático se denomina desbordamiento del depósito . ¿Cómo insertaremos datos en este caso? Hay varios métodos proporcionados para superar esta situación. Algunos métodos comúnmente utilizados se discuten a continuación:
- Hashing abierto: en el método hash abierto, el siguiente bloque de datos disponible se usa para ingresar el nuevo registro, en lugar de sobrescribir el anterior. Este método también se llama sondeo lineal. Por ejemplo, D3 es un nuevo registro que debe insertarse, la función hash genera la dirección como 105. Pero ya está lleno. Entonces, el sistema busca el siguiente depósito de datos disponible, 123, y le asigna D3.

- Hashing cerrado: en el método hash cerrado, se asigna un nuevo depósito de datos con la misma dirección y se vincula después del depósito de datos completo. Este método también se conoce como enstringmiento de desbordamiento. Por ejemplo, tenemos que insertar un nuevo registro D3 en las tablas. La función hash estática genera la dirección del depósito de datos como 105. Pero este depósito está lleno para almacenar los nuevos datos. En este caso, se agrega un nuevo depósito de datos al final del depósito de datos 105 y se vincula a él. Luego, el nuevo registro D3 se inserta en el nuevo cubo.

- Sondeo cuadrático: el sondeo cuadrático es muy similar al hashing abierto o al sondeo lineal. Aquí, la única diferencia entre el balde viejo y el nuevo es lineal. La función cuadrática se utiliza para determinar la nueva dirección del depósito.
- Double Hashing: Double Hashing es otro método similar al sondeo lineal. Aquí la diferencia se fija como en el sondeo lineal, pero esta diferencia fija se calcula utilizando otra función hash. Es por eso que el nombre es doble hashing.
Hashing dinámico –
El inconveniente del hashing estático es que no se expande ni se reduce dinámicamente a medida que crece o se reduce el tamaño de la base de datos. En el hashing dinámico, los depósitos de datos crecen o se reducen (se agregan o eliminan dinámicamente) a medida que aumentan o disminuyen los registros. El hashing dinámico también se conoce como hash extendido. En el hash dinámico, la función hash está hecha para producir una gran cantidad de valores. Por ejemplo, hay tres registros de datos D1, D2 y D3. La función hash genera tres direcciones 1001, 0101 y 1010 respectivamente. Este método de almacenamiento considera solo una parte de esta dirección, especialmente solo el primer bit para almacenar los datos. Entonces intenta cargar tres de ellos en la dirección 0 y 1.
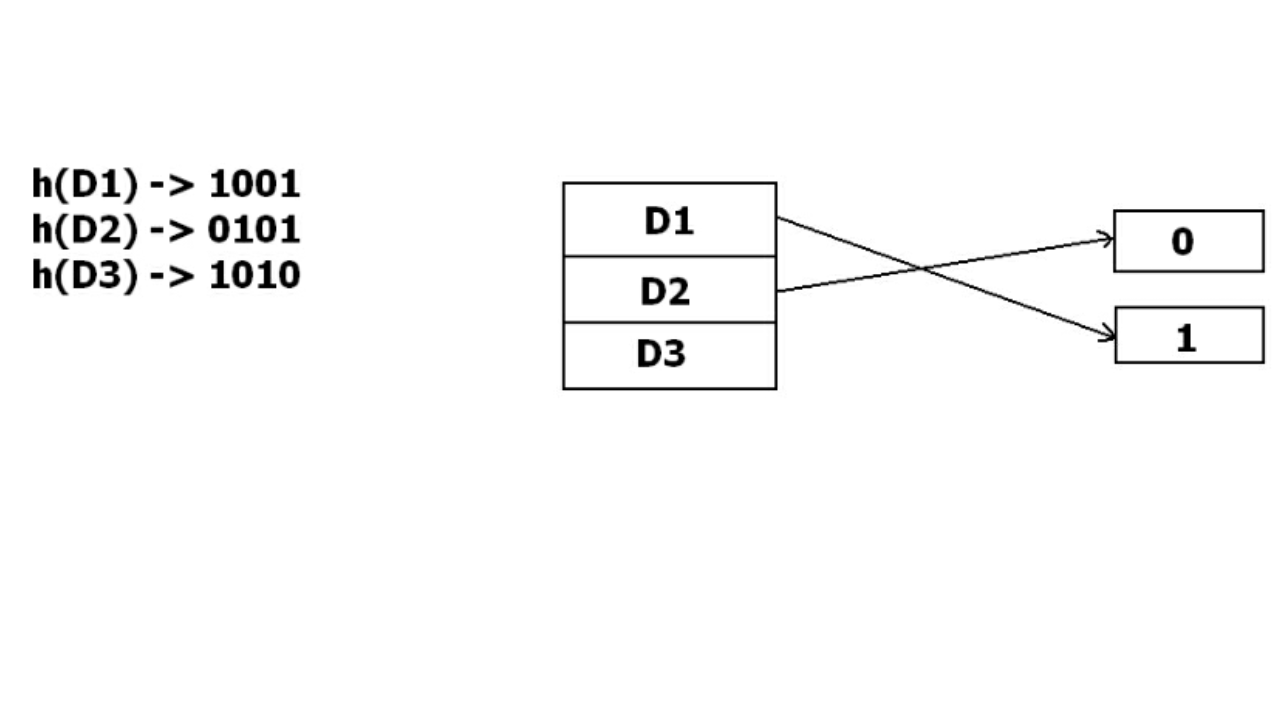
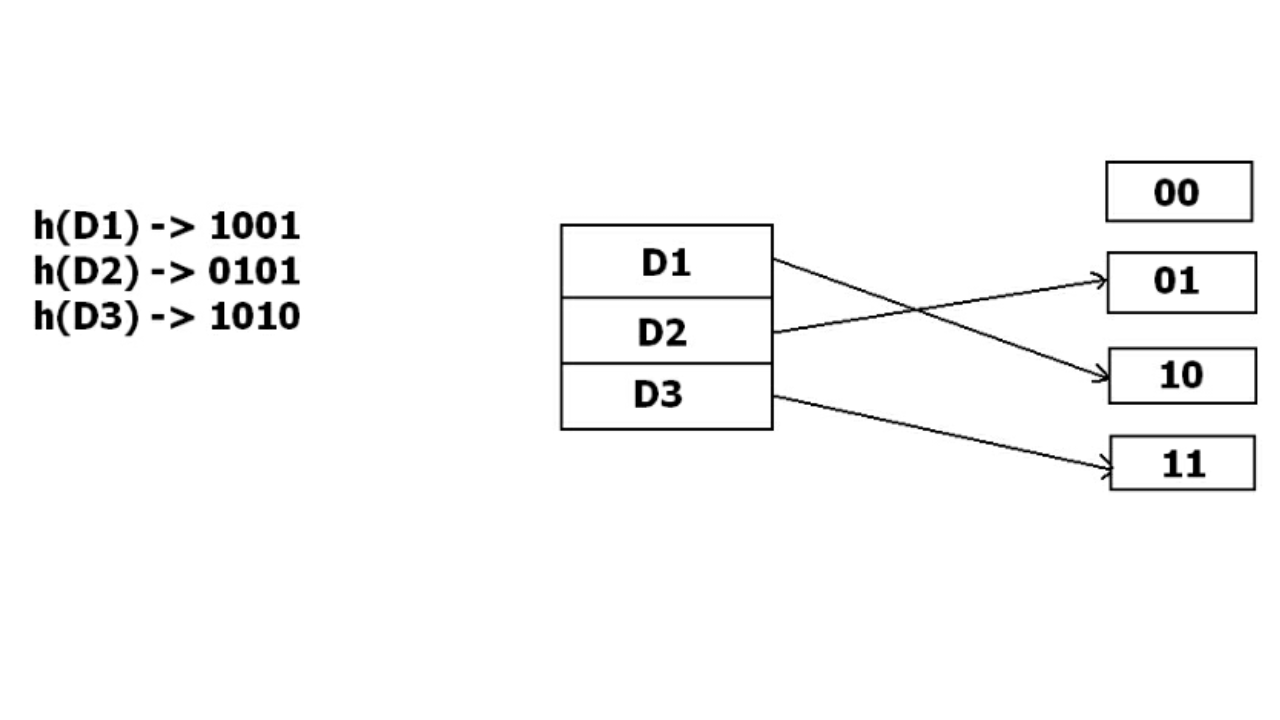
Pero el problema es que no queda ninguna dirección de depósito para D3. El cubo tiene que crecer dinámicamente para acomodar D3. Entonces cambia la dirección con 2 bits en lugar de 1 bit, y luego actualiza los datos existentes para tener una dirección de 2 bits. Luego trata de acomodar D3.
Publicación traducida automáticamente
Artículo escrito por Smitha Dinesh Semwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA