Un marco de datos es una estructura tabular donde los datos se organizan en filas y columnas. A menudo, al trabajar con datos reales, se encuentran columnas que tienen elementos similares a listas. Similar a una lista significa que los elementos tienen una forma que se puede convertir fácilmente en una lista. En este artículo, veremos varios enfoques para convertir elementos de columna similares a listas en filas separadas.
Primero, creemos un marco de datos que usaremos para todos los enfoques.
Python
# import Pandas library
import pandas as pd
# create dataframe with a column (names) having list-like elements
data = {'id': [1, 2, 3],
'names': ["Tom,Rick,Hardy", "Ritu,Shalini,Anjana", "Ali,Amir"]}
df = pd.DataFrame(data)
print(df)
Producción:

Ahora, exploremos los enfoques paso a paso.
Método 1: Usar la función de fusión de Pandas
Primero, convierta cada string de nombres en una lista.
Python
# assign the names series to a variable with
# the same name and create a list column
df_melt = df.assign(names=df.names.str.split(","))
print(df_melt)
Producción:

Ahora, divida los valores de la lista de columnas de nombres (se crean columnas con valores de lista individuales).
Python
df_melt.names.apply(pd.Series)
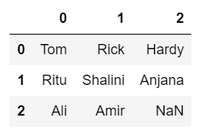
Combine las nuevas columnas con el resto del conjunto de datos.
Python
df_melt.names.apply(pd.Series) \ .merge(df_melt, right_index = True, left_index = True)
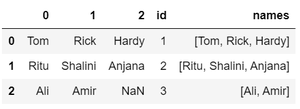
Suelte la columna de la lista de nombres antiguos y luego transforme las nuevas columnas en filas separadas usando la función de fusión.
Python
df_melt.names.apply(pd.Series) \ .merge(df_melt, right_index = True, left_index = True) \ .drop(["names"], axis = 1) \ .melt(id_vars = ['id'], value_name = "names")
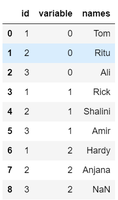
Ahora combine los pasos anteriores. Además, se ve una ‘variable’ de columna adicional que contiene los identificadores de las columnas numéricas. Esta columna se elimina y los valores vacíos se eliminan.
Python
df_melt = df.assign(names=df.names.str.split(","))
df_melt = df_melt.names.apply(pd.Series) \
.merge(df_melt, right_index=True, left_index=True) \
.drop(["names"], axis=1) \
.melt(id_vars=['id'], value_name="names") \
.drop("variable", axis=1) \
.dropna()
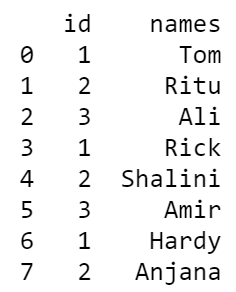
print(df_melt)
Producción:
Método 2: Usar la función de pila de Pandas
Convierta cada string de nombres en una lista y luego use la función p andas stack() para girar las columnas al índice.
Python
# convert names series into string using str method
# split the string on basis of comma delimiter
# convert the series into list using to_list method
# use stack to finally convert list elements to rows
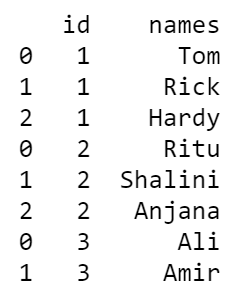
df_stack = pd.DataFrame(df.names.str.split(",").to_list(), index=df.id).stack()
df_stack = df_stack.reset_index(["id"])
df_stack.columns = ["id", "names"]
print(df_stack)
Producción:
Método 3: Uso de la función de explosión de Pandas
Convierta cada string de nombres en una lista y use la función Explotar() de Pandas para dividir la lista por cada elemento y crear una nueva fila para cada uno de ellos.
Python
# use explode to convert list elements to rows
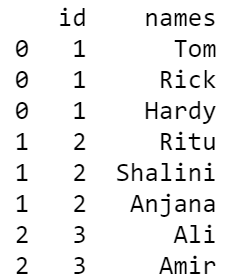
df_explode = df.assign(names=df.names.str.split(",")).explode('names')
print(df_explode)
Producción:
Publicación traducida automáticamente
Artículo escrito por akshisaxena y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA