Dados dos árboles cada uno de N Nodes. Quitar un borde del árbol divide el árbol en dos subconjuntos.
Encuentre el número máximo total de aristas distintas (e1, e2): e1 del primer árbol y e2 del segundo árbol de modo que divida ambos árboles en subconjuntos con los mismos Nodes.
Ejemplos:
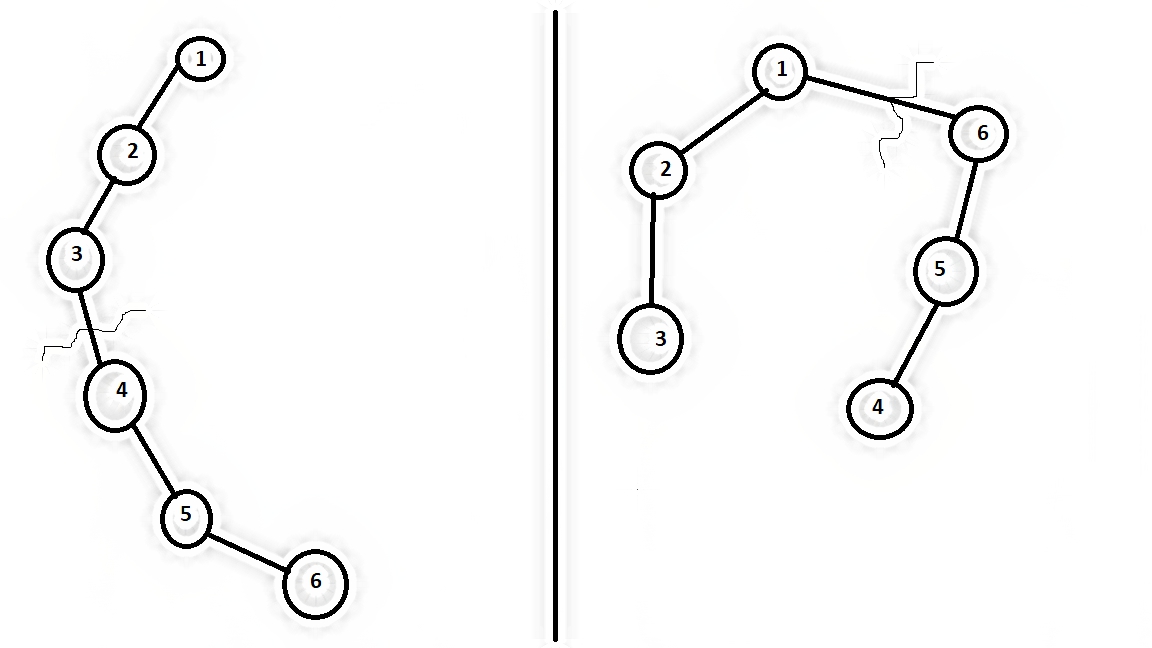
Entrada : Igual que la figura anterior N = 6
Árbol 1: {(1, 2), (2, 3), (3, 4), (4, 5), (5, 6)}
Árbol 2:{(1 , 2), (2, 3), (1, 6), (6, 5), (5, 4)}
Salida: 1
Podemos eliminar el borde 3-4 en el primer gráfico y el borde 1-6 en el segundo grafico.
Los subconjuntos serán {1, 2, 3} y {4, 5, 6}.
Entrada: N = 4
Árbol 1: {(1, 2), (1, 3), (1, 4)}
Árbol 2: {(1, 2), (2, 4), (1, 3)}
Salida : 2
Podemos seleccionar una arista 1-3 en el primer gráfico y 1-3 en el segundo gráfico.
Los subconjuntos serán {3} y {1, 2, 4} para ambos gráficos.
También podemos seleccionar una arista 1-4 en el primer gráfico y 2-4 en el segundo gráfico.
Los subconjuntos serán {4} y {1, 2, 3} para ambos gráficos
Acercarse :
- La idea es usar hashing en los árboles. Enraizaremos ambos árboles en el Node 1, luego asignaremos valores aleatorios a cada Node del árbol.
- Haremos un dfs en el árbol y, supongamos que estamos en el Node x, mantendremos una variable
subtree[x] que almacenará el valor hash de todos los Nodes en su subtree. - Una vez que hicimos los dos pasos anteriores, solo nos queda almacenar el valor de cada subárbol de Nodes para ambos árboles que obtenemos.
- Podemos usar un mapa desordenado para ello. El último paso es encontrar cuántos valores comunes de subtree[x] hay en ambos árboles.
- Aumente el recuento de bordes distintos en +1 por cada valor común de subtree[x] para ambos árboles.
A continuación se muestra la implementación del enfoque anterior:
CPP
// C++ implementation of the approach
#include <bits/stdc++.h>
using namespace std;
const long long p = 97, MAX = 300005;
// This function checks whether
// a node is leaf node or not.
bool leaf1(long long NODE, long long int deg1[])
{
if (deg1[NODE] == 1 and NODE != 1)
return true;
return false;
}
// This function calculates the Hash sum
// of all the children of a
// particular node for subtree 1
void dfs3(long long curr, long long par,
vector<long long int> tree1[],
long long int subtree1[], long long int deg1[],
long long int node[])
{
for (auto& child : tree1[curr]) {
if (child == par)
continue;
dfs3(child, curr, tree1, subtree1, deg1, node);
}
// If the node is leaf node then
// there is no child, so hash sum
// will be same as the
// hash value for the node.
if (leaf1(curr, deg1) == true) {
subtree1[curr] = node[curr];
return;
}
long long sum = 0;
// Else calculate hash sum of all the
// children of a particular node, this is done
// by iterating on all the children of a node.
for (auto& child : tree1[curr]) {
sum = sum + subtree1[child];
}
// store the hash value for
// all the subtree of current node
subtree1[curr] = node[curr] + sum;
return;
}
// This function checks whether
// a node is leaf node or not.
bool leaf2(long long NODE, long long int deg2[])
{
if (deg2[NODE] == 1 and NODE != 1)
return true;
return false;
}
// This function calculates the Hash
// sum of all the children of
// a particular node for subtree 2.
void dfs4(long long curr, long long par,
vector<long long int> tree2[],
long long int subtree2[], long long int deg2[],
long long int node[])
{
for (auto& child : tree2[curr]) {
if (child == par)
continue;
dfs4(child, curr, tree2, subtree2, deg2, node);
}
// If the node is leaf node then
// there is no child, so hash sum will be
// same as the hash value for the node.
if (leaf2(curr, deg2) == true) {
subtree2[curr] = node[curr];
return;
}
long long sum = 0;
// Else calculate hash sum of all
// the children of a particular node, this is
// done by iterating on all the children of a node.
for (auto& child : tree2[curr]) {
sum = sum + subtree2[child];
}
// store the hash value for
// all the subtree of current node
subtree2[curr] = node[curr] + sum;
}
// Calculates x^y in logN time.
long long exp(long long x, long long y)
{
if (y == 0)
return 1;
else if (y & 1)
return x * exp(x, y / 2) * exp(x, y / 2);
else
return exp(x, y / 2) * exp(x, y / 2);
}
// This function helps in building the tree
void Insertt(vector<long long int> tree1[],
vector<long long int> tree2[],
long long int deg1[], long long int deg2[])
{
// Building Tree 1
tree1[1].push_back(2);
tree1[2].push_back(1);
tree1[2].push_back(3);
tree1[3].push_back(2);
tree1[3].push_back(4);
tree1[4].push_back(3);
tree1[4].push_back(5);
tree1[5].push_back(4);
tree1[5].push_back(6);
tree1[6].push_back(5);
// Since 6 is a leaf node for tree 1
deg1[6] = 1;
// Building Tree 2
tree2[1].push_back(2);
tree2[2].push_back(1);
tree2[2].push_back(3);
tree2[3].push_back(2);
tree2[1].push_back(6);
tree2[6].push_back(1);
tree2[6].push_back(5);
tree2[5].push_back(6);
tree2[5].push_back(4);
tree2[4].push_back(5);
// since both 3 and 4 are leaf nodes of tree 2 .
deg2[3] = 1;
deg2[4] = 1;
}
// Function to make the hash values
void TakeHash(long long n, long long int node[])
{
// Take a very high prime
long long p = 97 * 13 * 19;
// Initialize random values to each node .
for (long long i = 1; i <= n; ++i) {
// A good random function is
// chosen for each node .
long long val = (rand() * rand() * rand())
+ rand() * rand() + rand();
node[i] = val * p * rand() + p * 13 * 19 * rand() * rand() * 101 * p;
p *= p;
p *= p;
}
}
// Function that returns the required answer
void solve(long long n, vector<long long int> tree1[],
vector<long long int> tree2[], long long int subtree1[],
long long int subtree2[], long long int deg1[],
long long int deg2[], long long int node[])
{
// Do dfs on both trees to
// get subtree[x] for each node.
dfs3(1, 0, tree1, subtree1, deg1, node);
dfs4(1, 0, tree2, subtree2, deg2, node);
// cnt_tree1 and cnt_tree2 is used
// to store the count of all
// the hashes of every node .
unordered_map<long long, long long>
cnt_tree1, cnt_tree2;
vector<long long> values;
for (long long i = 1; i <= n; ++i) {
long long value1 = subtree1[i];
long long value2 = subtree2[i];
// Store the subtree value of tree 1
// in a vector to compare it later
// with subtree value of tree 2.
values.push_back(value1);
// increment the count of hash
// value for a subtree of a node.
cnt_tree1[value1]++;
cnt_tree2[value2]++;
}
// Stores the sum of all the hash values
// of children for root node of subtree 1.
long long root_tree1 = subtree1[1];
long long root_tree2 = subtree2[1];
// Stores the sum of all the hash values
// of children for root node of subtree 1.
cnt_tree1[root_tree1] = 0;
cnt_tree2[root_tree2] = 0;
long long answer = 0;
for (auto& x : values) {
// Check if for a given hash value for
// tree 1 is there any hash value which
// matches to hash value of tree 2
// If yes, then its possible to divide
// the tree for this hash value
// into two equal subsets.
if (cnt_tree1[x] != 0 and cnt_tree2[x] != 0)
++answer;
}
cout << answer << endl;
}
// Driver Code
int main()
{
vector<long long int> tree1[MAX], tree2[MAX];
long long int node[MAX], deg1[MAX], deg2[MAX];
long long int subtree1[MAX], subtree2[MAX];
long long n = 6;
// To generate a good random function
srand(time(NULL));
Insertt(tree1, tree2, deg1, deg2);
TakeHash(n, node);
solve(n, tree1, tree2, subtree1, subtree2, deg1, deg2, node);
return 0;
}
1
Complejidad de tiempo : O(N)